Lojban wave lesson 中文版
Note: As a draft, the content is unstable and is subject to change. Proofreadings are welcome.
註:這還只是草稿,所以其內容可能會大幅更動。如果有發現紕漏,歡迎跟我(la melijaubi)說,謝謝。
la klaku著,過程中有許多邏輯語使用者的協助。基於la .kribacr.於2013年春天的成果。la melijaubi於2020年1~2月譯。
前言
這些課程是為了擴展原先la .kribacr.、la xablo所作,Marenz紀錄(對應此課程的第一到四章),在Google wave上開設的極佳課程。它解釋了一些邏輯語中,沒有被像是What is lojban?或邏輯語初學者教程等較古老的資料解釋到的新規則。
如果你對邏輯語不熟悉的話,我建議你在開始這套課程之前、以及閱讀這套課程時,都要聽你找得到的一切口說邏輯語的資源(閱讀、音樂、對話),讓你熟悉這個語言的聲音和詞彙。再來,如果可以的話,試著用邏輯語的口音說出你正在閱讀的東西。這樣可以大大幫助你的發音。
在閱讀這套課程時,你最好在章與章之間暫停一下,讓你可以內化你學到的東西。我在寫這套課程時,我試著從基礎到深入,並且避免前面章節沒有解釋過的詞彙或概念。一旦解釋了,之後的章節就不會迴避它們。我強烈建議讀者不要跳過不懂的地方,如果你有問題,或是對某個東西不清楚,你都可以去問邏輯語社群。他們會很樂意回答你的問題。
在這個課程中,邏輯語的內容會以粗體表示。之後,當邏輯語的專有詞彙用在中文句子裡時,它們不會被特別標示。練習的答案會用灰條蓋住。反白就能看到它的內容。
最後,在這個課程裡,我盡量使用邏輯語的詞彙表示語法結構:sumka'i表示「代sumti」,sumtcita表示「情態」,jufra表示「話語」。這是因為我覺得這些中文詞要嘛很任意,這樣只是徒增專有名詞的量,要嘛會誤導人,這樣的話它們比沒用還糟糕。無論是哪一種,反正這些詞只有在學邏輯語時會用到,所以實在是沒有理由給它們另外一套中文詞彙。
第一章:bridi, jufra, sumti, selbri
bridi是邏輯語最重要的概念,和中文的「命題」十分相似。bridi主張一些物體間有特定的關係,或是某物體具備某些特性。這就把它和jufra區別開來:任何邏輯語的話語,無論是不是bridi,都是jufra。bridi和jufra的差別就在於jufra不一定要宣稱任何東西,而bridi一定要。所以,一個bridi可能是真或偽,但並非所有的jufra都是如此。
舉些(中文的)例子。「莫札特是史上最偉大的音樂家」是bridi,因為它宣稱了一個物體「莫札特」具備性質「是史上最偉大的音樂家」,因此可以辨別真偽。另一方面,「啊!我的腳趾!」不是bridi,因為它沒有描述任何東西間的關係,因此沒有宣稱任何事。不過兩個都是jufra。
以下是中文的jufra,哪些是bridi?
- 我討厭你這樣做。
- 哇,那看起來好好吃!
- 啊,又來了。
- 不,我有三臺車。
- 八點十九分。
- 這個周六,對。
答案:1、2、4是bridi。其他的句子沒有指明任何關係或性質。
以邏輯語的術語來說,一個bridi由一個selbri以及一個或多個sumti組成。selbri是物體間的關係或特性,而sumti是關係指涉到的物體。不過以「物體」來描述sumti並不是那麼準確,因為sumti也可以指稱抽象事物,例如「戰爭的概念」。一個比較好的翻譯是把selbri翻譯為「主要動詞」,把sumti翻譯為「主詞、直接受詞、間接受詞之類的」,不過我們之後會看到這樣的翻譯也不是沒有問題的。
現在我們可以將第一項學習要點寫下來:
換句話說,bridi表示了一些sumti表現出由selbri指稱的關係或性質。
從以下中文的jufra中挑出sumti和selbri:
- 我會用我的車接我的女兒
答案:selbri(用...)接;sumti我、我的女兒、我的車
- 他只花了兩百歐元就從馬克那邊買了五件新襯衫!
答案:selbri(花...)(從...那邊)買了;sumti他、兩百歐元、馬克、五件新襯衫
因為這些概念在邏輯語中實在是太重要了,這裡有第三個例子:
- 至今EPA對二氧化硫的量沒有任何作為。
答案:selbri(對...)有作為;sumti:EPA、二氧化硫的量、沒有任何
現在可以來做一些邏輯語的bridi了。在這之前我們需要一些可以作為selbri的單字:
- dunda = x1 把 x2 給 x3 (沒有支付款項)
- pelxu = x1 是黃色的
- zdani = x1 是 x2 的家
在中文中,「給」、「黃色的」和「家」通常會被認為是動詞、形容詞和名詞。邏輯語沒有這樣的區別,dunda可以是「給」(動詞)、「是給予者」(名詞)、「給予著的」(形容詞)或是對應的副詞。它們都是selbri,並且具有一樣的用法。
我們還需要一些可以作為sumti的單字:
- mi = 「我」或「我們」:正在說話的人(們)
- ti = 「這個」:一個說話者指得到的鄰近物體/事件
- do = 「你」:說話的對象(們)
在selbri翻譯中的x1、x2、x3稱為sumti位。它們是讓sumti進入,形成bridi的地方。把一個sumti放入sumti位裡面就表示那個sumti適合那個位置。例如,dunda的第二個位置是被給出的物品,而第三個位置是收到東西的事物。值得注意的是,dunda的翻譯裡面有「把」。這是因為在中文裡面,被給出的物品需要用「把」來指明,不過在邏輯語中,被給出的物品就是dunda的第二個位置,所以當你把一個sumti放進dunda的第二個位置,它就是被給出的物品了,因此我們不需要對應「把」的詞。
要說出一個bridi,先說出x1的sumti,再來是selbri,再來是其他的sumti。
bridi的基本形式:(x1 sumti) (selbri) (x2 sumti) (x3 sumti) (x4 sumti) (x5 sumti) (以此類推)
這些位置是可以喬的,不過在這邊我們先專注在基本形式上。「我把這個給你」就是mi dunda ti do,三個sumti都在它們該在的地方。
那麼,「這是我的家」要怎麼說?
答案:ti zdani mi
再做一些例子讓sumti位的概念內化。
「你把這個給我」?
答案:do dunda ti mi
「ti pelxu」的中文?
答案:這是黃色的
習慣了就很簡單了,對吧?
不同的bridi之間會用.i隔開。.i是邏輯語中相當於句號的東西,只是它通常出現在bridi的前面而非後面。不過.i在第一個bridi前常會被省略。
- .i = 句子分隔符。將兩個jufra分開。
ti zdani mi .i ti pelxu = 「這是我的家。這是黃色的。」
在進到下一章之前,我建議你先休息七分鐘,讓你在這一章學到的知識內化。
第二章:FA、zo'e
大部分的selbri有一到五個sumti位,不過有些selbri有更多。以下是一個有四個sumti位的selbri:
- vecnu = x1 把 x2 賣給 x3 ,以 x4 的價格
如果我想說「我賣這個」,把x3和x4填起來就顯得多餘,畢竟我們並不想指明我賣給了誰、或是東西的價格。幸運的是,我們不必指明。我們可以用zo'e去填一個sumti位,其中zo'e表示那個sumti位的值並沒有被指明,因為它不重要或是可以輕易地從情境得知。
- zo'e = 某物;填滿一個sumti位,但不指明是什麼填滿的。
所以如果我要說「我賣給你」,我就說
- mi vecnu zo'e do zo'e
- 我把某物以某個價錢賣給你。
你要怎麼說「這是(某人的)家」?
答案:ti zdani zo'e
那麼「(某人)把這個給(某人)」?
答案:zo'e dunda ti zo'e
但是,只為了說有東西被賣了就講出三個zo'e很花時間,因此你不需要把bridi所有的zo'e講出來。如果你省略某個sumti不講,那個sumti就自動被解讀為zo'e。如果bridi的開頭是selbri,它的x1會視為被省略,因此就會變成zo'e。
試試看。邏輯語的「我賣」是什麼?
答案:mi vecnu
那「zdani mi」是什麼意思?
答案:某物是我的家。/我有家。
前面已經提到過了,bridi不一定要是{x1 sumti} {selbri} {x2 sumti} {x3 sumti} (以此類推)。事實上,你可以把selbri放在bridi的任何一個地方,只要不是在開頭就好。如果你把selbri放在開頭,bridi的x1會消失而變成zo'e。所以以下三個jufra是同一個bridi:
- mi dunda ti do
- mi ti dunda do
- mi ti do dunda
把selbri往後搬有時可以達到類似詩歌的效果。「你賣給你自己」可以是do do vecnu或是do vecnu do,不過前者聽起來比較順。另一種可能的情況是selbri很長,因此把selbri擺在bridi的最後,句子的架構會比較清楚。
還有其他方式可以移動bridi中sumti的位置。最簡單的就是用fa、fe、fi、fo、fu:
- fa = 表示接下來的sumti填的是x1
- fe = 表示接下來的sumti填的是x2
- fi = 表示接下來的sumti填的是x3
- fo = 表示接下來的sumti填的是x4
- fu = 表示接下來的sumti填的是x5
不難發現這五個詞的母音,就是邏輯語的母音,以字母順序排列。使用這些詞表示下一個sumti填的是x1、x2、x3、x4或x5。再下一個sumti就會填入下一個sumti位。舉個例子:
- dunda fa do fe ti do = 你把這個給你。fa表示x1,也就是給東西的人,就是你。fe是x2,就是被給出的東西。sumti位接著從fe開始繼續算,因此最後的sumti會填入x3,就是收到東西的事物。
將以下的句子翻譯為中文:
- mi vecnu fo ti fe do
答案:我把你以這個(價格)賣掉
- zdani fe ti
答案:這個東西有家。fe在這個句子裡沒有效果。
- vecnu zo'e mi ti fa do
答案:你把某物以這個(為價格)賣給我
第三章:tanru和lo
這一章會讓你熟悉tanru的概念。tanru是把一個selbri放在另一個selbri前面所形成的,前面的selbri會修飾後面的selbri。tanru本身也是selbri,所以它可以與其它的selbri或tanru結合,形成更複雜的tanru。所以zdani vecnu是tanru,而pelxu zdani vecnu也是。其中後者是由(一個tanru)pelxu zdani和(一個單字的brivla)vecnu組成的。要理解甚麼是tanru,考慮中文的「檸檬樹」。如果你不知道什麼是「檸檬樹」,但知道「檸檬」和「樹」分別是什麼意思,你還是無法推論出「檸檬樹」是什麼東西。也許是檸檬色的樹,也許是長得像檸檬的樹,也許是樹皮嘗起來像檸檬的樹。你只能確定它是一棵樹,而且它一定跟檸檬有某種關係。
tanru的概念就和剛剛提到的很像。你無法確切地得知zdani vecnu是什麼東西,但是它一定是某種vecnu,而且它會和zdani有某種關係。而且它跟zdani的關係可以是任意的。理論上來說,即使這個關係再怎麼隨機或硬要,它都是一個zdani vecnu。只是你指稱的一定要是vecnu,不然這個tanru就不適用了。你可以把zdani vecnu想成「家的賣家」,或是更精確,但聽起來沒那麼順的「家的種類的賣家」。tanru中sumti的結構由最右邊的selbri決定,也可以想成是左邊的selbri修飾右邊的selbri。
「真的嗎?」你懷疑地問了,「和左邊的selbri的關係再怎麼硬要都可以嗎?所以我可以把所有的賣家都叫做zdani vecnu,然後再凹出我覺得他跟zdani的關係是什麼嗎?」
呃,可以,只是那樣很機掰。或,至少,你會被認為是在故意誤導別人。在一般的狀況下,會用到tanru會是在左右selbri的關係很明顯的時候。
試試看翻譯以下的句子:ti pelxu zdani do
答案:「這是你黃色的房子。」我們並不知道房子怎樣是黃色的。有可能它的外牆是黃色的,只是我們不能肯定。
- mi vecnu dunda
答案:「我,以某種類似賣的方式,給。」什麼意思?我也沒概念。它絕對不會是賣,因為dunda的定義不允許任何型式的支付。它一定要只送不賣,但在某方面要像是賣。
來點不一樣的東西。如果我想說「我賣給一個德國人」呢?
- dotco = x1 是德國的/在 x2 方面展現德國文化
我不能說mi vecnu zo'e dotco,因為這樣會有兩個selbri,而這是不合法的。我可以說mi dotco vecnu,但是這樣實在是太模糊了--我可以賣得像一個德國人。同樣的道理,如果我想說「我是一個美國人的朋友」,我要怎麼說?
- pendo = x1 是 x2 的朋友
- merko = x1 是美國的/在 x2 方面展現美國文化
一樣,直覺反應可能會是mi pendo merko,但這樣會產生tanru,讓意思變成「我是像朋友的美國人」,而這是錯的。我們真正想要的是把merko轉換為一個sumti,這樣它才能用在pendo裡面。這個轉換可以用lo和ku達成。
- lo = 開始把selbri轉為sumti。把selbri的x1提取出來當sumti用。
- ku = 結束把selbri轉為sumti。
你把selbri放在這兩個字中間,它就會把可以放進該selbri的x1的東西抓出來並轉為sumti。
舉個例子,可以放進zdani的x1的東西是「某人的家」。所以lo zdani ku的意思就是「家」或是「某些人的某些家」。同理,如果我說一個東西是pelxu,它是黃色的。所以lo pelxu ku的意思就是「某黃色的東西」。
現在你有足夠的文法知識說出「我是一個美國人的朋友」了。怎麼說?
答案:mi pendo lo merko ku
ku不可或缺,而且有很好的理由。試試看翻譯「一個德國人把這賣給我」。
答案:lo dotco ku vecnu ti mi 如果你把ku拿掉,你得到的就不是bridi而是三個sumti。因為lo...ku吃不下bridi,ti必須要在sumti的外面,所以lo-結構遇到ti就只能關起來,形成三個sumti:lo dotco vecnu {ku}、ti和mi。
la nalvai註:前一個灰條中的說明有看到了,lo-結構其實不需要ku,只要它遇到它吃不下的語法結構,它就會自動關起來。例如,(就我們目前學到的部分而言)lo-結構裡面一定要是一個selbri,所以當它遇到selbri後面接著的sumti就會關起來,也就不需要ku了。如果selbri後面接著其他的語法結構,像是bridi或是第二個selbri,也是套用相同的道理。像是ku這類終止語法結構的詞稱為終止詞,詳細的省略規則在第八章會說明。
說到第二個selbri,在這裡先介紹一個詞,我們之後會一直看到:
- cu:表示接下來的是bridi的主要selbri。(這裡的用詞和你在第八章將會看到的不一樣,不過它們是等價的。)
可以發現lo ... ku的ku在cu之前可以省略,因為cu本身會開啟新的selbri,lo-結構吃不下第二個selbri,所以只好關起來。所以前一個句子可以改寫為lo dotco cu vecnu ti mi。雖然在這裡看起來好像一樣,但是cu強大得多(詳見第八章),而且它所傳達的意思(bridi的主要selbri)對於理解句子的結構非常有幫助。
許多有經驗的邏輯語使用者對於Wave Lessons在這邊如此強調ku的重要性感到不以為然,因為在絕大多數的使用情境下,ku其實是可以省略的。在這邊強調它只會讓初學者看到真的邏輯語句子(以及之後學習更複雜的文法結構)時感到困惑而已。從這裡到第八章為止,對於有終止詞的邏輯語句子,我都會給出一個省略終止詞的版本。
面對像是lo zdani ku pelxu = lo zdani cu pelxu 的句子都要特別小心。如果ku被省略了,轉換的過程就不會結束,於是整個東西就變成由zdani pelxu(一個tanru)被lo轉換成的sumti。
第四章:指示詞
另一個中文使用者可能會感到不習慣的概念是指示詞。指示詞是直接表示情緒的詞,而且它們很好用。它們具備了一種叫做「自由語法」的特性,這個特性讓它們可以出現在bridi中的幾乎任何地方而不會破壞bridi或是其他任何東西的結構。
在邏輯語的語法裡,指示詞作用在前一個詞上。如果前一個詞是開啟某個結構的詞(比如說.i或lo),那它就是作用在整個結構上。同理,如果指示詞的前面是結束某結構的詞,像是ku,那它也是作用在整個結構上。
以下是兩個指示詞,以便之後舉例:
- ui = 簡單情緒指示詞:開心-不開心
- za'a = 證據指示詞:我直接觀察到
注意在ui的定義裡列出了兩個情緒:開心和不開心。這個的意思是,ui的定義是開心,而它的否定表示的是不開心。在這裡使用「否定」這個詞可能沒那麼精確。技術上而言,ui的另一個定義是另一個結構,uinai。指示詞的第二個定義(有nai的形式)通常就真的是指示詞本身的否定。但有些時候不是。
- nai = 雜項否定:接在指示詞後面,將指示詞的意思轉為它的「否定」。
然後這裡有一些selbri,也沒為什麼:
- citka = x1 吃 x2
- plise = x1 是 x2 品種的蘋果
於是do citka lo plise ku ui的意思就是「你吃蘋果,耶!」(而且讓說話者開心的是蘋果,不是吃的動作或是是你在吃。);在do za'a citka lo plise ku這個句子裡,說話者直接觀察到,的確是「你」吃了蘋果,而不是別人。
la nalvai註:在do citka lo plise ku ui中,ui作用在lo plise ku這個sumti上,如果把ku省略的話,ui就會作用在plise這個(sumti內的)selbri上。在這個例子裡意思好像差不多,但是嚴格上來講這兩個的意思不一樣。舉另一個例子:
- po'o:言談指示詞:只有
- slari:x1對感知者x2是酸的
- mi citka lo slari ku po'o 我只吃酸的東西。(我不吃別的東西)
- mi citka lo slari po'o 我吃只是酸的東西。(我吃的東西沒有別的味道)
另外,可以把前句(不吃別的東西那句)的po'o移到lo的後方,如此一來意思不會改變,而且我們就可以放心地刪掉那一句話的ku了:mi citka lo slari ku po'o = mi citka lo po'o slari
如果指示詞出現在一個bridi的前面,它會被視為是作用在.i上面(無論.i有沒有被直接講出來),因此是作用在整個bridi上面。
- ui za'a do dunda lo plise ku mi = ui za'a do dunda lo plise mi = 耶,我觀察到你給我蘋果!
- mi vecnu ui nai lo zdani ku = mi vecnu ui nai lo zdani = 我賣(糟透了!)家。
試試看更多的例子。首先,這裡有更多的指示詞:
- .u'u = 簡單情緒指示詞:愧疚-不痛不癢(不自責)-無辜
- .oi = 複雜情緒指示詞:抱怨-愉悅
- iu = 雜項情緒指示詞:愛-恨
啊,有一個詞有三個定義!中間的可以用在指示詞後加cu'i來取得,它被認為是情緒的中間點。
- cu'i = 指示詞中間點:接在指示詞後面,將指示詞的意思轉為其對應情緒的「中間點」。
試試翻譯「我把某物給一個我愛的德國人」:
答案:mi dunda fi lo docto ku iu,把fi用zo'e替換也可以。
那麼「啊(愉悅),我吃一個黃蘋果」:
答案:.oi nai mi citka lo pelxu plise ku = .oi nai mi citka lo pelxu plise
為了講解之後的某項東西,再來一個指示詞:
- .ei = 複雜命題情緒指示詞:義務-自由
所以,「我得給出蘋果」是mi dunda .ei lo plise ku = mi dunda .ei lo plise,是吧?沒錯!但仔細想想這其實蠻奇怪的:為什麼我們看到的其他指示詞只表示我對bridi的看法,但這個卻可以直接改變bridi的意思?當我說「我得給出蘋果」時,我沒有說出蘋果有沒有真的被給出去,但如果我用ui,我就真的把蘋果給出去了,而且我對這件事很開心。這是怎麼一回事?
指示詞如何改變一個bridi為真的條件是可以爭論的主題。教科書上的解釋,而且這八成也不會再變了,是情緒指示詞可以分成兩類:純粹情緒詞和命題情緒詞。只有命題情緒詞會改變bridi的真值,而純粹情緒詞不會。如果想要使用命題情緒詞,卻不想改變bridi的真值,就把命題情緒詞和bridi用.i隔開。還有一個詞可以改變/保存bridi的真值:
- da'i = 言談指示詞:假設-現實
把da'i加進bridi裡會將意思轉為假設的情況,只使用命題情緒詞亦然。da'i nai會將意思轉為現實(正常情況),只使用純粹情緒詞亦然。
所以我有兩種方法可以說「我把蘋果給出去」(而且覺得自己不得不這麼做),哪兩種?
答案:mi dunda lo plise ku .i .ei = mi dunda lo plise .i .ei 以及 mi dunda da'i nai .ei lo plise ku = mi dunda da'i nai .ei lo plise
指示詞可以用dai表達他人的情緒。在平常談話中,情緒通常是聽者的,不過不一定要是。還有,因為詞的解釋裡有「同情」,有些邏輯語使用者會以為說話者也要有那個情緒。
- dai = 指示修飾詞:同情(不特定他人的情緒)
例子:.u'i .oi dai citka ti = 哈哈,這被吃了!這一定很痛!
- u'i = 簡單情緒指示詞:愉快-疲勞
.oi .u'i dai,一個常用的片語,是什麼意思?
答案:噢,很好玩是吧。
另一個:試試看翻譯:他很愧疚他把家賣了(時態不用說出來,而且「他」可以從情境得知)
答案:.u'u dai vecnu lo zdani ku = .u'u dai vecnu lo zdani
最後,指示詞的強度可以用一些詞來指明。這些詞可以擺在指示詞,或是指示詞後的nai或cu'i,後面。如果你把這些詞放在其他詞後面,例如放在selbri後面,它的意思沒有被定義,但通常會被認為是以某種方式加強或減弱該selbri。
- cai - 極端
- sai - 強
- 無 - 不表明(中等)
- ru'e - 弱
.u'i nai sai表現的是什麼情緒?
答案:十分疲勞
如果你感到有些不痛不癢,你要怎麼說?
答案:.u'u cu'i ru'e
第五章:SE
在我們進入更複雜結構的領域之前,你應該要認識另一種可以改變selbri中sumti的順序的方法。我們之後會看到,這個方法在構造描述型的sumti(就是有lo的那種)時很好用。
考慮「我吃一個禮物」,如果禮物是蘋果的話這蠻合理的。如果你要翻譯這個,最自然的想法就是先去找一個意思是「禮物」的selbri。但是如果仔細看dunda的定義,x1把x2給x3,會發現「禮物」是dunda的x2。
所以,那個句子不能寫為mi citka lo dunda ku = mi citka lo dunda,因為lo dunda ku = lo dunda是dunda的x1,也就是送禮物的人。除非我們是食人族,不然我們不會想這樣說。我們想做的事是把selbri的x2提取出來。
這個時候se就有用了。se做的事情是將selbri的x1、x2的位置互換,而se + selbri的這個結構本身也是一個selbri。用一個正常的句子試試看:
- ti se fanva mi = mi fanva ti
- 這個被我翻譯 = 我翻譯這個 (字面上是一樣的)
- fanva = x1 把 x2 翻譯成 x3 語,來源語言是 x4 語,翻出的結果是 x5
有se的bridi常常會被翻譯為被動句,因為這時x1是接受動作的事物。
se有一系列相關的詞。它們都是將不同的sumti與x1換位置。
- se - 交換 x1 和 x2
- te - 交換 x1 和 x3
- ve - 交換 x1 和 x4
- xe - 交換 x1 和 x5
s、t、v、x在邏輯語中是連續的子音。
所以,利用剛剛學到的,ti xe fanva ti是什麼意思?
答案:這是這個的翻譯(或fanva ti fu ti)
se還有相關的詞可以和fa相關的詞一起使用。如果你想要的話,你可以造出非常難以理解的句子:
- klama = x1 去 x2 ,從 x3 ,經過 x4 ,利用交通工具 x5
- fo lo zdani ku te klama fe do ti fa mi = fo lo zdani cu te klama fe do ti fa mi = mi te klama do ti lo zdani ku = mi te klama do ti lo zdani,然後因為te交換 x1 和 x3,= ti klama do mi lo zdani ku = ti klama do mi lo zdani = 這個從我,經過家,到你。
當然,沒有人會造出這種句子,除非他們存心使人搞混或是想測試其他人對邏輯語語法的理解。
所以我們可以說「我吃一個禮物」了。將dunda的sumti位換成讓禮物在x1,然後再用lo ... ku把新的x1提取出來就行了。所以你要怎麼說?
一個可能的答案:mi citka lo se dunda ku = mi citka lo se dunda
這顯示了se系列的詞的其中一個用途。
la nalvai註:本文中沒有提到,不過當se、te等詞出現在tanru裡時,它們會先和緊鄰的selbri結合,之後再和tanru的其他部份結合。所以se citka dunda的位置結構和dunda相同--因為它的分群是[se citka] [dunda]!而citka se dunda的位置結構和se dunda相同。
第六章:抽象
到目前為止,我們都是一次處理一個句子。然而要表達一些更複雜的事情,常常會需要子句。幸運的是,在邏輯語中,形成子句的方法比預期的簡單。
我們以一個例子來闡述:
- 我很開心你是我的朋友。
在這個句子裡,主要的bridi是「我很開心…」,而次要的bridi是「你是我的朋友」。其中,「開心」對應的selbri是gleki。
- gleki = x1 對 x2 (狀態/事件)感到開心
我們可以看到x2必須是狀態或事件。這很合理,畢竟一個人沒辦法對一件東西感到開心,一定要對那件東西的狀態。但是!只有bridi可以表示狀態或事件,而只有sumti可以填進gleki的x2裡!
你應該也猜到了,我們有一個解方。su'u ... kei,與lo ... ku很類似,只是它是將bridi轉為selbri。 la nalvai註:kei跟ku一樣是可省略的終止詞。
- su'u = x1 是{bridi}的 x2 方面的抽象
- kei = 結束抽象
例子:
- melbi su'u dansu kei = melbi su'u dansu
- 美麗的跳舞
- melbi = x1 對 x2 而言很美麗
- dansu = x1 隨伴奏/音樂/旋律 x2 跳舞
由bridi轉化來的selbri並沒有那麼好用。不過,因為su'u BRIDI kei是selbri,它可以用lo ... ku轉化為sumti。
我們現在可以說出「我很開心你是我的朋友」了。試試看!
- pendo = x1 是 x2 的朋友
答案:mi gleki lo su'u do pendo mi kei ku = mi gleki lo su'u do pendo mi
只是su'u ... kei沒有那麼常用。人們比較喜換用更精確的nu ... kei以及du'u ... kei。它們的用法一樣,只是意思稍有不同。nu ... kei會將中間的bridi視為是事件或狀態,而du'u ... kei將之視為抽象的bridi,表示想法、意見或事實。以上的字(除了kei之外)都稱為抽象詞。抽象詞有很多,但常用的很少。su'u ... kei是通用的抽象詞,在任何狀況下都能用。
- nu = x1 是{bridi}的事件
- du'u = x1 是以 x2 (句子)表示的{bridi}的命題
用nu說說看「我很開心跟你說話」。
- tavla = x1 跟 x2 談 x3 ,使用語言 x4
答案:mi gleki lo nu tavla do kei ku = mi gleki lo nu tavla do (中文和邏輯語的句子都沒明講是誰在跟你說話)
其他重要的抽象詞包括ka...kei(性質/方面的抽象)、si'o...kei(概念/想法的抽象)、ni...kei(程度的抽象)。這些詞的意思很不好解釋,我們會在第二十九章時再說明。現在你還不需要它們。
有些抽象詞有不只一個sumti位。例如du'u:
- du'u = 抽象詞:x1 是以 x2 (句子)表示的{bridi}的命題
x1之外的sumti位很少會被用到,但是lo se du'u (bridi) kei ku有時會被用作間接引用:「我說了我收到了一隻狗」可以寫作mi cusku lo se du'u mi te dunda lo gerku ku kei ku = mi cusku lo se du'u mi te dunda lo gerku。
- cusku = x1 表達 x2 給 x3 ,傳播媒介 x4
- gerku = x1 是 x2 品種的狗
第七章:NOI
還有一種把bridi包在bridi內的方法:關係子句。就是給sumti更多說明的句子。在邏輯語,關係子句有兩種,在知道如何表達它們之前,我們先釐清這兩者的差異。這兩種關係子句稱為限定性及非限定性關係子句。舉個例子:
- 我兩公尺高的弟弟是政治家。
這句話有兩種理解方式。我有可能有好幾個弟弟,而我說他有兩公尺高來讓你知道我在說的是哪一個弟弟。也有可能我只有一個弟弟,而我說他有兩公尺高就只是多給你一些資訊而已。
在邏輯語中,這兩種理解方式是區別開來的--第一種理解方式是限定性的,因為它限定了我可能談論的主題範圍;第二種則是非限定性。中文沒有方法(除了情境)可以區別這兩種理解方式。在邏輯語中,限定性及非限定性關係子句分別由poi...ku'o及noi...ku'o表示。la nalvai註:ku'o是可省略的終止詞。
舉個邏輯語的例子,順便解釋我們在第五章時吃禮物是怎麼一回事:
- noi = 開啟非限定性關係子句(只能接在sumti後面)
- poi = 開啟限定性關係子句(只能接在sumti後面)
- ku'o = 結束關係子句
- mi citka lo se dunda ku poi plise ku'o = mi citka lo se dunda poi plise
- 我吃(某物)是蘋果的禮物。
la nalvai註:要說得非常非常嚴格的話,在某些情況下,poi和noi前的ku有沒有省略會影響sumti的意思。在什麼情況下、以及會有什麼影響超出本章範圍,我們在第十四章以及第二十二章,真的遇到時再談。目前只要知道在lo SELBRI ku poi/noi ...的結構裡,ku可以安心省略就可以了。因為本章的ku都可以省略而不影響意思,我在本章會將它們全部省略。
在這個例子裡,poi...ku'o接在lo se dunda ku後面,所以它是修飾禮物的。嚴格來講,關係子句並沒有講明甚麼是蘋果,但在情境明顯的情況下我們可以認定禮物就是蘋果。如果你想要非常確定的話,可以在關係子句中用ke'a來表示關係子句修飾的名詞。如果ke'a在關係子句中的x1,ke'a常會被省略。(sumka'i是邏輯語中的代名詞,以後會解釋)
- ke'a = sumka'i:代表關係子句修飾的名詞。
- ui mi citka lo se dunda ku poi ke'a plise ku'o = ui mi citka lo se dunda poi ke'a plise
- 耶,我吃是蘋果的禮物。
以下是另一個例子,用來闡明兩種關係子句的差異:
- lojbo = x1 在 x2 方面展現邏輯語文化/社群; x1 是邏輯語的
- mi noi lojbo ku'o fanva fo lo lojbo ku = mi noi lojbo cu fanva fo lo lojbo
- 展現邏輯語文化的我從邏輯語翻譯一些東西。
在這個例子裡,mi可能指涉的事物只有一個,而「我展現邏輯語文化」只是一個附帶的資訊:你不需要這個資訊也可以知道「我」是誰。因此用noi...ku'o比較好。
來看看你能不能翻譯這個:
「我和很帥/漂亮的男人調情。」
- nanmu = x1 是男人
- melbi = x1 對 x2 而言在 (ka) x3 方面很漂亮,以 x4 的標準
- cinjikca = x1 和 x2 調情,展現出 x3 的性取向,以 x4 的標準
答案:mi cinjikca lo nanmu ku poi (ke'a) melbi ku'o = mi cinjikca lo nanmu poi (ke'a) melbi
如果你想知道一些更技術層面的訊息,lo (selbri) ku常常被定義為zo'e noi ke'a (selbri) ku'o。
還有,你可以在不同關係子句間插入zi'e來讓兩個以上的關係子句去修飾同一個sumti。它的形式是「sumti+關係子句+zi'e+關係子句(+zi'e+關係子句…)」。以下是一個例子:
- penmi = x1 遇到 x2 在 x3 地點
- dasni = x1 穿著 x2 作為 x3 類型的服飾
- mi tavla lo nanmu ku poi do penmi ke'a ku'o zi'e noi dasni lo xunre ku ku'o = mi tavla lo nanmu poi do penmi ke'a zi'e noi dasni lo xunre
- 我跟你遇到的那個穿紅裝的人說話。
第八章:終止詞,以及如何省略它們
- je'u mi djica lo nu le merko poi tunba mi vau ku'o ku jimpe lo du'u mi na nelci lo nu ri darxi mi vau kei ku vau kei ku vau kei ku vau
- 我真的希望那個是我手足的美國人可以理解我不喜歡他打我。
la nalvai註:既然這一章是在解釋如何省略終止詞的,我在這裡就先不提供省略終止詞的版本了。
無論你是如何理解以上的句子(你應該無法理解,因為上面的句子有我們還沒遇到的字),有一件事很明顯:當我們學了越多邏輯語的構造,我們的句子就會有越多ku、kei、ku'o等沒有意義的詞。這些詞的功能都是結束某個構造,像是ku會把selbri轉為sumti。這種詞在中文叫做終止詞,在邏輯語叫做famyma'o。在以上的例子中,它們以底線標示。
註:以上句子的vau表示結束bridi。我們很快就會看到為什麼你從來沒看過它。
- vau = 終止詞:結束bridi。
大多數終止詞在邏輯語口語或寫作中會被省略。這樣做可以大幅減少說話的時間或是寫字的空間,但是在省略終止詞時必須特別注意。像是簡單的lo merko ku klama,把終止詞ku省略掉會產生lo merko klama,它是一個由merko klama這個tanru形成的sumti。於是它的意思就變成「美國的旅人」而非「美國人旅遊」了。因為刪錯終止詞會導致非常錯誤的結果,所以你在這之前都沒有遇到它。
省略終止詞的規則十分簡單,至少就理論上而言:一個終止詞可以被省略,若且唯若省略掉它不會影響到句子的文法結構。換句話說,文法結構會儘可能往右伸展,直到遇到它的中止詞或是遇到它吃不下的詞為止。
la nalvai註:「文法結構會儘可能往右伸展,直到遇到它的中止詞或是遇到它吃不下的詞為止」這句話是重點。只要熟悉各種文法結構裡面可以塞什麼,在聽說讀寫邏輯語句子的時候就可以很自然的掌握哪些文法結構會繼續下去、而哪些會自動關起來。事實上,許多有經驗的邏輯語使用者在使用邏輯語時,是依照「文法結構會儘可能往右伸展」為預設狀態運行的,只有在這樣不會產生他想要的意思時才會加上需要的終止詞,而不是如本文說的先想好所有的終止詞後再去想哪些可以省略。
另外,邏輯語在設計上本來就對省略終止詞很友善…你有沒有發現在有cu的幫助下,我們到目前為止看到所有的終止詞都可以省略?
幾乎所有在bridi最後的詞都可以無後顧之憂的被省略。有例外,但例外都很明顯,像是「結束引用」或是「結束bridi分群」。這就是為什麼你幾乎看不到vau--反正直接用.i開一個新的bridi就會把前面的bridi關起來了。不過,這個詞有一個用處:因為指示詞作用在前一個詞上,把它作用在終止詞上是將指示詞作用在整個結構上。所以用vau就可以將指示詞追加到整個bridi上。
- za'a do dunda lo zdani {ku} lo prenu {ku}... vau .i'e
- 我看到你把家給一個人…我認同!
- prenu = x1 是人; x1 有人格
現在我們知道刪去終止詞的原則了,我們就可以回到一開始的句子去把它的中止詞拿掉:
- je'u mi djica lo nu le merko poi tunba mi vau ku'o ku jimpe lo du'u mi na nelci lo nu ri darxi mi vau kei ku vau kei ku vau kei ku vau
第一個vau可以省略,因為下一個不是終止詞的字是jimpe,是一個selbri。既然一個bridi只能有一個selbri,vau就不需要了。既然jimpe是一個selbri,它也不能出現在關係子句裡面(一個子句只能有一個bridi,一個bridi只能有一個selbri),所以ku'o也能拿掉。同理,jimpe不能是le merko poi {...}中的第二個selbri,所以ku也可以省略。然後,在句子最後的那一串終止詞也可以拿掉,反正在開下一個bridi時,那些結構就全部都會被關起來了。
於是我們得到:
- je'u mi djica lo nu le merko poi tunba mi jimpe lo du'u mi na nelci lo nu ri darxi mi
沒有任何終止詞了!
當省略修飾詞時,最好讓自己熟悉cu。cu是一個可以讓你(邏輯語)的生活變得簡單許多的詞。它做的事是把它前面的sumti和它後面的selbri分隔開來。或者你也可以說它將下一個詞定義為selbri,然後把阻礙下一個詞成為selbri的結構都關起來,而且只關必須關的。
- cu = 可省略標記:將selbri和其前面的sumti分開,並允許它前面的終止詞被省略。
- prami = x1 愛 x2
- lo su'u do cusku lo se du'u do prami mi vau kei ku vau kei ku se djica mi
- = lo su'u do cusku lo se du'u do prami mi cu se djica mi
- 你說你愛我,被我渴望=我希望你說你愛我
註:cu不是終止詞,因為它不與特定結構相關。但它可以用來刪去其他的終止詞。
cu最厲害的地方就是它很容易直觀理解。它本身沒有意義,但是它藉著指出selbri讓邏輯語的句構變得清晰。在本章開頭,有暴力的美國手足的例子裡,在jimpe前面加上cu不會改變句子的任何意思,但會讓句子比較容易理解。
在接下來的幾個章節裡,cu在必要的時候會使用,而終止詞會儘可能地省略。省略的終止詞會以大括號括起來,像是底下的例子。翻譯看看!
- .a'o do noi ke'a lojbo .o'o dai {ku'o} cu jimpe lo du'u lo famyma'o {ku} cu vajni {vau} {kei} {ku} {vau}
- vajni = x1 對 x2 很重要,因為 x3
- jimpe = x1 了解 x2 (du'u抽象)對 x3 是真的
- .a'o = 簡單命題情緒指示詞:希望-絕望
- .o'a = 簡單命題情緒指示詞:驕傲-謙卑-羞恥
我說了甚麼?
答案:我希望你,驕傲的邏輯語使用者,了解終止詞很重要。
趣聞:許多省略終止詞很熟練的人省略的非常直覺,直覺到他常常需要被提醒了解終止詞對了解邏輯語的結構是多麼重要。所以在邏輯語IRC chatroom,每個星期二被定為「終止詞日」,大家在那一天都會試著寫出所有的中止詞(而且常常失敗),於是對話就變得非常冗長。
第九章:sumtcita
到目前為止我們已經可以駕馭我們手中的selbri了。但是,有定義的selbri數量有限,而在許多時候它給出的sumti位可能不是我們想要的。像是,如果我要說「我用電腦翻譯」呢?fanva並沒有一個sumti位來放翻譯的工具,因為這個資訊通常是不必要的。別擔心,這一章會教你如何在selbri中加入新的sumti位。
最基本增加sumti位的方法就是用fi'o SELBRI fe'u(對,另一個終止詞,fe'u。這個詞幾乎總是可以省略的,所以這應該是你最後一次看到它了。)
在這兩個詞之間會是一個selbri,而且就像是lo SELBRI ku一樣,fi'o SELBRI fe'u也會提取selbri的x1。但是,fi'o SELBRI fe'u會將selbri轉為承載selbri的x1的sumtcita(這個詞的意思是sumti標籤)。之後這個sumtcita會吃下一個sumti。你可以說sumtcita是將一個sumti位從一個selbri送進bridi裡面。
註:尤其是在比較古老的文本裡,有時sumtcita會被稱為tag或modal。不要裡那些怪里怪氣的名字,這裡教的是堂堂正正的邏輯語。
只看文字敘述可能有點抽象,舉個例子就能發現它實際上很簡單了:
- skami = x1 是作為 x2 用途的電腦
- pilno = x1 把 x2 作為工具作 x3
- mi fanva ti fi'o se pilno {fe'u} lo skami {ku} {vau} = 我用電腦翻譯這個
pilno的x2,也就是se pilno的x1,是表示「某人使用的工具」的位置。這個位置被fi'o SELBRI fe'u抓住,加進主要的selbri中,再由lo skami填入。sumtcita的概念有時會用以下的中文翻譯表達:「我翻譯這個,工具是電腦」
sumtcita只能吃一個sumti,而且一定是緊接下來的那一個。你也可以使用sumtcita而不在裡面放sumti。如果你要這麼做的話,你就把它放在selbri前面或是把它用ku關起來。這樣可以想成是在sumtcita裡面填了zo'e。
la nalvai註:當sumtcita出現在selbri的正前方時,它可以當作selbri的一部份。但是和se、te等詞不同,帶有sumtcita的selbri是不能作為tanru的組件的,所以sumtcita作為selbri的一部份就只能出現在selbri的最前方而已。
- zukte = x1 憑意志採取行動 x2 ,以達成目標 x3
- zarci = x1 是賣/交易 x2 ,由 x3 經營的市場/商店
- fi'o zukte {fe'u} ku lo prenu {ku} cu klama lo zarci {ku} {vau} = 一個人憑意志去商店
注意fi'o zukte {fe'u} ku中的ku。如果ku被省略了,sumtcita就會吃lo prenu {ku},而這不是我們想要的。
同樣的事情也能用不同的方式說:
- fi'o zukte {fe'u} zo'e lo prenu {ku} cu klama lo zarci {ku} {vau}
- lo prenu {ku} cu fi'o zukte fe'u klama lo zarci {ku} {vau}
句子的意思都一樣。
「mi jimpe fi lo skami fi'o se tavla {fe'u} mi」是什麼意思?
答案:我了解一些電腦,對我說
把sumtcita放到selbri的前面也會把sumtcita關起來,因為sumtcita只吃得下sumti而非selbri。這在下一課會變得很重要。
事實上,雖然在使用上很有彈性,fi'o並不常被使用。很常被使用的,是BAI。BAI是邏輯語中的一個詞類,它們本身就是sumtcita。例子有zu'e,zukte對應的BAI。文法上來說,zu'e和fi'o zukte fe'u是等價的。因此,以上的例子可以被簡化為:zu'e ku lo prenu {ku} cu klama lo zarci {ku} {vau}。邏輯語中大約有60個BAI,而且有些非常好用。而且,BAI也可以由se之類的詞來修飾,也就是說se zu'e等價於fi'o se zukte fe'u,又大幅增加了BAI的數量。
la nalvai註:有sumtcita的selbri當然也可以被lo...{ku}轉化為sumti:lo se pi'o fanva = 使用工具的譯者。
第十章:PU、FAhA、ZI、VA、ZEhA、VEhA
我們已經講了九章了,卻還沒有提到時態,這是多麼神奇的事啊!這是因為,和許多自然語言(像是許多印歐語)不一樣,邏輯語的時態是可有可無的。也就是mi citka lo cilra {ku}可以是「我吃起司」或「我吃了起司」或「我總是吃起司」或「待會我就會吃完起司了」。情境會告訴你哪個是正確的,所以在許多時候時態是可以被省略的。但是,我們有時還是會需要時態,所以現在我們在這邊。而且,邏輯語的時態有一個特別的地方:它把時間和空間視為相同的東西--說「我在很久之前工作」和「我在很遠的北方工作」在文法上是一樣的。
和其他語言一樣,邏輯語的時態應該是邏輯語中最困難的部分了。但是和其他語言不一樣的是,邏輯語的時態非常的規則而且合邏輯。所以別緊張,這裡不會有改變selbri形狀之類的怪事出現。
邏輯語的時態都是利用sumtcita表示,而我們剛好已經教過那個了。好啦,技術上而言,時態跟sumtcita有一點點差別,但這差別小得基本上可以忽略,所以我們之後才會講到它。在絕大多數方面它們和其他sumtcita都一樣:它們用ku結束,所以PU也是以ku結束的。
邏輯語有很多的時態sumtcita,我們從對中文使用者最熟悉的看起:la nalvai註:以下三個詞合稱PU。大寫字母表示cmavo的類別,我們第十三章慢慢談。
- pu = sumtcita:在{sumti}以前
- ca = sumtcita:與{sumti}同時
- ba = sumtcita:在{sumti}以後
它們的概念就和中文的「以前」、「現在」、「以後」很像。你可以爭論說在實際上而言,兩個點事件不可能完全同時發生,所以ca沒有用。不過ca其實有往過去及未來延伸一點點,所以它的意思是「差不多現在」。因為人類對時間的感知本來就沒有那麼精確,所以邏輯語的時態系統為此作了一些調適。
趣聞:之前有人建議將邏輯語的時態系統建立在相對論的基礎上。這個建議後來沒有被採納,因為它很違反常理,而且如果真的採納了,那你要學邏輯語之前就得先學相對論。
那麼,我要如何說「我在我來這裡之後表達這個(指著一張紙)」?
答案:mi cusku ti ba lo nu mi klama ti {vau} {kei} {ku} {vau}
通常在說話時,我們不需要指明一件事是在哪件事的過去發生。像是「我在過去給出電腦」,我們可以認定這件事是在「現在的過去」發生的,所以我們可以把sumtcita的sumti拿掉,因為它很明顯:
- pu ku mi dunda lo skami {ku} {vau} 或
- mi dunda lo skami {ku} pu {ku} {vau} 或更常見的
- mi pu {ku} dunda lo skami {ku} {vau}
如果sumtitca的sumti填的是zo'e,在絕大多數情況下它都是被理解為是說話者所在的時間地點(這在講到左右時尤其重要)。當在談論一件不是現在發生的事情時,有時時態的基準點會被視為是正在談論的事情。如果要確保所有的時態都是以說話者現在的時間地點為基準,可以使用nau,而且隨時都可以用。另一個字,ki,會把一個時態設為新的基準點,不過我們在很久以後才會遇到它。
- nau = 把時間及空間的基準點更新為說話者現在的時間和地點。
- gugde = x1 是由 x2 人民、 x3 土地構成的國家
注意mi pu {ku} klama lo merko gugde {ku} {vau},「我(過去)去美國」,並不意味著我現在已經沒有在去美國了,只意味著這件事在某過去時間點是對的,像是五分鐘前。
la nalvai註:注意:當bridi裡面有其他bridi(像是抽象或關係子句)時,外部bridi發生的時間/空間會成為內部bridi的時態基準點,所以在句子do pu cusku lo se du'u do ba klama中,我們不知道你說你來的時候是在過去還是未來--因為這件事是在「過去(外部bridi的時間)的未來」,所以它相對於現在的時間要視過去和未來是過去/未來多久而定。
如果要明確表示內部bridi相對於現在的時間呢?這時nau就派上用場了:do pu cusku lo se du'u do nau ba klama中,你說你來的時候一定是在(現在的)未來,因為內部bridi的時態基準點被nau拉回說話者所在的時空了。
前面提過了,表達空間和表達時間非常類似。比較前面的三個時間時態與底下的四個空間時態:la nalvai註:合稱FAhA。FAhA有很多,這裡只舉了四個而已。
- zu'a = sumtcita:在{sumti}左邊
- ca'u = sumtcita:在{sumti}前面
- ri'u = sumtcita:在{sumti}右邊
- bu'u = sumtcita:與{sumti}同地點(ca的空間的對應)
- .o'o = 複雜情緒指示詞:耐心-容忍-憤怒
.o'o nai ri'u ku lo prenu {ku} cu darxi lo gerku {ku} pu {ku} {vau}是什麼意思?
答案:「(憤怒!)(某物的,八成是我的)右邊(某事的)過去有人打狗」或「有人在我右邊打了狗了!」
如果一個bridi裡有許多時態sumtcita,規則是從左讀到右,把它想成一個假想的旅程。就是你從基準點(預設是說話者的時間和空間)開始,然後沿著sumtcita指示的方向走。
例子:
- mi pu {ku} ba {ku} jimpe fi lo lojbo famyma'o {ku} {vau}
- 在過去的某個時間點,我將了解邏輯語的終止詞。
- mi ba {ku} pu {ku} jimpe fi lo lojbo famyma'o {ku} {vau}
- 在未來的某個時間點,我有了解過邏輯語的終止詞。
因為我們沒有指明移動的距離,所以在前面的兩個例子裡,事件可能發現在(相對於現在的)過去或未來。
還有,如果同時有時間和空間的時態詞的話,時間時態詞要放在空間時態詞前面。
假設我們想要說在僅一分鐘前,有人打了一隻狗。zi、za、zu表示時間上的短、不指明(中)、長距離。注意這裡的母音:i、a、u。這個順序會一直出現,所以把它記下來,之後會比較輕鬆。這裡的「短」和「長」是隨情境而定的,而且很主觀:兩百年在生物演化上是很短的時間,但如果是等公車的話就非常長了。la nalvai註:合稱ZI。
- zi = sumtcita:在離{sumti}短距離的時間
- za = sumtcita:在離{sumti}不定(中)距離的時間
- zu = sumtcita:在離{sumti}長距離的時間
同理,空間上的短、不定(中)、長距離可以用vi、va、vu標示。la nalvai註:合稱VA。
- vi = sumtcita:在離{sumti}短距離的空間
- va = sumtcita:在離{sumti}不定(中)距離的空間
- vu = sumtcita:在離{sumti}長距離的空間
- gunka = x1 在 x2 為了 x3 目的工作
翻譯:ba {ku} za {ku} mi vu {ku} gunka {vau} la nalvai註:這裡za後面的ku其實不能省略,不然za會把mi吃掉,句子的意思就改變了。
答案:我在(不指明遠近的)未來會在很遠的地方工作。la nalvai註:這是不省略za後面的ku(ba za ku mi vu gunka)的意思。省略za後面的ku的話,ba za mi vu gunka的意思是「在我之後(不指明多久),有人在很遠的地方工作」
註:人們在用zi、za、zu的時候,幾乎都會加pu或ba在前面。這是因為他們的母語要求他們這樣把過去/未來說出來。如果你用邏輯語的思維來想的話,因為絕大多數時候情境會告訴你時間的方向,所以pu或ba是多餘的。
la nalvai註:有些人會將ZI或VA標註的sumti作為時間/空間的跨度:mi cliva ba zi lo cacra = 我一小時後就離開。
這不是CLL的用法,不過十分常見。至於為什麼嘛…我想大概是因為CLL的文法沒有提供好的方式來表達時間/空間的距離吧。CLL推薦用項集(「我不想在這課程中提到的糟糕東西。」--Wave Lessons本文第二十七章),不過它其實就是把一個sumtcita硬塞進另一個sumtcita的管轄範圍內(老實說不怎麼漂亮)。再說在常見的PU/FAhA + ZI/VA結構中,時間/空間的基準點已經有PU/FAhA表示了,所以沒什麼必要再讓ZI/VA內的sumti重複相同的功能。
在幾乎所有的情況下,ZI或VA內的sumti表示的是基準點還是跨度可以很輕易地用語意判斷,所以理解上是不會產生困難的。
要注意的是方向sumtcita和距離sumtcita的順序會影響意思。記得當許多時態詞串起來時,它們是被視為一個由左讀至右的假想旅途。於是pu zu是「很久以前」而zu pu是「離現在很遠的時間(可能是過去或未來)的過去」。在第一個例子裡,pu表示我們在過去,zu表示那是在很久之前。在第二個例子裡,zu表示我們從離現在很遠的某時間點開始,然後pu表示我們再從那個時間點往過去走。所以pu zu一定是在過去,而zu pu有可能在未來。這種時態詞的組合方式就是時態sumtcita和其他sumtcita的其中一項差異:其他sumtcita的意思並不會隨著bridi中其他的sumtcita而變化。
前面有簡單提過,前面的架構都是把bridi當成是時空上的點事件。但是在真實世界中,許多事件是出現在一段時間或空間的。在底下的好幾個段落,我們會學到怎麼表明時空上的區段。la nalvai註:以下六個詞中,z開頭的屬於ZEhA、v開頭的屬於VEhA。
- ze'i = sumtcita:具備{sumti}的短時間跨度
- ze'a = sumtcita:具備{sumti}的不定(中)時間跨度
- ze'u = sumtcita:具備{sumti}的長時間跨度
- ve'i = sumtcita:具備{sumti}的短空間跨度
- ve'a = sumtcita:具備{sumti}的不定(中)空間跨度
- ve'u = sumtcita:具備{sumti}的長空間跨度
我知道這是一次六個詞,不過記得母音的順序,還有z、v分別表示時間、空間應該會對記憶有幫助。
- .oi = 情緒指示詞:疼痛-愉悅
翻譯:.oi dai do ve'u {ku} klama lo dotco gugde {ku} ze'u {ku} {vau}
答案:你花很多時間經過一大段距離去德國,很度爛吧
ze'u這一系列的詞也可以和其他時態詞結合。ze'u等詞的規則是在它前面的時態詞標示的是事件的其中一端(相對於基準點)而它後面的時態詞標示的是事件另一端相對於前一端所在的時空。利用一些例子會比較好懂:
- .o'ocu'i do citka pu {ku} ze'u {ku} ba {ku} zu {ku} {vau}
- (忍耐)你在過去開始吃,然後吃了好一段時間,在開始的很久以後結束。
- 或「哼嗯,你吃了好一段時間啊。」
你也可以比較do ca {ku} ze'i {ku} pu {ku} klama {vau}和do pu {ku} ze'i {ku} ca {ku} klama {vau}。在第一個例子中,事件的一端在現在,而它向過去延伸一小段時間;而在第二個例子中,事件的一端在過去,而它延伸到相對於事件那一端的現在(也就是過去或未來一點點)。
- jmive = x1 在 x2 標準下是活的
ui mi pu {ku} zi {ku} ze'u {ku} jmive {vau}表達什麼?
答案:「耶,我從(或直到,但直到的意思不合)一下下前,活了好一段時間!」或「我很年輕,我還有很多時間可以活:)」
為了彰顯空間與時間時態的相似性,以下是用空間時態的例子:
- .u'e = 情緒指示詞:驚訝-平凡
.u'e za'a bu'u {ku} ve'u {ku} ca'u {ku} zdani {vau}是什麼意思?
答案:「(驚訝)(我觀察到)從這裡延伸到我前方很遠的是一個家」或「哇,前方的家好大!」
la nalvai註:ZEhA、VEhA其實還有第四個成員:ze'e、ve'e,表示無限的時間/空間跨度。單獨使用時,它們表示事件涵蓋整個時間軸/空間跨度,不過它們也可以跟其他時態詞結合表示更精確的意思:ze'e ba表示「直到永遠」。
在我們繼續很硬的時態系統之前,我建議你花個最少十分鐘去做一些輕鬆的事,讓你的腦袋休息,讓剛剛讀到的東西內化。你可以唱歌或是吃餅乾--只要你的腦袋可以休息就好。
第十一章:ZAhO
雖然我們不會在這一章把所有邏輯語的時態結構都講完,有另一種時態我覺得應該要在現在講。這種時態稱為「事件輪廓」,和我們之前見到的時態都不一樣。那我們就開始吧:
在使用前面講過的時態時,我們可以想像一條無限長的時間軸,然後我們將事件擺在時間軸上相對於「現在」的位置。使用事件輪廓時,我們把事件視為一個有階段的程序:有開始前的時間、開始的時間、正在進行的時間、結束的時間及結束後的時間。事件輪廓告訴我們的是,在其它時態詞指示的時間下,這個事件進行到哪裡了。首先我們需要一些時態詞:
- pu'o = sumtcita:bridi在{sumti}時還沒發生
- ca'o = sumtcita:bridi在{sumti}時正在進行
- ba'o = sumtcita:bridi在{sumti}時已經結束了
la nalvai註:特別注意:這裡對於ZAhO(事件輪廓)作為sumtitca的詮釋和CLL寫的不一樣。
因為我個人踩過這個坑,所以我覺得有必要在這裡把它解釋清楚:
首先,對於沒有吃進任何sumti的ZAhO(像是後面直接接著selbri或是直接被ku關起來的ZAhO),兩邊的詮釋是一樣的:mi pu'o citka在這裡和CLL的詮釋都是「我還沒吃」。
對於有吃進sumti的ZAhO,兩者的詮釋基本上是相反的:
- 在CLL的詮釋裡面,當ZAhO作為sumtcita時,ZAhO所表達的是它吃下的那個sumti(事件)的進程。此時ZAhO不再表示外部/主要bridi的進程,而是表示該bridi的時態基準點。也就是說,mi pu'o lo nu do viska cu citka會展開成mi ca lo nu do pu'o viska cu citka,「我在你還沒看時吃」。
- 在這裡的詮釋裡面,當ZAhO作為sumtcita時,ZAhO所表達的是外部/主要bridi的進程(和ZAhO裡面沒有sumti時一樣),而ZAhO裡面的sumti表達的就是該進程時的基準點而已(就是以下定義中的「在{sumti}時」)。也就是說,mi pu'o lo nu do viska cu citka會展開成mi ca lo nu do viska cu pu'o citka,「我在你看時還沒吃」。
用簡單一點的話說,ZAhO lo nu BRIDI kei會展開成:(注意展開後ZAhO ku相對於lo nu ... kei的位置)
- CLL的詮釋:ca lo nu ZAhO ku BRIDI kei
- 這裡的詮釋:ca lo nu BRIDI kei ZAhO ku
如果ZAhO後方的sumti不是抽象,一樣可以套用前面的原則:pu'o lo cabdei在CLL的詮釋是「在今天開始之前」,在這裡的詮釋是「在今天時還沒」。
至於哪一種比較常用?我在2020年問過邏輯語社群,當時他們的回答是大家都是用這裡的詮釋。不過在2025年時我看到有不少人是採用CLL的詮釋的,於是兩個詮釋都有用例:CLL詮釋用例此處詮釋用例1此處詮釋用例2
也就是說,如果遇到ZAhO後方接sumti的話,就要看哪一種詮釋得到的結果比較合理了;不然知道作者慣用的是哪一種詮釋也會有幫助。
事實上,ZAhO後面通常不會接sumti(我不確定這有多少是因為有兩種不同的詮釋方式使人們因為不希望產生誤解而刻意迴避在ZAhO後方接sumti),這時兩個的意思是一樣的。
這需要一些例子才好理解。ui mi pu'o {ku} se zdani {vau}是什麼意思?
答案:耶,我要有家了。
但,你問了,為何不直接說ui mi ba {ku} se zdani {vau},這樣還省一個音節?因為,在你說你未來有家時,你並沒有說你現在有沒有家。不過如果你用pu'o的話,你說的是你現在在「你有家」的這整個程序之前,所以就表示你現在還沒有家。
還有,mi ba {ku} se zdani {vau}和mi pu'o {ku} se zdani {vau}類似,ba'o和pu同理。為什麼它們看起來反了?因為事件輪廓是從事件去看現在,而其他時態是從現在去看事件。
事件輪廓常常比其他時態來的精確。把許多時態合併使用的話,可以達到更高的精確度:.a'o mi ba {ku} zi {ku} ba'o {ku} gunka {vau}「我希望我很快結束工作」。
在邏輯語,我們還會談論事件的自然終點。「自然」在這邊是一個很主觀的詞,而自然終點表示的是程序中應該結束的點。舉個例子,你可以說誤點的列車「往你這邊開」的程序已經過了它的自然終點;或是沒煮熟的菜在程序的自然終點來到之前就被吃了。這些例子的事件輪廓如下:
- za'o = sumtcita:事件輪廓:bridi在{sumti}時在自然終點之後而正在進行
- xa'o = sumtcita:事件輪廓:bridi在{sumti}時在自然起點之前而正在進行
- cidja = x1 是 x2 可食的食物
翻譯:.oi do citka za'o lo nu do ba'o {ku} u'e citka zo'e noi cidja do {vau} {ku'o} {vau} {kei} {ku}
答案:呃呃,你在你吃完(驚訝)食物後繼續吃!la nalvai註:這句話依CLL的詮釋說不太過去…因為ba'o citka是吃完的狀態,在時間軸上無限向後延伸(見下圖),那還有什麼自然終點可以超越呢?
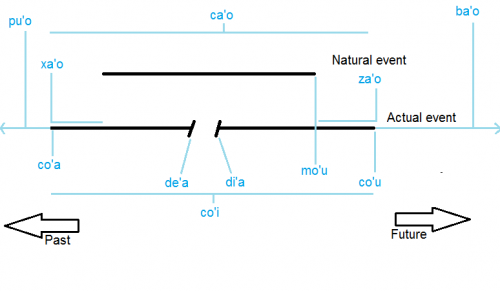
上圖:事件輪廓。在時間軸上方的時態詞表示會持續一段時間的階段,下方的時態詞表示像是點事件的階段。
前面講過的時態詞描述的都是會持續一段時間的階段(如圖:它們都在時間軸上方),不過許多事件輪廓描述類似點事件的階段,像是事件的開始。和ca或bu'u的情形一樣,它們也會像過去/未來延伸一點點,而不需要完全準確。
兩個最重要的點狀事件輪廓:
- co'a = sumtcita:事件輪廓:bridi在{sumti}時開始
- co'u = sumtcita:事件輪廓:bridi在{sumti}時結束
還有一個是程序的自然結束點,但它不一定在這時結束:
- mo'u = sumtcita:事件輪廓:bridi在{sumti}時達到自然終點
不過在大多數時候,程序會在它的自然終點結束,不然它就不是自然終點了。列車通常不會誤點,而人們通常會只吃能吃的食物。
因為程序可能被暫時打斷,這些點也有它們的事件輪廓:
- de'a = sumtcita:事件輪廓:bridi在{sumti}時暫停
- di'a = sumtcita:事件輪廓:bridi在{sumti}時回復
事實上,因為jundi的意思是「x1注意x2」,de'a jundi和di'a jundi常常被用來表示「馬上回來」和「我回來了」。你也可以只講事件輪廓,然後希望其他人可以懂。
最後,你可以用co'i將一整個事件從開始到結束視為一個點:
- penmi = x1 遇到 x2 在 x3 地點
- mi pu {ku} zi {ku} co'i {ku} penmi lo dotco prenu {ku} {vau}
- 一會兒前,我在我遇到德國人的時間點
第十二章:命令和問句
呼,剛剛兩大段很硬的邏輯語句法課可以讓腦袋好好的消化一下。尤其它跟中文這麼的不一樣。所以我們轉向一個比較輕鬆的主題:命令和問句。
在中文,命令是藉著把主詞拿掉形成的,那你怎麼知道我是在命令你,而不是在命令我自己或是表示其他人得做什麼事呢?因為中文了解命令一定是對著聽者,也就是「你」,所以主詞是不必要的。
在邏輯語中,省略的主語會變成zo'e,所以我們沒辦法這樣做。於是,我們用ko,就是do的命令型。在文法或bridi的角度而言,它和do是相同的,但是它多了一層語意上的功能,因為有ko的句子就一定是命令。「讓這個句子是對的」=ko!就像是在中文裡命令不需要主詞一樣,我們不需要ko之外的命令詞。
你要怎麼叫一個人去離你很遠的地方很久?(只用一個klama作為selbri)
答案:ko ve'u ze'u klama
(.i za'a dai a'o mi za co'u ciska lo famyma'o .i ko jimpe vau .ui) - 自己練習。
- ciska = x1 寫文字 x2 在 x3 上
邏輯語的問句非常簡單,有兩種:填填看和是非題。我們從是非題開始--它特別容易解決,因為它只會用到一個字,xu。
xu就像是指示詞一樣可以出現在任何地方,並作用在它的前一個字(或結構)。接下來,它將句子轉為一個問句,問這個句子是不是真的。如果要回答「是」,就重複那個bridi:
- xu ze'u zdani do .i ze'u zdani mi
不然你也可以只重複selbri,就是把sumti和時態都拿掉的bridi:zdani。
要回答「是」有更簡單的方法,就是使用brika'i,不過我們不會在這裡講到它。如果你要回答「否」,就回答bridi的否定形式。這個也是在之後才會講到,不過我們在那時會回到如何回答問題。
另一種問題是填填看。在這裡,你是將疑問詞用做空格,並希望它可以被一個結構填滿,使bridi變成正確的。疑問詞有好幾種,看你要問甚麼:
- ma = sumti問題
- mo = selbri問題
- xo = 數字問題
- cu'e = 時態問題
等族繁不及備載。如果你要問sumti,你就把疑問詞放到你要問的地方:do dunda ma mi-希望x2被正確的sumti填滿:「你把什麼給我?」sumtcita + ma的組合很有用:
- mu'i = sumtcita:受{sumti}的抽象驅使
- .oi do darxi mi mu'i ma
- 欸,你幹嘛打我?
來試試看下一個。這回,翻譯:
- ui dai do ca ze'u pu mo
答案:「你很開心,你直到現在的很長一段時間在做什麼?」技術上而言,它也可以是「最近如何?」,但是用ua nai li'a remna(嗯,人,很顯然的)來回答會顯得故意在煩人。
因為語調或句子的結構並不會顯示句子是不是問句,疑問詞最好不要漏掉。而且,因為人們通常會比較注意句子兩端的字,把句子的結構喬成讓疑問句在句子的一端通常是好主意。如果沒辦法的話,pau是一個表明句子是問句的指示詞。相對的,pau nai會將句子標示成反問。
既然我們現在在講問句,我們可以在現在提起kau,間接問句的標記。甚麼是間接問句?看例子就知道了:
- mi djuno lo du'u ma kau zdani do
- 我知道你的家是什麼。
- djuno = x1 知道 x2 對於 x3 是事實,藉著方法 x4
你可以把它想成問句ma zdani do的答案。比較罕見的是,你也可以將一個非疑問詞用kau標記,這時你也可以把它想成是問句的答案:mi jimpe lo du'u dunda ti kau do「我知道你被給了什麼,就是這個。」
第十三章:構詞和詞類
回到比較硬(而且比較有趣)的東西。
如果你還沒有的話,我強烈建議你去聽叫做Story Time with Uncle Robin的邏輯語錄音,或是聽人們在Mumble上講邏輯語,然後練習你的發音。對自己說邏輯語只有在發音沒那麼糟的時候才有用,而你很難單靠文字去學發音。所以,這一章的內容不是邏輯語的發音,雖然它很重要,而是邏輯語構詞的簡介。
什麼是構詞?就像句法是如何將單字組成句子一樣,構詞是如何將聲音組成單字。邏輯語是在不同詞類為基礎下運作的,而一個詞的詞類由其構詞決定。為了讓它變得很有系統,具備相似功能的詞通常會在相同的詞類裡,不過有時會有例外。
| 類別 | 意思 | 定義 | 通常功能 |
|---|---|---|---|
| 單字: | |||
| brivla | bridi詞 | 前五個(除了'之外的)字母包含子音叢。由母音結尾。 | 預設為selbri。一定有位置結構。 |
| gismu | 根詞 | 五個字母,形式為CVCCV或CCVCV | 一到五個位置結構,表達基本概念。 |
| lujvo | 複合詞,從lujvla「複雜的詞」衍生 | 最少六個字母,由rafsi串接而成,可能包含連接字母。 | 表達比gismu更複雜的概念。 |
| zi'evla | 自由詞 | 不符合gismu或lujvo定義的brivla | 表達如名字、位置、生物等獨特概念。 |
| cmevla | 名字詞 | 由停頓(句點)開始及結束。最後的聲音/字母是子音。 | 一定是名字或引用的內容。 |
| cmavo | 語法詞,從cmavla「小的詞」衍生 | 至多一個子音,子音一定在開頭。由母音結尾。 | 各種語法功能。 |
| 單字片段: | |||
| rafsi | 詞綴 | CCV, CVC, CV'V, -CVCCV, -CCVCV, CVCCy-, CCVCy- | 不單獨出現,但可以串起來形成lujvo。 |
cmevla很容易辨認,因為其開頭和結尾都是停頓,在寫作中以句點表示,而且最後一個字母是子音。cmevla有兩項功能:在前面接la的時候,它作為專有事物的名字(la會在下一章介紹),不然它可以做為引用的內容。前面提過,你可以將帶有重音的字母大寫來表示重音。cmevla的例子有:.io'AN.(約翰),.mat.(馬特)及.lutciMIN.(劉志民)。以母音結尾的名字需要在最後補上子音或將最後的母音拿掉:「安娜」要寫成.anas.或.an.。
brivla叫做bridi詞,它們預設是作為selbri,所以幾乎所有有位置結構的詞都是brivla。這同時也給了它們「實詞」的暱稱。如果不使用brivla的話,很難講出有用的東西,而且幾乎所有不是邏輯語語法的東西(以及許多邏輯語語法的東西)都是由brivla表示的。如表格所示,brivla分為以下三類:
gismu是邏輯語的根詞。gismu一共有約1450個,而且很少會加上新的。它們表示一些最基本的概念,像是「圓」、「朋友」、「樹」或「夢」。例子有zdani、pelxu和dunda。
lujvo由表示gismu的rafsi組合而成(詳見rafsi)。將rafsi組合在一起,字的意思就會變得明確。lujvo是由一個精妙的演算法做出來的,所以憑空生出一個lujvo是非常困難的,除非像是從se prami來的selpa'i,因為這種字只會有一種可能的意思。lujvo,一旦被製作,它的位置結構就會被定下來,然後它的意思就會被收錄在官方字典裡。例子有brivla(bridi-詞)、cinjikca(性+社交=調情)和cakcinki(殼+昆蟲=甲蟲)。
zi'evla由一個符合bridi的定義,但不符合lujvo或gismu的定義的詞形成的。它們通常表示一些很難以lujvo表示的概念,像是物種的名稱、國名或是某些文化才有的東西。例子有xanguke(南韓)、cidjrpitsa(披薩)或.angeli(天使)。
cmavo是只有一個或零個子音的小字。它們通常不會表示任何外在世界的東西,只會表示語言內部的結構。不過有例外,像是你可以爭論指示詞表現了多少語言的結構。另一個奇怪的例子是GOhA,它們表現得像是brivla。許多cmavo可以被寫在一起成為一個字,不過我們這邊不會這樣做。不過有些時候將一些功能上相關的cmavo串在一起可以使句子比較好閱讀。所以,uipuzuvukumi citka是合法的,而且會被理解為ui pu zu vu ku mi citka。像其他的邏輯與詞彙一樣,你應該(但不是在所有情況下都要)在開頭是母音的字前面加上句號。
形式是xVV、CV'VV或V'VV的cmavo是實驗性的,也就是沒有在語言的官方紀錄裡面的詞。這些詞是一些邏輯語使用者為了特定的需要而創造的。
rafsi不是邏輯語的「詞」,而且無法單獨出現。不過許多(大於一個)rafsi可以結合成lujvo。合成出來的東西必須要符合brivla的定義,所以lojban是不合法的,因為它以子音結尾,所以它會是cmevla;而ci'ekei是不合法的,因為它沒有子音叢,所以它會被理解為是兩個被寫在一起的cmavo。常常一個三、四個字母的字串會同時是cmavo和rafsi,只是因為cmavo和rafsi絕不會在同一個地方出現,它們不會被視為同音詞。所有的gismu都可以作為(字末的)rafsi,只要它前面有別的rafsi。gismu的前四個字母接上y也能作為rafsi,只要它後面有別的rafsi。母音y只能出現在lujvo或cmevla裡面。合法的rafsi形式有:CVV、CV'V、CCV、CVCCy-、CCVCy-、-CVCCV、-CCVCV。
你現在應該可以用所學的來回答以下問題了:
將底下的詞分類為cmevla(C)、gismu(g)、lujvo(l)、zi'evla(z)或cmavo(c):
A) jai; B) .irci; C) bostu; D) xelman; E) po'e; F) djisku; G) mumbl; H) .i'i; I) cu; J) plajva; K) danseke; L) .ertsa
答案:A-c; B-z; C-g; D-C; E-c; F-l; G-C; H-c; I-c; J-l; K-z; L-z。我將名字前後的句號省略,不然會太明顯。註:有些字,像是bostu,並不在字典裡,不過這沒有很重要。它還是gismu,只是是沒有定義的gismu。.ertsa同理。
第十四章:邏輯語sumti之一:LE和LA
如果你讀了並理解了到現在為止的所有內容,你對邏輯語的瞭解已經多到你學習以下東西的順序已經沒那麼重要了。所以,之後的課程會大致照著簡單的、對話中常用的主題在前面的順序。
目前你說話最大的限制就是你對於製作sumti的知識還很有限。目前,你只知道ti還有lo SELBRI,考慮到sumti在邏輯語是多麼的重要,你知道的是遠遠不夠的。這一章以及之後兩章都會是關於邏輯語的sumti的。現在我們先考慮描述型sumti,就是由像是lo的冠詞形成的。
冠詞在邏輯語中叫做gadri,而所有在這一章講到的冠詞都由ku結束,除了LA CMEVLA。我們會從介紹三個簡單的描述型sumti開始,然後發現它們其實沒有那麼簡單:
- lo = gadri:通用,將selbri轉為sumti。
- le = gadri:描述特定事物,將selbri轉為sumti。
- la = gadri:命名冠詞,將selbri或cmevla轉為sumti。
你已經知道什麼是lo了。lo創造一個適合selbri第一個位置的sumti。
這可以和描述特定事物的le做對比。當你說le gerku,你心中已經有一個或多個特定的事物,然後你用gerku去描述它,所以聽者可以知道你想的是什麼東西。所以le有兩個和lo不一樣的地方:首先,它不能作為泛稱,它一定要指稱特定的事物。第二,le gerku表示這個selbri只是用來協助說話者描述那個東西,無論那個東西是不是真的符合那個selbri。也許說話者想說的是鬣狗,但是對它們不熟悉,而覺得用「狗」去描述它就已經夠接近,聽者可以理解。不過在許多文本裡,「不一定要真的是」被過度強調了--畢竟如果要指稱一隻狗的話,「狗」通常會是最佳的描述方式。所以除非有什麼很好的例由,不然le gerku會被認為是指稱是lo gerku的東西。
在翻譯時,lo gerku可以翻成「那隻狗」、「那些狗」、「一隻狗」、「一些狗」或「一般的狗」,而le gerku可以翻成「那隻狗」或「那些狗」。le gerku更好的翻譯會是「『那』(隻/些)狗」。
第三個基本gadri是la,是一個命名gadri,也就是它會把selbri原先的意思拔掉,然後指稱名字是那個selbri的東西。如果我用中文稱呼一個叫做「無辜」的人的名字,我並不是用「無辜」來描述她,我也沒宣稱她是無辜的。我只是說在通常情況下,這個物體是由這個selbri或cmevla指稱的。注意la,還有由它衍生的gadri可以將cmevla轉為sumti,這是其他gadri辦不到的。還有:其它的文本並沒有提到名字可以是一個一般的selbri加上la。那些異端文本必須被燒掉:以selbri作為名稱是完全合法的,而且許多驕傲的邏輯語使用者都有selbri名字。
la比較奇怪一點,因為它一定是名字的開頭。和其他的gadri不一樣,任何可以被合文法地加到la或它相關的詞後方的都會被認為是名字的一部份。像是le mi gerku是「我的狗」,而la mi gerku是一個叫做「我的狗」的人或事物。
三個基本的gadri可以由三個gadri擴展,這三個新的gadri和前面的對應:
- loi = gadri:通用,由個體組合的群體
- lei = gadri:描述特定由個體組合的群體
- lai = gadri:由該名字的個體組合的群體
它們和一開始提到的三個冠詞一樣,不過有一個差別:它們表示的是由sumti組合而成的群體。群體是將許多個體為了方便表達而抽象出來。舉些例子:一個足球隊可以被描述為其成員的群體,或是一隻動物是細胞的群體。
- mivysle = x1 是 x2 有機體的細胞
- remna = x1 是人類
loi mivysle cu remna = 「細胞的群體是人」。一樣,沒有一個細胞是人。一個細胞具有非常少的人類特質,但是所有的細胞和在一起就成了人類。這個例子也顯示了loi之後的selbri是由群體中的個體滿足的,而非群體本身:一個人畢竟不是細胞。
一個由lei構造的群體,像是lei gerku,表示的是一個由特定個體組成的群體,而說話者會將群體中的成員指稱為le gerku。
需要注意的是,就算selbri是針對群體中的個體的,lo通常還是夠用。使用群體通常是在講到許多由個體組成的群體時才會需要。
- sruri = x1 將 x2 包圍,在 x3 方向/平面上
lo prenu cu sruri lo zdani = 「人們包圍家」。邏輯語的意思和中文的意思一樣:人們排列起來而把家包圍住,不一定要有個體自己把家包圍。
但如果我們就是要說群體中的個體都有獨自將家包圍呢?要確保一個selbri是分散在各體裡,我們需要lo、le或la再配上外量詞。量化詞會在第二十二章時談論到。
最後,還有兩個普遍化的gadri:
- lo'e = gadri:事實性的將selbri轉為sumti。sumti指的是lo {selbri}的原型。
- le'e = gadri:描述性的將selbri轉為sumti。sumti指的是le {selbri}描述上/認知上的原型。
la沒有與之對應的詞。
所以,「原型」是什麼意思?以lo'e tirxu為例,它是一個理想的、假想的大貓,然後它有所有最適合拿來代表大貓的特徵。這個特徵不包含「有條紋」,因為在大貓裡面,有許多種類都沒有條紋,像是獵豹或美洲豹。同理,人類的原型並不住在亞洲,即使有許多人住在亞洲。不過,如果有夠多人類具有某項特質,像是「可以說話」,我們就能說:
- kakne = x1 可以做 x2 ,在 x3 條件下
- lo'e remna cu kakne lo nu tavla = 「一個典型的人可以說話。」
同理,le'e就是說話者認定理想的事物。這不一定要是正確的,而且常常翻譯為「刻板印象」。這個詞在中文具有負面的意涵,不過在邏輯語沒有。事實上,每個人對於任何類別都會有一個刻板印象上的原型。換句話說,lo'e remna這個原型是lo remna中最好的例子,而le'e remna這個原型是le remna中最好的例子。
這八個gadri可以用以下的表格表示:
| 通用 | 群體 | 原型 | |
|---|---|---|---|
| 事實性 | lo | loi | lo'e |
| 描述性 | le | lei | le'e |
| 名字 | la | lai | 不存在 |
註:在之前,有一個詞xo'e作為通用的gadri。不過,gadri的定義和使用規則在2004年後期改變了,而現在在gadri的規則,又叫做xorlo,已經取代舊的規則了。現在,lo是通用的,而xo'e用在不特定數位(第十九章)。還有一系列gadri是用在表示集合的,不過在xorlo之後,它們已經非常少見了。
第十五章:邏輯語sumti之二:KOhA3、KOhA5、KOhA6
來看看如果我要翻譯「刻板印象上,會說邏輯語的人會和彼此談論他們會說的語言」時會發生什麼事:
- bangu = x1 是 x2 用來表達 x3 (抽象)的語言
- le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. cu tavla le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. lo bangu poi lo prenu poi ke'a tavla fo la .lojban. cu se bangu ke'a
我們可以看到這個邏輯與的句子比中文的長多了。這主要是因為第一個長的不得了的sumti在邏輯語裡重複了三遍,而中文可以用更有效率的「彼此」還有「他們」。如果邏輯語有這種機制不就太棒了嗎?
結果邏極語的確有,多令人驚訝呀!邏輯語有一系列的字叫做sumka'i,意思是sumti的代理人。在中文,我們可以叫它「代sumti」,因為它們和中文的代名詞的意思很像,只是代表的是sumti而非名詞。事實上,你已經知道ti、do和mi了,不過邏輯語還有很多的sumka'i。首先,我們要把它的架構整理出來。我們可以從對中文使用者最熟悉的,而且你已經學到的開始:
- ti = sumka'i:接近的「它」:表示一個物理上接近說話者的sumti
- ta = sumka'i:近距離「它」:表示一個物理上離說話者有段距離、或是接近聽者的sumti
- tu = sumka'i:遠距離「它」:表示一個物理上遠離說話者及聽者的sumti
你可以發現i、a、u的序列一直出現。不過有些事情必須要先澄清一下:首先,這些sumti可以用在任何佔據一塊物理上空間的事物。物體一定可以,而想法顯然不行。事件的話可以,不過它一定要在一個特定的地點發生:你指不出茉莉花革命,但是可以指出酒店鬥毆或是親吻的事件。第二,注意在不同的詞下,距離是相對於不同的東西的:tu只能用在離說話者和聽者都很遠的事物上。在說話者和聽者離的很遠,而聽者看不到說話者的情況下,ta是指接近聽者的事物。第三,這些都是相對,而且由情境而定的。這三個字在寫作時很容易出問題,因為說話者和聽者不知道對方在哪裡,而且位置會隨時間改變。而且,書的作者沒辦法將「指」的動作表現在書裡面。
還有一個系列叫做KOhA3,mi和do(還有ko,但我不會把它寫在這裡)是其中的成員:
- mi = sumka'i:說話者(們)
- mi'o = sumka'i:說話者(們)與聽者(們)形成的群體
- mi'a = sumka'i:說話者(們)與其他人形成的群體
- ma'a = sumka'i:說話者(們)、聽者(們)與其他人形成的群體
- do = sumka'i:聽者(們)
- do'o = sumka'i:聽者(們)與其他人形成的群體

KOhA3(不包括ko)的文氏圖。le drata不是KOhA3,但它的意思是「其他人(們)」。
好幾個人可以成為「說話者們」,只要一個敘述可以代表所有人。所以,雖然「我們」可以翻譯為mi、mi'o、mi'a或ma'a,其實在大多數的狀況下它都是mi。這六個,只要是指稱多於一個人的就表示群體。在bridi的邏輯裡,A說的mi gleki這個bridi和B對A說的do gleki是完全等價的,所以會被認為是相同的bridi。我們會在講到brika'i(代bridi)時再回來這個地方。
所有以上的sumka'i適用範圍都很狹窄,而無法應用在,像是,這一章開頭的句子上。以下的這個系列原則上可以用來指稱任何sumti:
- ri = sumka'i:最晚近的sumti
- ra = sumka'i:一個剛剛提到,但不是最近的sumti
- ru = sumka'i:一個很久以前提到的sumti
這些sumti會指稱任何已經結束的sumti,除了大多數的sumka'i。sumka'i無法由這些詞指稱,因為它們很容易重複。例外有ti、ta和tu,因為你有可能改變了你指涉的東西,所以無法直接重複。(有其他的例外,之後會講到。)它們只能用來指稱已經結束的sumti,所以你不能把它用來指稱那個字所在的抽象。le pendo noi ke'a pendo mi cu djica lo nu ri se zdani在這邊ri不會指稱抽象句,因為它還沒結束,也不會是mi或ke'a,因為它們是sumka'i,所以它指稱的是le pendo。
ra和ru指稱的對象依情境而定,不過它們一樣遵從以上的規則,而且ru一定是指稱比ra更遠的sumti,而ra一定是指稱比ri更遠的sumti。
ri還有其相關的詞可以用來處理原先的句子。試試看利用兩個sumka'i說出它。
答案:le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. cu tavla ru lo bangu poi ru cu se bangu ke'a,ri是不對的,因為它指稱的是la .lojban.。ra可以用,不過它有可能會被誤認為是指稱lo nu tavla fo la .lojban.,而ru在這邊會被認為是在指稱最遠的sumti,就是最外圍的那一個。
最後,還有一些sumka'i表示的是一段話語,這些sumka'i又稱為話語變數。它們不一定只能指稱一句話,如果情境許可,它們可以指稱很多句子。
- da'u = 話語變數:許久以前的句子
- de'u = 話語變數:最近以前的句子
- di'u = 話語變數:前一個句子
- dei = 話語變數:這一個句子
- di'e = 話語變數:下一個句子
- de'e = 話語變數:最近之後的句子
- da'e = 話語變數:許久以後的句子
- do'i = 話語變數:省略的話語變數:某句
這些詞將句子作為sumti,不過只表示那些字詞,而不包括背後的意思。
還有更多邏輯語的sumka'i,但是你可能需要從這裡休息一下了。下一章會是關於衍生sumti,也就是由其它sumti做成的sumti。
第十六章:邏輯語sumti之三:衍生sumti
你八成也看出來了,le bangu poi mi se bangu ke'a是「我的語言」的翻譯,但它實在是沒有很優雅。那是因為它繞了遠路。你可以說「我說的語言」是適合bangu mi這個bridi的x1的sumti,只是我們沒辦法用gadri將那個selbri轉為sumti:le bangu {ku} mi是兩個sumti,因為bangu mi是bridi,而不是selbri。我們也不能用le su'u,因為su'u會給bridi一個新的表示抽象x1,然後le會抓住新的x1。如此一來我們只會得到一個意思是「某物是我的語言」的抽象sumti。
該是be登場的時候了。be是將其他構造(sumti、sumtcita還有其他東西)和sumti結合的字。把它用在一般的selbri上不會有任何效果:mi nelci be do中的be沒有任何作用。可是,當一個sumti以這種方式和selbri結合,你就可以直接將gadri用在selbri上而不用擔心sumti會跑掉:le bangu be mi就是以上問題的正確解法。你也可以將一個sumtcita接上去:le jinga be gau do就是「你導致的贏家」。
那如果我想要將許多sumti接上在gadri裡的selbri呢?「把蘋果給你的人」是le dunda be lo plise be do,是吧?不是。第二個be接的是「蘋果」,所以sumti是le plise be do,意思是「你這個品種的蘋果」,說不通。如果你想將許多sumti串在selbri上,第一個之後的sumti都要用bei連接。結合可以由be'o結束--一個有由be接上sumti的selbri會有一個be'o。
把以上說的列下來:
- be = 將sumti或sumtcita和selbri結合
- bei = 將第二、第三、第四(之類的)sumti或sumtcita和selbri結合
- be'o = 結束與selbri的結合
還有其他可以表示sumti和其他sumti有關聯。pe和ne分別表示限制性和非限制性的關聯。事實上,le bangu pe mi會是「我的語言」比較好的翻譯,因為這個翻譯就像中文一樣沒有表明「我」和「語言」之間的關係。
pe和ne只有在鬆散的關聯時會使用,像是利用「我的椅子」來描述你現在正在坐的椅子。它並不是你的,但它和你有關連。更緊密的連結可以用po,表示這個連結是個人且獨特的,就像是利用「我的車」來描述你的確擁有的車。最後一個關聯詞是po'e,它將sumti用所謂「不可分離」的方式連結,表示這個關聯是sumti內在的。例子有「我的媽媽」、「我的手臂」或「我的家鄉」:這些「擁有」的關聯沒辦法消除(就算你把你的手臂鋸掉了,它還是你的手臂),所以是不可分的。不過在幾乎所有適合po'e的情況下,selbri的x2就是會和x1有關聯的東西了,所以用be還是比較好。
- ne = 非限制性關係片語。「和…有關的…」
- pe = 限制性關係片語。「和…有關的…」
- po = 所有格關係片語。「和…特定的…」
- po'e = 不可分所有格關係片語。「…的…」
一個非常好用的結構是{gadri} {sumti} {selbri}。這和{gadri} {selbri} pe {sumti}是等價的。所以le mi gerku和le gerku pe mi是等價的。你也可以把描述性sumti放進描述性sumti裡,所以le le se cinjikca be mi ku gerku = le gerku pe le se cinjikca pe mi = 「和我調情的人的狗」。只是這樣並不容易閱讀(或理解,在口說的時候),所以不常使用。
你也會需要tu'a,這個字會讓許多句子變得容易許多。它將sumti變為另一個sumti--一個和原先的sumti有某些關係的抽象。舉個例子,我可以說mi djica lo nu mi citka lo plise,或者我可以讓情境決定我想要蘋果的哪種抽象而只說mi djica tu'a lo plise。對方聽到tu'a SUMTI時一定要猜說話者想說的是哪一種抽象,所以tu'a應該只在情境明顯的時候使用。另一個例子:
- gasnu = x1 做/導致 x2 (不一定要有意)
za'a do gasnu tu'a lo skami = 「我看到你讓電腦做了什麼」。在正式的文法上,tu'a SUMTI和le su'u SUMTI co'e是等價的。很模糊,但是很有用。不過有些時候就算看起來很適合,還是不能用tu'a。就是在我想要sumti是某實體的事物而非某種抽象的時候。在這個時候你可以用zo'e pe。
- tu'a = 將sumti轉為與sumti有關的模糊抽象。和le su'u SUMTI co'e kei ku等價。
最後,sumti可以利用LAhE轉換為其他種類的sumti。
- lu'a = 將個體(們)/群體/序列/集合轉為個體。
- lu'i = 將個體(們)/群體/序列/集合轉為集合。
- lu'o = 將個體(們)/群體/序列/集合轉為群體。
- vu'i = 將個體(們)/群體/序列/集合轉為序列,不表明順序。
這些字的使用方式很直觀:將它們放到某種sumti前,就會形成一個不同種類的sumti。不過,要注意到有這裡出現了第四種sumti,序列。它很少被用到(像是,它沒有自己的gadri),它只是為了完整性而被列在這裡。
LAhE的最後兩個成員不是在sumti的類別間做轉換,而是讓你可以藉著一個指稱它的東西表示一個sumti。
如果一個sumti A指稱sumti B,可能sumti A是書名,或名字,或句子(句子一定指稱某樣事物,最少也是一個bridi),la'e SUMTI A表示的是sumti B。像是mi nelci la'e di'u就是「我喜歡你剛才講的」(不是mi nelci di'u,因為它的意思是「我喜歡你的前一個句子」)或la'e le cmalu noltru表示「小王子」這本書,而不是某個小王子本身。lu'e的作用完全相反--lu'e SUMTI表示的是指稱該sumti的東西。
- la'e = 「…指稱的事物」--從指稱A的sumti B中,抓出sumti A
- lu'e = 「指稱…的事物」--從sumti A中抓出sumti B,當B指稱A
第十七章:一些可愛的詞
經過了前三章,你已經獲得許多關於邏輯語sumti的知識了。在一長串嚴密有系統的學習過後,還有什麼是比介紹一些我不想,或沒辦法放進其他章節的詞更適合的呢?所以這裡有一些很好用的小詞:
底下這些cmavo都是省略詞。你應該已經很熟悉第一個了。
- zo'e = 省略的sumti
- co'e = 省略的selbri
- do'e = 省略的sumtcita
- ju'a = 省略的證據詞
- do'i = 省略的話語變數
- ge'e = 省略的指示詞
以上的這些詞在文法上和它們表示的cmavo相同,只是它們不表明任何資訊,所以在你懶得講的那麼清楚時很好用。不過,以下是一些需要澄清的地方:
- zo'e必須要指稱某個有內容的事物。像是「零臺車」或「什麼也沒有」沒有任何內容,就不能用zo'e表示。這是因為如果zo'e可以表示「什麼也沒有」的話,selbri就有可能會因為有個省略的zo'e沒有內容而和其否定一樣。
- ge'e並不是指你沒有感受到情緒,而是你覺得沒什麼好說的,就跟「我覺得還行」很類似。ge'e pei詢問一個省略的指示詞,所以可以作為「你覺得怎樣?」的翻譯。
- co'e在你因為某些文法上的緣故而需要一個selbri時很好用,就像是前一章提到的tu'a一樣。
- ju'a不會改變bridi的真值或是任何主觀態度之類的東西。事實上,它通常不會做什麼事。不過,ju'a pei「你這樣說的根據是什麼?」很好用。
- do'i很好用。在許多時候你想要用「這」或「那」指稱話語或對話時,你要用的就是do'i。
- 如果你在一個selbri裡塞了比它的容量還要多的sumti時,多出的sumti會被認為是有隱含的do'e在前面。
然後,還有一個詞,zi'o,可以讓你塞進sumti位裡將它從selbri中被刪掉。舉個例子,lo melbi be zi'o就是「漂亮的東西」,其並不包含原先melbi的x2,就是覺得一個東西很漂亮的觀察者。所以它的意思可以是「客觀上漂亮」。當一個sumti位從selbri中被刪掉時,它的意思並不是該sumti位裡沒有東西,而是該sumti位的東西不再我們考慮的範圍內。把zi'o搭配上sumtcita時會有奇怪的結果。形式上,它們兩個會互相抵消,但是在實務上它們會被理解為是在特別表明一個sumtcita沒有被考慮,就像是在mi darxi do mu'i zi'o「我打你,有或沒有動機」。
然後是jai。它是一個難以理解,但懂了之後就很好用的字。它有兩個不一樣但相似的功能,兩個都和轉換selbri有關,就像是se做的事一樣。
- jai = 轉換selbri:將sumtcita或未指明的抽象轉為x1。與fai合用。
- fai = 標示sumti位。和fa類似。與jai合用。
第一個結構是jai {sumtcita} {selbri}。它移動selbri的sumti位使得sumtcita指定的sumti位變成selbri的x1,而selbri的舊x1就消失了,只能用作用類似fa的fai來提取。以下是一個例子:
- gau = sumtcita(從gasnu):bridi由主動施事者{sumti}導致
do jai gau jundi ti fai mi = 「你讓我注意到這個。」新的selbri,jai gau jundi的位置結構是「x1使x2被注意」,然後這兩個sumti位再由do和ti填入。之後的fai標示了舊x1,就是注意某物的人,而它由mi填入。這個字很方便而且有數不清的應用,一個例子是描述型sumti。你可以利用lo jai ta'i zukte來表示「有意的行為的方法」。
- ta'i = sumtcita(從tadji):bridi由方法{sumti}達成
你可以推論出邏輯語的do jai gau mo是什麼意思嗎?
答案:你在做什麼?
jai的另一個功能比較好解釋。它將selbri做轉換,使得x1的sumti獲得一個tu'a在前面(ko'a jai broda = tu'a ko'a broda)。換句話說就是,它將填進x1的sumti轉換為一個(與之相關的)抽象句,然後將該抽象句填入selbri的x1裡面。一樣,原先的sumti位可以用fai存取。
一個很活躍的邏輯語IRC使用者常常說,在這邊隨便填一個x1舉例,le gerku pe do jai se stidi mi。他在說什麼?
- stidi = x1 啟發/提議 x2 做 x3
答案:我提議你的狗(的/做某件事)
目前你已經學到如何將bridi轉為selbri,selbri轉為sumti,以及selbri轉為bridi,因為selbri本身就能當作bridi。你現在只需要最後一個:把sumti轉為selbri。這個可以用me達成。它會吃進一個sumti,然後把它轉換為selbri。
- me = 通用的把sumti轉為selbri。x1是SUMTI指稱的東西
當你說錯了一個句子,知道如何修正是很重要的。邏輯語有三個字讓你刪除之前說過的話:
- si = 刪除:只刪除最近一個字。
- sa = 刪除:往前刪除直到遇到sa後方的cmavo。
- su = 刪除:把整段對話刪掉。
這些字的功能很明顯:它們將之前說過的字刪掉,就像它們從未被說過一樣。不過它們在一些引用(除了lu ... li'u之外的所有引用)中會失效,不然你就沒辦法引用這些字了。多個si在一起可以刪除多個字。
第十八章:引用
邏輯語的其中一個設計理念就是言文一致,也就是所有寫出來的東西在說話時都要表現出來,反之亦然。所以,邏輯語不能有不被唸出來的標點符號。這意味著邏輯語有許多可以引用其他字的字。所有邏輯語的引用詞會吃進一個字串,然後將它轉換為sumti。我們從最簡單的開始:
- lu = 引用詞:開始內容為合文法的邏輯語的引用
- li'u = 引用詞:結束內容為合文法的邏輯語的引用
這個結構中的字串必須要是合法的。它可以用來引用所有邏輯語的詞,不過有少數例外,最明顯的就是li'u。
試試看翻譯以下的句子。別著急,慢慢來。
- mi stidi lo drata be tu'a lu ko jai gau mo li'u
- drata = x1和x2在x3標準下不同
答案:我提議一件事,那件事和ko jai gau mo有關的東西不同。
這兩個引用詞不能引用不合文法的字串。不過有時會需要這樣做,像是當你只想抓出句子的一部份時:「gi'e是邏輯語的sumtcita嗎?」
要這樣做的話,你需要這兩個cmavo:
- lo'u = 引用詞:開始內容為不合文法的邏輯語的引用
- le'u = 引用詞:結束內容為不合文法的邏輯語的引用
這兩個詞中間必須是邏輯語,但不一定要合文法。試試看把以上的例子(有gi'e的那個)翻譯成邏輯語。
答案:xu lo'u gi'e le'u lojbo sumtcita
這種引用可以引用所有邏輯語的詞,除了le'u。不過這樣還是不夠。如果我們想要翻譯「do mo是『你怎麼了?』的正確翻譯嗎?」,我們問的東西其實不完全正確,因為do mo也能表示「你是什麼?」,但我們先不理會這個。我們需要的詞是zoi。
- zoi = 下一個cmavo會做為開始並結束萬能引用的詞
在使用zoi的時候,你先任意挑一個構詞上正確的邏輯語的詞(稱為分隔符),這個詞會開始一段引用。要把引用關起來的話,就再用那個詞。這樣子的話,你就可以引用除了分隔符之外的任何東西,而因為你可以自己挑分隔符,所以這不會構成問題。通常會作為分隔符的詞就是zoi自己,不然就是一個表示引用內容的語言的字母。例子:「我(過去)喜歡歌劇魅影」是mi pu nelci la'e zoi zoi. 歌劇魅影 .zoi。有兩件事需要注意:首先,我需要la'e,因為我喜歡的不是那段引用,而是它指稱的東西。第二,在分隔符和引用之間有停頓,在書寫時可以用句點表示。停頓是必要的,這樣才能正確指稱分隔符。
試試看翻譯前面有「你怎麼了?」的句子:
- drani = x1 在 x2 方面,在 x3 情境下,在 x4 標準下是正確的/適當的
答案:xu lu do mo li'u drani xe fanva zoi jy. 你怎麼了? .jy。在這邊jy被選為分隔符,因為其為jungo「中國的;中文」的第一個字母。
和它類似的有la'o。它和zoi的用法一樣,只是它將引用轉為名字。這樣做是必須的,因為一般來講,只有selbri和cmevla可以做為名字,而引用不行。
- la'o = 下一個cmavo會做為開始並結束萬能引用的詞,引用會作為名字
最後一個官方的引用詞是zo。zo會引用接下來邏輯語的詞,無論它是什麼。這很好用。
- zo = 引用接下來邏輯語的詞,無論它是什麼。
例子:
- zo zo zo'o plixau
- 「zo」很好用,嘿嘿。
- zo'o = 言談指示詞:幽默地,「開玩笑的」
- plixau = x1 對 x2 做 x3 很有用
有些邏輯語使用者覺得在以上的基礎上,加上四個引用詞很有用。其中最常用的是:
- u'i ri pu cusku zo'oi Doh
- 哈哈,他說了「Doh」
- zo'oi = 引用接下來的詞。下一個詞由說話的停頓或是寫作的空白/句點作區辨。
這個詞非常容易使用,不過在實際使用上很容易出問題。使用者必須要注意接著zo'oi的詞不能有句點、聲門塞音或停頓。舉個例子,*zo'oi http://www.lojban.org/ 是不正確的,因為http://www.lojban.org/裡面有句點。
另一個有問題的句子:*lo salpo (ku) fa'u lo finti cu smuni zo'oi saka fa'u zo'oi sa.ka lo ponjo。在這裡sa.ka裡有個句點。
和zo'oi和la'o對應地,有個詞la'oi用法上和zo'oi一樣,只是它形成指稱叫做(下一個詞)的sumti:
- la'oi = 引用接下來的詞,「叫做…的」。下一個詞由說話的停頓或是寫作的空白/句點作區辨。
你要怎麼說「Safi是英國人。那是它的名字」?
- glico = x1 是英國的/在 x2 方面展現英國文化
- cmene = x1 是 x2 被 x3 使用的名字
答案:la'oi Safi glico .i lu'e ri cmene ri
la'oi有和zo'oi一樣的問題:接著zo'oi的詞不能有句點、聲門塞音或停頓。舉個例子,以下的句子是不合文法的:*.u'a mi te vecnu lo zgike datni pe la'oi t.A.T.u。這裡t.A.T.u裡面有句點(t.A.T.u是音樂團體的名字)。
說話的例子:la'oi .uli.uli zgike tutci。`uli`uli是一種夏威夷的樂器。這個字裡面有句點。
說話的例子:ju'i la'oi jugemujugemugokounosurikirekaijarisuigiono- suigioumatsu,unraimatsufuuraimatsuku,unerutokoronisumutokoro,iaburakoujinoburakouji- paipopaipopaiponosiu,uringansiu,uringan,nogu,urindaigu,urindainoponpokopi,inoponpokona,anotcoukiu,umeinotcousuke mi'o ko'oi klama lo ckule。在說那個名字時不能換氣,不然就會出錯!這個字(じゅげむじゅげむごこうのすりきれかいじゃりすいぎょのすいぎょうまつうんらいまつふうらいまつくうねるところにすむところやぶらこうじのぶらこうじぱいぽぱいぽぱいぽのしゅーりんがんしゅーりんがんのぐーりんだいぐーりんだいのぽんぽこぴーのぽんぽこなーのちょうきゅうめいのちょうすけ)是一個有名的日本男孩的名字。
第三,ra'oi引用下一個rafsi。因為rafsi本身不是字,它們常常得用zoi引用。再來,許多rafsi也是cmavo。為了避免混淆,ra'oi指稱的一定是rafsi,而在任何不是rafsi的字串前面就是不合法的。
ra'oi zu'e rafsi zo zukte .i ku'i zo'oi zu'e sumtcita是什麼意思?
- ku'i = 言談指示詞:但是/不過(和前面說的相對/相反)
- rafsi = x1 是 x2 詞/概念的詞綴,具備形式/性質 x3 ,在 x4 語言裡
答案:zu'e(作為rafsi)是zukte的詞綴,但是zu'e(作為cmavo)是sumtcita。
最後是好用的ma'oi。ma'oi吃任何的cmavo,但是將引用視為被引用的詞所屬的詞類(selma'o)。所以,舉個例子,ba'o屬於一個稱為ZAhO的詞類,因此ma'oi ba'o是ZAhO這個selmaho的非官方邏輯語稱呼。
試試看,說pu和ba在同一個selma'o裡面!
- cmavo = x1 是屬於 x2 詞類的功能詞/語法項,在 x3 語言裡面
一個可能的答案:zo pu cmavo ma'oi ba
第十九章:數字
在學習語言的時候,有一件通常會非常早教的事情是如何數數。這其實沒什麼道理,因為在你不知道如何表達數字作用的東西的時候,知道數字是沒什麼用的。這就是我為什麼到第十九章才講數字的一部份原因。另一個原因是雖然學習數字本身非常簡單,如何將它們作用在sumti上有時很難以理解。不過這件事我們之後再提。
在學習數字詞之前,你要知道數字沒有內部文法。這個的意思是任何一串數字詞(稱為「數字串」)在邏輯語文法中表現得和其他任何的數字串完全一樣,就算數字串沒有任何意義。所以,你永遠不可能無歧義地回答一個數字串合不合理。不過,數字詞本身會有一些預設的用法,而如果你離標準用法太遠的話,其他人很可能會搞不清楚你在說什麼。
把所有邏輯語的數字詞都學起來實在是超出本章的範圍了,所以這一章只會介紹文章中常用的。各式各樣關於邏輯語數學的cmavo稱為mekso(邏輯語的「數學表示」),而它們常常被忽視,因為它們很複雜,而且和所謂的bridi數學來比沒什麼確定的優勢。
我們先從一般的邏輯語數字開始,由零到九:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| no | pa | re | ci | vo | mu | xa | ze | bi | so |
注意除了no之外母音是如何交錯的,而且沒有子音用在兩個不同的數字上。如果要表示高於九的數字的話,直接將數字串在一起即可:
- vo mu ci - 四百五十三(453)
- pa no no no no - 一萬(10000)
還有一個疑問數位,xo,它的使用方法就像其他填填看疑問詞一樣。要回答的話,答案可以是詢問的數位本身,或者也可以是之後會看到的數字結構。
- ci xo xo xo - 三千多少?(3???)
- xo = 疑問數位-用法和其他數位一樣,詢問正確的數位。
一個實驗性的詞,xo'e,有時會被用來表示一個不表明或省略的數位。它的定義不是官方的就是了。
- ci xo'e xo'e xo'e - 三千多少
- xo'e = 省略的數位
因為所有的數字串在邏輯語文法都是相同的,一個xo'e可以表示許多數位。
還有一系列從A到F的十六進位數位。邏輯語預設是十進位,不過在使用十六進位數位時,你可以假定你在用的是十六進位:
| dau | fei | gai | jau | rei | xei | vai |
| 10(A) | 11(B) | 12(C) | 13(D) | 14(E) | 14(E) | 15(F) |
我知道表格裡有兩個E,rei是官方的(所有x開頭,三個字母的cmavo都是實驗性的)。xei會出現是為了避免和re混淆。
數字的基底可以用ju'u表明:在ju'u之前的部分是數字本身,而之後的部分是基底:
- dau so fei no ju'u pa re - 十二進位的A9B0(注意表示十二進位的部分一定是十進位。要永久改變說話時使用的進位是可能的,但因為沒有人這樣做過,所以標準流程並沒有出來。)
學習如何表示分數也很有用。它們通常利用小數點,pi,來表示。
- pi = 小數點
就像是數學表示法一樣,如果沒有數字在pi的前面或後面出現的話,數字會被認為是零。
和這個相關的,數位分隔符pi'e用來分隔數字,無論是在基底超過十六時分隔數位,或是在小數點不適用的時候,像是在談論時、分、秒時:
- pa so pi'e re mu pi'e no ju'u re ze - 二十七進位的十九、二十五、零(JP0)
- re re pi'e vo bi - 二十二、四十八(22:48)
還有一系列的數字詞表達的不是數學上精確的數字,而是主觀的、相對的數字。這些字表現的和數位幾乎完全相同,除了它們無法結合為更大的數字:
| ro | so'a | so'e | so'i | so'o | so'u |
| 所有 | 幾乎所有 | 大多 | 多 | 一些 | 少 |
把這些字和數位結合的話,這些字會被認為是表示對數字的第二個判斷:
- mu bi so'i sai - 五十八,很多。
它們不能被放在數字串的中間。當放在pi後面時,它們會被認為是表示分數的大小:
- pi so'u - 它的一小部分
- pi so'o - 它的一部分
- pi so'i - 它的一大部分
- pi so'e - 它的大多數
- pi so'a - 幾乎全部的它
底下的這些數字詞是高度主觀的,它們用起來就像是前面的數字詞:
| du'e | mo'a | rau |
| 太多 | 太少 | 足夠 |
底下五個是情境決定的數字,它們用起來和前面的數字詞相似,只是它們需要吃下之後的數字才會有意義:
| da'a | su'e | su'o | za'u | me'i |
| 除n之外所有 | 至多n | 至少n | 大於n | 小於n |
如果它們後面沒有數字串,n會被認為是一。
- so'i pa re da'a mu - 很多,是十二,不是五
最後兩個你需要知道的數字詞有比較複雜的文法:
- ji'i = 四捨五入或概數
當ji'i放在數字前時,表示整個數字是約略值:
- ji'i ze no za'u rau ju'o - 大概七十,絕對多於需要
把它放在數字的中間的話,只有它之後的數字是不精確的。在數字的結尾的話,就表示這個數字是四捨五入過的。
- ki'o = 千位分號:將數字串的數位分開;千
ki'o和kilo的相似性並不是巧合。在最簡單的情況下,ki'o在大數中一次分隔三個數字,就像是在英文中的逗點一樣。
- pa ki'o so so so ki'o bi xa ze - 1,999,867
如果ki'o前的數字不足三個的話,那些數字會被認為是最低位的數字,而高位數字會被填上零:
- vo ki'o ci bi ki'o pa ki'o ki'o - 4,038,001,000,000
ki'o在小數點後的用法也類似。
這些就是常見的邏輯語數字。如何將它們作用在sumti上本身就是一門科學,我們到第二十二章再提。現在我們先專注在這些數字要如何用在bridi裡。
一串數字詞本身是合文法的,因為它們可以作為xo問題的答案。不過在這種情況下,它們不會被認為是任何bridi的一部分。一般而言,如果數字做為bridi的一部份,它們有兩種可能的形式:純數字和量化詞。我們在之後會再看到量化詞,現在我們先看純數字。
純數字是任何一串數字前面接上li。這樣直接從數字形成sumti,表示的是,例如,「數字六」,的數學概念。它的終止詞是lo'o。
- li = 將數字/mekso表示轉為sumti。
- lo'o = 終止詞:結束將數字/mekso表示轉為sumti。
這些純sumti通常就是填入mitre或cacra等brivla的x2的東西:
- mitre = x1 是 x2 公尺,在 x3 方向,基準是 x4
- cacra = x1 是持續 x2 小時的時間(預設一小時),基準是 x4
試試看翻譯以下的句子:
- le ta nu cinjikca cu cacra li ci ji'i u'i nai
答案:(唉)那個調情持續了大約三小時。
你要如何在邏輯語數到三?
答案:li pa li re li ci
在這一章的最後,我們要介紹在selma'o MAI和MOI裡面的字。
MAI只有兩個字,mai和mo'o。它們兩個都是將任何數字串轉為具有指示詞語法的序數。序數可以將文本分為有標上數字的段落,像是「章」或「節」。mai和mo'o唯一的差異就是mo'o表示的是文本中比較大的分節,讓你可以用兩個階層去分隔文本,像是以mo'o來分章、以mai來分節。需要注意的是,這些詞還有屬於MOI的詞是直接吃數字詞的,不需要li。
- mai = 低階層序數標記:將數字轉為序數。
- mo'o = 高階層序數標記:將數字轉為序數。
MOI裡面有五個詞,它們全部是將數字串轉為selbri。我們一個一個看:
- moi = 將數字n轉為selbri: x1 是 x2 集合以順序 x3 排序的第 n 個成員
例子:
- la lutcimin ci moi lo'i ninmu pendo be mi le su'u lo clani zmadu cu lidne lo clani mleca
- 盧志民是我的女性朋友中排第三的,順序是:比較高的排在沒那麼高的前面。
當表示一個順序時,如果ka-抽象(第三十章)用作sumti的話,大家都會認為集合是由該特質多的排到該特質少的,所以以上句子的x3可以縮短為lo ka clani。
- lidne = x1 在 x2 之前,序列是 x3
- clani = x1 在方向 x2 ,在標準 x3 很長
- zmadu = x1 超越 x2 ,在性質/面向 x3 上,超越的值是 x4
- mleca = x1 比 x2 少,在性質/面向 x3 上,少的值是 x4
- mei = 將數字n轉為selbri: x1 是 x2 集合形成的群體,其中集合有 n 個 x3
注意在這裡 x3 要是個體, x2 要是集合, x1 要是群體。
mi ci mei是什麼意思?
答案:我們是三個的群體
- si'e = 將數字n轉為selbri: x1 是 n 倍的 x2
例子:
- le vi plise cu me'i pi pa si'e lei mi cidja be ze'a lo djedi
- 這裡的蘋果比我一天的食物的十分之一還少
注意如果你查字典的話,它會跟你說si'e是「x1 是 n 分之一的 x2」,而非「x1 是 n 倍的 x2」。但是人們用的都是我在這邊的定義,所以字典的解釋很有可能會改。
- cu'o = 將數字n轉為selbri: x1 在 x2 的條件下有 n 的機率發生
例子:
- lo nu mi mrobi'o cu pa cu'o lo nu mi denpa ri
- 我死亡的事件有一的機率,條件是:我等它=只要我等夠久我一定會死
- denpa = x1 等待 x2 ,在 x3 的狀態下直到回去做 x4
- va'e = 將數字n轉為selbri: x1 在 x2 標度的第 n 個位置
例子:
- li pa no cu ro va'e la torinon
- 十是杜林危險指數的最大值。
第二十章:bo、ke、co,還有更多可愛的東西
假設你是重要的、美國的、電腦買家。你要怎麼說?對這種架構,tanru最適合了:mi vajni merko skami te vecnu。不,等等,這不對。tanru是由左而右組合的,所以這個tanru是:((vajni merko) skami) te vecnu,重要美國人用電腦的買家。要獲得想要的tanru,你不能改變selbri的順序,也沒辦法用邏輯連接詞,反正你現在也還沒學到。唯一的方法是強迫selbri以不同的方式組合。
要將tanru中的兩個selbri綁起來的話,可以將bo放在它們之間:mi vajni bo merko skami bo te vecnu會被解讀為mi (vajni bo merko) (skami bo te vecnu),在這個情境下就很適用了。如果bo在一串selbri中間都有出現的話,它們是以右到左組合的,而非原先的左到右:mi vajni merko bo skami bo te vecnu會被解讀為vajni (merko bo (skami bo te vecnu))「重要的(美國的電腦買家)」,在這個情境下更適用。
- bo = 把兩個selbri強力綁在一起。
你要怎麼說「這是好吃的黃蘋果」?
- kukte = x1 對 x2 而言很好吃
答案:ti kukte pelxu bo plise
那「這是大的、好吃的黃蘋果」呢?
答案:ti barda kukte bo pelxu bo plise
另一個方法是用ke ... ke'e。這些詞可以理解為前面段落使用的括號。ke開始將selbri組起來,而ke'e結束它。
- ke = 開始強selbri分組
- ke'e = 結束強selbri分組
如此分組的強度和bo相同。所以,mi vajni merko bo skami bo te vecnu可以寫成mi vajni ke merko ke skami te vecnu {ke'e} {ke'e}。
你要怎麼說「我是德國的賣黃色家的人」?
答案:mi dotco ke pelxu zdani vecnu
在我們在和tanru平常的結構打交道時,還有一個字我們可以特別注意。如果我想說我是專業的翻譯家,我可以說mi fanva se jibri。
- jibri = x1 是 x2 的工作
- dotybau = x1 是 x2 用來表達 x3 的德語/德文
- glibau = x1 是 x2 用來表達 x3 的英語/英文
如果我想要說我是從英文譯到德文的專業翻譯家,我就得用be和bei:mi fanva be le dotybau bei le glibau be'o se jibri,而我用了tanru的事實很容易因為句子複雜的結構而在說話時被丟失。在這裡,我們可以用co。這個字會將tanru反轉,讓右邊的selbri修飾左邊的selbri:mi se jibri co fanva le dotybau le glibau和前一個邏輯語bridi是相同的,只是容易理解許多。需要注意的是在tanru前的sumti填的是se jibri,而它後面的sumti填的是修飾的selbri:fanva。
- co = 反轉tanru。前方的sumti填入被修飾的selbri,後方的填入修飾者。
co連接兩個selbri的強度非常弱--甚至比tanru不用分組詞的連結還弱。這樣才能確保在co-結構中,最左邊的selbri一定是被修飾的,而最右邊的selbri一定是修飾的,就算兩邊有tanru也一樣。這使得co-結構很容易理解:
ti pelxu plise co kukte是ti (pelxu plise) co kukte,和ti kukte pelxu bo plise一樣。這也意味者ke...ke'e不能包住co。
不過,GIhA這個selma'o中的cmavo,也就是bridi尾端的事後邏輯連接詞,連接的強度比co更弱。這是為了完全避免混淆說在GIhA-結構中哪個selbri和哪個selbri連結。答案很簡單:GIhA永遠不會包住selbri群。
你要如何用co表示「我是重要美國的、電腦買家」?
答案:mi skami te vecnu co vajni merko
如果這會有用的話,底下是不同的selbri組合詞,以強度排序:
- bo 和 ke...ke'e
- 邏輯連接詞,除了bridi尾端的事後邏輯連接詞(第二十五章會解釋)
- 沒有組合詞
- co
- bridi尾端的事後邏輯連接詞(也在第二十五章)
這一章之後的部分就不是關於selbri分組的了,而是像是第十七章一樣,介紹一些雜項的,好用的詞。
bo有另一個用法,看起來和selbri分組沒什麼關係:它也可以將一個sumtcita綁到一個bridi上,使得sumtcita的內容不是sumti而是bridi。這個用例子最好解釋:
- xebni = x1 恨 x2
mi darxi do .i mu'i bo mi do xebni - 「我打你,動機是我恨你」。在這邊bo將mu'i綁在後方的bridi上。這就是時態sumtcita和一般sumtcita的差異變明顯的部份了。在用bo把一般sumtcita和bridi綁起來時,這表示後面的bridi以某種方式放進了sumtcita的sumti位。但是由於某個鬼才知道的原因,將ba或pu和bridi綁起來會有完全相反的效果。舉個例子,在mi darxi do .i ba bo do cinjikca這個bridi裡,你會假定第二個bridi以某種方式放進了ba的sumti位,表示第一個說出的bridi是在第二個bridi的未來發生的。但這卻是錯的,而正確翻譯會是「我打你,然後,你調情」。這個奇怪的規則就是將所有sumtcita都編為同一個詞類的主要障礙之一。另一個差別是,時態sumtcita就算適用也能被省略。這個規則其實很合理,因為我們常常可以假設bridi是放在某時空背景下的,但我們不能對BAI的sumtcita假設一樣的事情。
非官方的me'oi和me la'e zo'oi是等價的,表示這個字會將下一個字轉為selbri。它可以用來臨時發明brivla:mi ca zgana la me'oi X-files表示「我現在在看X-files」。和zo'oi和la'oi一樣,它也不能接受有空格,句點(或說話的停頓)的字。
gi是一種奇怪的bridi分隔詞,和.i很像,但據我所知,它只用在兩種不同的結構:最常見的是用在邏輯連接詞上,這在第二十五章會解釋,還有用在sumtcita上。與sumtcita合用的話,它會創造一個好用但很少見到的結構:
mu'i gi BRIDI-1 gi BRIDI-2,和BRIDI-2 .i mu'i bo BRIDI-1等價。所以,之前那個解釋我打你的例子可以寫成mu'i gi mi xebni do gi darxi do,或者是如果我們要保留原先句子的順序的話,我們可以用se轉換mu'i:se mu'i gi mi darxi do gi mi xebni do。
在像這種的例子,gi可以充分展現其可塑性。它不只像.i一樣分開兩個bridi,還可以在同一個bridi內分隔兩個結構,使得在gi之外的結構可以同時套在兩個bridi上,像是以下例子展示的:
- cinba = x1 親 x2 ,在 x3
mi ge prami do gi cinba do將mi留在結構外面,mi就會同時套在兩個bridi上。這也可以用在do上,因為do也都在兩個bridi裡:mi ge prami gi cinba vau do。注意在這裡,我們會需要vau,讓do出現在第二個bridi外面。
所以,我們可以縮短原本的句子:mi mu'i gi xebni gi darxi vau do,或,把vau省掉,我們可以把它縮得更短更簡潔:mi do mu'i gi xebni gi darxi
第二十一章:COI
在這一章,你會熟悉呼應詞,或ma'oi coi。它們會有自己的一章,不是因為瞭解它們會對理解邏輯語的結構有幫助,也不是因為它們很難理解,而是因為它們在非正式對話中非常常用,而且它們有一堆。
呼應詞一部分是用來表明do指的是誰。如果呼應詞後方接的是cmevla,cmevla前方會有一個隱含的la。如果接的是selbri,那gadri會被假定為le。
在這些例子裡,我會用coi這個呼應詞,意思是「嗨」或「你好」。
如果一個人叫做la + SELBRI,對那個人使用呼應詞接上selbri本身會表示你稱呼她為那個selbri的x1,而這常常是錯的。舉個例子,假如有人叫la tsani,「天空」,說coi tsani是將她稱為le tsani,意思是「嗨,(你是)天空」,而coi la tsani會正確地將她稱為某個叫做「天空」的人,意思就是「嗨,天空」。這是一個常見的錯誤,尤其是在初學者之間。
所有呼應詞都有一個有時會需要的終止詞,do'u。這個詞最常用在呼應片語的最後一個詞和接下來的第一個詞都是selbri的時候,do'u會避免tanru的形成:
- do'u = 結束呼應片語。通常可省略。
- klalu = x1 哭出 x2 (眼淚)因為理由 x3
- coi la gleki do'u klaku fi ma
- 嗨,快樂。你為什麼在哭呢?
一般的呼應詞,doi,除了表示do指的是誰之外沒有做任何事:
- xu doi .ernsyt. do docto merko
- 恩斯特,你是德裔美國人嗎?
其他的呼應詞在除了定義do是誰之外都有內容。例如你已經知道的coi,也有「嗨」的意思。許多呼應詞,像指示詞一樣,都有兩到三個定義。這是因為它們可以用cu'i和nai修飾,不過只有一個呼應詞的cu'i-型式有定義而已。
一些重要的呼應詞列在底下的表格裡。還有其他的,只是它們不常用。
| 呼應詞 | 不加後綴 | cu'i | nai |
|---|---|---|---|
| coi | 你好 | ||
| co'o | 再見 | ||
| je'e | 了解/OK | 不了解 | |
| fi'i | 歡迎 | 不歡迎你 | |
| pe'u | 請 | ||
| ki'e | 謝謝 | 不感謝 | |
| re'i | 準備好要聽了 | 還沒好 | |
| ju'i | 嘿! | 輕鬆 | 忽略我 |
| ta'a | 打擾了 | ||
| vi'o | 會做 | 不會做 | |
| ke'o | 請重複 | 不必重複 | |
| di'ai | 祝好運 | 詛咒 |
注意di'ai是實驗性的
coi co'o是什麼意思?
答案:「你好,再見」或路過的招呼
je'e是用作OK,不過也是接受讚揚或感謝時的適當回應(至少,如果你要表現出謙虛的話),因為它表示讚揚或感謝有成功收到了。
翻譯ki'e sidju be mi bei lo vajni .i je'e .jenifyn.
答案:謝謝你,幫助我做重要的事的人。不客氣,珍妮佛。
還有fi'i te vecnu .i .e'o do citka
答案:歡迎,買家。請吃吧!
re'i用來表示你準備好要通話了。它可以用來作為邏輯語的「我能為你做什麼?」或是電話上的「喂」。re'inai可以指「不在電腦前」或「再一下下」。
翻譯:「你好,我能為你做什麼,翻譯家?」(假設你說話的人叫做「翻譯家」)
答案:coi re'i la fanva
ta'a可以用來禮貌地打斷其他人。這個的適當回應是什麼呢?
翻譯:ta'a ro do mi co'a cliva
- cliva = x1 離開 x2 ,沿著路徑 x3
答案:「打擾了各位,我要離開了」注意這裡不需要終止詞或.i。
ke'o在不太有經驗的邏輯語使用者口頭對談時很常被用到。這是個很好用的詞。
- sutra = x1 做 x2 很快
翻譯:.y ke'o sutra tavla
答案:呃,請重複,說話很快的你
還有「好好好,我已經知道了,我會做!」
一個答案:ke'o nai .ui nai vi'o
第二十二章:sumti的量化
絕大多數其他的學習教材,像是CLL或是邏輯語初學者教程,是在官方接受xorlo,一個在gadri的定義和量化上的改變,之前寫成的。以前的教程包含了像這樣的一些過時的部分是寫這個課程主要的動機。對我非常不幸的,sumti的量化在詳細討論某些規則的意義時可以變成非常複雜的主題。為了讓這裡的文字可以精確地表現BPFK的官方「黃金準則」,這一章是最後寫完的章節之一,也是最常重寫的章節之一。我強烈建議任何發現發現此處文字有錯誤的人聯絡我,這樣有錯的文字才會被更正。
免責聲明說完了,那我們開始吧:
你要知道的第一個概念是「分配性」。在第十四章講到一群被認為具有分配性的事物時,我有用的「個體」這個詞。一群被認為具有分配性的事物的意思是selbri對那一群中的每個事物都適用。這就和(群體有的)非分配性對立,非分配性表示群體有些群體中的個體都沒有的特性。分配性和非分配性的差別在sumti的量化時很重要。
有時也會提到一個sumti如何在另一個sumti上分配,所以在這裡也講一下:如果sumti A和sumti B有關係X,而sumti A在sumti B上分配,這個的意思是每個A和B都有X的關係。舉個中文的例子:
- 三隻狗咬兩個人。
如果狗在人上分配的話,那就表示三隻狗各咬了兩個人,表示有二到六個人被咬(因為可能會有運氣很差的人被三隻狗都咬了);而要是人在狗上分配的話,就表示兩個人各被三隻狗咬,所以人就一定是兩個,而狗可以有三到六隻。
如果對於哪個sumti在哪個sumti上分配有不清楚的話,規則是「先提到的sumti一定在後提到的sumti上分配」。這和位置結構無關,所以如果x1和x2被se互換了,先提到的x2會在x1上分配。
現在回到量化。我們先考慮你要怎麼量化描述性sumti,就是具備GADRI BRIVLA形式的sumti。進行量化的數字串可以出現在gadri的前面,這時我們稱它「外量詞」,或者它可以放在gadri和brivla中間,這時它叫做「內量詞」。所有的數字串都可以作為量化詞。
外量詞和內量詞影響sumti的規則視gadri的種類而定:
lo和le。內量詞表示有我們在討論多少個事物--在談話中共有幾個事物。如果有外量詞的話,sumti在那麼多的事物上分配。之前提過了,如果沒有外量詞的話,我們並不清楚selbri作用在多少事物上(不過不是零),以及它具不具分配性。有例子總是好的,所以在這:
mu lo mu bakni cu se jirna - 內量詞「五」表示了我們在講五頭牛,而外量詞「五」表示selbri在五個上都是對的。所以它的意思是「五頭牛都有角」。
- bakni = x1 是 x2 品種的牛
- jirna = x1 是 x2 的角(隱喻:任何尖端)
底下的bridi是什麼意思?
- lo ru'urgubupu be li re pi ze mu cu jdima lo pa re sovda
- ru'urgubupu = x1 是 x2 英鎊
- jdima = x1 是 x2 對買家 x3 、賣家 x4 的價格
答案:「十二顆蛋二點七五英鎊」就像在中文翻譯一樣,它可以表示每顆都是2.75鎊(分配性)或總共是2.75鎊(非分配性)
- so le ta pa pa ci'erkei cu clamau mi (注意ta在內量詞之前)
- ci'erkei = x1 玩 x2 遊戲,規則是 x3 ,遊戲中相互關聯的元素是 x4
- clamau = x1 比 x2 高/長,在方向 x3 上,超出的量是 x4
答案:內量詞表示對談中有十一個玩家,而外量詞表示selbri分配地作用在九個上。所以意思是「那十一個玩家有九個比我高」
關於lo和le的量化,有幾點需要特別提出來的:
將lo和外量詞連用,「{數字} lo {selbri}」,和「{數字} {selbri}」的作用相似,它們都是在個體上量化。所以,ci gerku cu batci re nanmu和ci lo gerku cu batci re lo nanmu都會將狗和人都視為是有分配性的。所以,每隻狗咬了每個人,總共有六次咬人的事件。
({數字} lo {selbri}是被定義為{數字} da poi me lo {selbri},而{數字} {selbri}是{數字} da poi {selbri}。da和me之後會解釋。簡單地說,和只有數字、在所有可以放進selbri的x1裡的東西上量化的版本相比,有lo的版本考慮更多情境。)
- batci = x1 咬/鉗住 x2 在部位 x3 ,鉗住的工具是 x4
第二:如果沒有外量詞呢?這表示其實有一個外量詞在那邊,但是被省略了嗎?不是。如果有任何的外量詞,無論它有沒有被省略,sumti一定會變成分配性的,就表示lo或le都沒辦法用在作用在集體上的謂詞上。所以,如果沒有外量詞的話,它不是被省略了--它就是不在那邊。沒有外量詞的sumti可以被稱為「常數」。
第三,外量詞比內量詞大是沒有意義的。這表示selbri作用在比對話中出現的數量更多的sumti上。但既然它們都在bridi裡面,它們就是對話中的一部份。不過這樣說是合文法的。
第四,如果有內量詞的話,把lo或le放在sumti前是合文法的。「lo/le {數字} {sumti}」被定義為「lo/le {數字} me {sumti}」。
所以這個句子是什麼意思?
- mi nelci lo mi briju kansa .i ku'i ci lo re mu ji'i ri cu lazni
- briju = x1 是 x2 位於 x3 的辦公室/工作地點
- kansa = x1 陪 x2 ,在動作/狀態/事業 x3 上
- lazni = x1 很懶惰,逃避關於 x2 的工作
答案:我喜歡我的同事,但是他們約二十五個中有三個很懶惰
la。內量詞在名字是selbri時是合文法的,此時內量詞會被視為是名字的一部份。外量詞用來在該個體上具分配性地量化(就像在lo/le的狀況一樣)。la出現在{數字} {sumti}前是合文法的,此時數字和sumti都被認為是名字的一部份。
翻譯:re la ci bargu cu jibni le mi zdani
答案:兩個「三個弧」離我家很近。(也許「三個弧」是餐廳?)
loi和lei。內量詞表示群體中有多少個成員。外量詞在群體上作分配性的(!)量化。
要注意雖然群體由不具分配性的成員組成,外量詞都是將各個群體視為是個體。
當在數字串+sumti前出現時,loi/lei的定義是「lo gunma be lo/le {數字} {sumti}」--「由{數字}個sumti組成的群體」。
試試看翻譯:dei joi di'e gunma re loi bi valsi .i ca'e dei jai se jalge lo nu jetnu
- gunma = x1 是由個體 x2 組成的群體
- valsi = x1 是意思是 x2 ,在語言 x3 的詞
- ca'e = 證據指示詞:我定義
- jetnu = x1 是真的,由形上學/認知論 x2
答案:這個和下一個句子形成的群體是兩個八個詞的句子組成的群體。(我定義)這個句子使得(這)是真的。
lai。和la很像,內量詞(當名字是selbri時)是名字的一部份。外量詞會具分配性地量化。在數字+selbri之前,數字和selbri都是名字的一部份。
當分數用作loi、lei或lai的外量詞時,表示談論的是群體的一部份。(例如,「一半的強森」--pi mu lai .djansyn.)
lo'i和le'i。內量詞表示集合中成員的數量。外量詞在集合上作分配性的(!)量化。當在數字+selbri前出現時,它被定義為是「lo selcmi be lo/le {數字} {sumti}」--「由{數字}個sumti組成的集合」。
翻譯:lo'i ro se cinki cu bramau la'a pa no no lo'i ro se bogykamju jutsi
- cinki = x1 是 x2 物種的昆蟲
- la'a = 言談指示詞:很可能
- bramau = x1 比 x2 大,在方向/維度 x3 上,超出的量是 x4
- bogykamju = x1 是 x2 的脊椎
- jutsi = x1 是在 x2 屬、 x3 科...的物種(開放式分類)
答案:所有昆蟲物種的集合很可能比一百個所有脊椎動物的集合還大
la'i。和lai一樣。
和群體gadri一樣,集合gadri的外量詞可以讓我們談論集合的一部份。la'i在數字+sumti前出現的話,它的定義是「lo selcmi be la {數字} {sumti}」--「由『{數字} sumti』(視為名字)組成的集合」。
lo'e和le'e因為某些原因沒有出現在現在接受的gadri提案裡面。如果要延伸其他gadri的規則而套在這上面的話,lo/le應該是最好的選擇(因為兩者都是在個體上,而非群體上運作),所以你會期待外量詞在內量詞給予的典型/刻板印象的事物上強加具分配性的量化。
在量化指稱許多事物的sumka'i時,記得它們表現得像lo-sumti很有用。由定義,「{數字} {sumti}」定義為「{數字} da poi ke'a me {sumti}」。你在幾章之後才會熟悉da,所以現在先在這裡把它當作「某物」。所以,ci mi的意思是「屬於『我』的三個事物」。
一些重要的量化用法會需要你量化selbri或是一些身分不明的事物。這些是利用「邏輯量化變數」完成的。這些東西,還有如何量化它們會在第二十七章時講到。
最後,你要怎麼量化像是砂糖或水等不可數的東西?其中一個方法是用不精確的數字。這樣用很模糊,不僅是因為數字的值是模糊的,還有因為數字的基準沒有表明:砂糖可以視為許多晶體的群體,而「一」代表一個晶體,而水可以用現在談論的水有包含多少雨滴的量來量化。雖然的確可以這樣數,但是這樣很不精確,而且很容易誤導人。
其中一種明確表示不可數的方法是用零運算符tu'o作為內量詞。
- tu'o = 零運算符(∅)。用在一元mekso裡。
這個方法優雅又直觀,而且可以給我一個藉口來引用這個來自xorlo原先的提案、可怕但戲劇性的例子:
- le nanmu cu se snuti .i ja'e bo lo tu'o gerku cu kuspe le klaji
- snuti = x1 是 x2 表現出的意外事件
- ja'e = sumtcita:BAI:(從jalge):bridi導致了{sumti}
- kuspe = x1 在 x2 上延伸/展開
- klaji = x1 是在 x2 、到達 x3 的路
這是什麼意思?
答案:男人發生意外,導致狗展開在路上
第二個量化物質的方法是用第十章提過的時態詞ve'i、ve'a和ve'u:
- ti ve'i djacu - 這是一點點水
- djacu = x1 是水做的/包含水
當然,第三,你可以用brivla給出確切的量值:
- le ta djacu cu ki'ogra be li re pi ki'o ki'o
- 那個水重2.000000公斤
- ki'ogra = x1 有質量 x2 公斤,基準是 x3
第二十三章:否定
有些時候,只說真的東西是不夠的。我們常常會需要表明哪些東西不是真的,這時否定就派上用場了。
在中文,否定是由「不」或「沒」來表示,而它使用的規則十分地任意且不明確。身為邏輯語的使用者,我們當然不能這樣做,所以邏輯語有一個精巧而明確的否定系統。在這裡會介紹官方的黃金準則。對於使用na的黃金準則出現越來越多的爭議,而要用甚麼規則取代它目前還沒有共識。在這邊,我會使用官方的規則,所以你,親愛的讀者,也要。
首先你要知道的是bridi否定,會這樣稱呼是因為它表明它所在的bridi不是真的,因此否定了它。將bridi否定的方法是將na擺在句首,後面接上ku,或是直接擺在selbri前面。
- speni = x1 和 x2 在 x3 的習俗下有結婚/是配偶
所以na ku le mi speni cu ninmu表示「我的配偶不是女人」。它完全沒有說我的妻子是什麼,或我有沒有妻子。它只有說我沒有一個同時是女人的妻子。這隱含了一個重要的事情:如果一個bridi的否定為假,那個bridi就必須為真:na ku le mi speni cu na ninmu一定會表示我有配偶,而且她是女人。
bridi否定可以用在所有的bridi上,就算是描述型bridi隱含的bridi也一樣。lo na prenu可以指稱任何不是人的東西,所以它可以是棒球、人面獅身像或是適合的程度等等。
- bau = sumtcita,從bangu:使用{sumti}的語言
- se ja'e = sumtcita,從se jalge:因為{sumti}
在使用na的時候,常常發生的事是它會把整個bridi否定。如果我說mi na sutra tavla bau le glibau se ja'e le nu mi dotco,我會否定掉太多東西,就無法清楚表示我只想否定「我說話很快」的部分。這個句子可以表示我其實說話很快,但是是不同的原因,像是「我法文說很快因為我是德國人」之類的。要表達得更精確的話,我需要一個方法只否定「我說話很快」的部分,而不把其他的部分否定掉。
如果只要否定bridi的一部份的話,na ku可以在bridi裡面四處移動,放在sumti可以放在的地方。然後它會否定所有它後面的sumti、selbri或sumtcita。如果它在selbri的正前方出現的話,ku可以被省略。
在邏輯語社群中有些人,或許有道理地,認為把na放在selbri前會將整個bridi否定掉,而把naku放在其他任何地方就只會否定它後面的東西很沒道理。但是,在這邊你還是會學到現在的官方標準,也就是na在selbri前會把bridi否定掉。
以下的例子展示了naku的用法:
- na ku ro remna cu verba - 這是錯的:所有人都是小孩
- su'o remna na ku cu verba - 對至少一個人而言這是錯的:他是小孩
可以看到na ku放在cu的前面,因為sumti只能放在cu的前面而非後面。如果我用的是na的話,它就要放在cu的後面--但這樣的話它會否定整個bridi,讓意思變成「這是錯的:至少一個人是小孩」
當na ku向右移動時,量化詞會反過來,也就是:ro會變為su'o。當然,這是要在bridi的意思要被保留的時候。這表示如果na ku放在bridi的最後方的話,只有selbri會被否定,而所有的sumti和sumtcita都會被保留,如底下三個相等的bridi所示:
- ckule = x1 是在 x2 、教導 x3 給學生 x4 、由 x5 經營的學校
- na ku ro verba cu ve ckule fo su'o ckule - 這是錯的:所有小孩都是至少一個學校的學生
- su'o verba cu ve ckule na ku fo su'o ckule - 至少一個小孩是非至少一個學校的學生
- su'o verba cu ve ckule fo ro ckule na ku - 至少一個小孩是,對所有的學校,他不是它的學生
na的相反是ja'a。這個詞幾乎不會被使用,因為這是大部分bridi的預設值。其中一個例外是重複的bridi(下一章)。有時這個詞會用在強調bridi的真實性,像是在la .bab. ja'a melbi=「鮑勃的確很漂亮」
雖然na ku的機制和自然語言的否定很類似,不過有時很難弄清楚哪些東西有被否定,以及這如何影響bridi的意思。也因為如此,na ku很少在bridi開頭之外的地方出現。在大多數要否定特定的部位時,人們會使用另一個方法。這個方法叫做程度否定,是一個精巧而合乎直覺的工具。使用它的時候你只會影響到selbri,因為程度否定的詞,就像se一樣,是和selbri綁在一起的。
程度否定的名字是來自於這些與selbri綁在一起的詞可以放在一條從肯定到否定到表示相反的情況為真的程度線上:
- je'a = 「的確」:純量肯定
- no'e = 「不怎麼」:純量中間點
- na'e = 「非…」:純量否定
- to'e = 「…的相反」:純量相反點
這些詞否定的方式和na不一樣。它們不表示bridi是假的,而是表示某個bridi是真的--同一個bridi,只是selbri不同。這個差別主要是學術上的就是了。例如說,假設我說mi na'e se nelci「我是不被喜歡的」,我其實表示某個selbri適用在我身上,而這個selbri是在nelci的相關程度上。在大多數時候,我們會假設程度線上的事物是互斥的(像是愛-喜歡-不喜歡-恨),所以mi na'e se nelci會隱含mi na se nelci。所以,no'e和to'e應該只在selbri在某個很明顯的程度上時使用:le mi speni cu to'e melbi「我的配偶很醜」很合理,因為我們知道漂亮的相反是什麼;而mi klama le mi to'e zdani「我去我的家的相反」雖然合文法,但是聽者要猜「家的相反」是什麼意思,所以這種表達應該要避免。所以你要如何只否定selbri,而不表示這個selbri在程度線上的某個點是正確的呢?答案很簡單:把na ku移到bridi的最右端,就像前幾行提到過的。這個特性非常有用。有些邏輯語使用者喜歡在selbri前面加上rafsi「nar-」(na的rafsi)--這有一樣的效果,但是我不建議這樣做,因為這樣做會讓原先的brivla看起來變的不熟悉,而且在說話時會變得不容易理解。如果在某些情況下你只想否定selbri,而且想在bridi的尾巴前就表明,可以用實驗性的cmavo、na'ei。這個詞的用法和na'e一樣。
- na'ei = 否定接下來的selbri
試試看翻譯以下的句子:
- 我的配偶不是女人(表示他是男人)
答案:le mi speni cu na'e/to'e ninmu。程度否定隱含我有配偶,而na不如此隱含。
- 我的配偶不怎麼是女人
答案:le mi speni cu no'e ninmu。在這裡程度假定為是從女人到男人。
- 我英文說不快因為我是德國人
答案:mi na'e sutra tavla bau le glibau se ja'e le nu mi dotco
還有,注意當這些詞組合成tanru的時候,程度否定的詞只會影響最左邊的selbri。如果要把它綁在整個tanru或部分的tanru的話,可以用tanru分群詞。
試試看用pelxu zdani vecnu這個tanru來說「我賣不是黃色的家的東西」
答案:mi na'e ke pelxu zdani ke'e vecnu或mi na'e pelxu bo zdani vecnu
當你要回答「美國的國王很胖嗎?」時,所有的否定都會失效。雖然技術上而言可以用na做否定,因為na不隱含美國的國王存在,這樣說有些誤導人,因為聽者可能會以為美國有國王。有一個後設語言否定na'i處理這種狀況:
- na'i = 後設語言否定。在給bridi賦予真值時有地方出錯了。
因為na'i可能在各個地方都會需要,它被賦予類似指示詞的語法,也就是它可以出現在句子的任何地方,並連接在前一個詞或結構。
- palci = x1 在 x2 標準下是邪惡的
- le na'i pu te zukte be le skami cu palci
- 電腦過去的目的(錯誤!)是邪惡的。(可能在反對「電腦可以自主找尋目的」的想法)
既然這是談論否定的章節,我覺得我應該提一下nai。這個詞用在否定次要的文法結構,可以和指示詞、包含時態在內的sumtcita、呼應詞和邏輯連接詞合用。nai否定的規則視其連接的文法結構而定,所以nai的效果在提到那些文法結構時才會一併講。sumtcita是例外,其否定的規則更為複雜,我們也不會在這邊講。
註:在寫這一章時,有提案說要把nai移到CAI這個selma'o裡面,表示nai的語意會跟著其前方的selma'o做變化。
第二十四章:brika'i/代bridi、ko'a
如果我說我叫做麥克,zo .maik. cmene mi,而你要說一個相同的bridi,你要怎麼說?其中一個可能的答案是do se cmene zo .maik.。要是相同的bridi,你要把mi換成do,而且使用有沒有被se轉換過的selbri在這裡沒有差。這是因為bridi並不是那些表達它的詞--bridi是一個概念,一個抽象的命題。我說mi和你說do指稱的是相同的sumti,所以兩個bridi是等價的。
這一章的主題是brika'i,就是sumka'i在bridi上對應的概念。它們是表示整個bridi的詞。在這裡有一件很重要的事情:bridi只由包含sumti、selbri和sumtcita的東西構成。指示詞和ko、ma附帶的語意都不在bridi裡面,所以它們不會被brika'i表示。
brika'i的數量比sumka'i少很多。我們從最常用的系列,稱為GOhA,開始看起:
- go'u = 重複很久以前的bridi
- go'a = 重複以前的bridi
- go'e = 重複前第二個bridi
- go'i = 重複前一個bridi
- go'o = 重複未來的bridi
- nei = 重複現在的bridi
- no'a = 重複外面的bridi
一些GOhA-brika'i。注意在近過去、中過去及遠過去的i、a、u規律。
它們很像是ri、ra、ru這些sumka'i。它們只能表示主要bridi或jufra,而沒辦表示在關係子句或描述性sumti裡的bridi。當然主要bridi可以有關係子句,但brika'i沒辦法只指稱關係子句。
GOhA在文法上表現的很像是selbri,任何可以作用在selbri上的結構都可以作用在它們身上。GOhA的位置結構和它指稱的bridi相同,而sumti預設也是和它指稱的bridi相同。將sumti填入GOhA的sumti位會將它表示的bridi預設的sumti覆寫掉。比較:
A: mi citka lo plise B: go'i - 「我吃蘋果。」「你這樣做。」和
A: mi citka lo plise B: mi go'i - 「我吃蘋果。」「我也這樣做。」
brika'i在回答有xu的問題時很有用:
A: xu do nelci le mi speni B: go'i / na go'i - 「你喜歡我的妻子嗎?」「喜歡。/不喜歡。」xu因為是指示詞,所以不會被複製。
當重複由na做否定的bridi,也就是na在前束範式(第二十七章)、bridi的開頭或在selbri的正前方時,複製na的規則和你可能預期的不一樣:na會被複製,但是brika'i外的na會取代掉複製的na。一些例子:
A: mi na citka lo plise
B: mi go'i = mi na citka lo plise
C: mi na go'i = mi na citka lo plise
D: mi na na go'i = mi citka lo plise = mi ja'a go'i
nei和no'a不常被使用,除了在故意製造難以理解的bridi,像是dei na se du'u le no'a la'e le nei,之外。不過因為nei會重複當前的外側bridi,le nei可以指稱當前外側bridi的x1,le se nei指稱x2,以此類推。
在使用brika'i時,你在複製有人稱sumka'i,像是mi、do、ma'a等的句子時一定要隨時注意,注意不要在複製它們時讓它們指稱到你不想指稱的對象。除了把它們一一替換掉之外,ra'o這個詞在bridi的任何地方都可以讓人稱sumka'i以說話者的視角指稱:
A: mi do prami B: mi do go'i 和 A: mi do prami B: go'i ra'o 等價
剩下的brika'i系列非常容易記得:
- broda = bridi變數1
- brode = bridi變數2
- brodi = bridi變數3
- brodo = bridi變數4
- brodu = bridi變數5
- cei = 定義bridi變數(不是brika'i也不在broda裡)
前五個詞是同一個詞的不同實例。這些詞可以作為存取bridi的捷徑。在說了一個bridi之後,說cei broda會將該bridi定義為broda,之後broda就可以在接下來的對話中作為該bridi的brika'i。
既然都講到這個了,sumka'i有一個相當的系列,這應該不是這一章的內容,不過我還是把它們放在這裡:
- ko'a = sumti變數1
- ko'e = sumti變數2
- ko'i = sumti變數3
- ko'o = sumti變數4
- ko'u = sumti變數5
- fo'a = sumti變數6
- fo'e = sumti變數7
- fo'i = sumti變數8
- fo'o = sumti變數9
- fo'u = sumti變數10
還有cei在這系列的對應:
- goi = 定義sumti變數
它們的用法就像是brika'i系列。舉個例子,只要把goi ko'u放在sumti後面,之後那個sumti就可以用ko'u表示。
奇怪的是,這些系列的詞很少依它們原先的用途使用。它們反而很常用來作為範例中不特定的selbri和sumti,此時broda、brode的意思是「任何selbri A」、「任何selbri B」,ko'a系列同理:
「所以,ko'a ko'e broda na ku和na ku ko'a ko'e broda的真值一定都一樣嗎?」「不,不是的。」
第二十五章:邏輯連接詞
如果你問一個邏輯語使用者:「你的咖啡要加牛奶或是糖嗎?」她會回答:「正確。」
這個笑話也許聽起來很聰明,它點出了中文問這種問題奇怪的地方。這個問題的形式是是非問句,但它其實不是。邏輯語當然不能有這種自打臉的狀況,所以我們得找另一種方法來問這種問題。如果你想的話,實在是很難想到一個精確又簡單的方法,而邏輯語看起來會像是挑了一個精確、而非簡單的方法。
要解釋它,我們先考慮兩個bridi:bridi 1:「我想要我的咖啡加牛奶」和bridi 2:「我想要我的咖啡加糖」。這兩個bridi都可以有真偽值,所以就有四種bridi真偽值的組合:
A 1和2
B 1而沒有2
C 2而沒有1
D 1、2都沒有
我其實喜歡我的咖啡中有牛奶,而有沒有糖我沒差。所以,我的喜好可以寫為A真B真C偽D偽,因為A和B對我而言均為真,但C、D都不是。一個更簡潔的寫法會是TTFF,表示真、真、偽、偽。同理,喜歡不甜的黑咖啡的人,其喜好就是FFFT。這個「真」「偽」的組合叫做「真值表」,在這邊參數是兩個語句「我想要我的咖啡加牛奶」和「我想要我的咖啡加糖」。注意參數的順序不能搞混。
在邏輯語,我們使用四個我們認為是最基本的真值表來運作:
A: TTTF(且/或)
O: TFFT(若且唯若)
U: TTFF(無論有沒有)
E: TFFF(且)
在這個例子裡,它們可以被翻譯為:A:不要黑咖啡就好,O:請都加,不然就都不要,U:牛奶,然後我不在乎裡面有沒有糖,以及E:牛奶和糖,謝謝。
在邏輯語,你將表示真值表的詞放在兩個bridi、selbri或sumti中間。這個詞稱為邏輯連接詞。對sumti而言(而且只有對sumti!),這些詞是.a .o .u和.e。多棒啊。例子:「我是美國人和德國人的朋友」就是lo merko .e lo dotco cu pendo mi。
你要怎麼說:「我對你說話,沒有對其他人了」?
答案:mi tavla do .e no drata。注意這表示了「我對你說話」是真的。
另一個:我喜歡起司,無論我喜不喜歡咖啡
- ckafi = x1 是源頭/原料是 x2 的咖啡
答案:mi nelci lo'e cirla .u lo'e ckafi
你應該可以推論真值表一共有十六種可能,所以我們要全部知道的話,我們還要知道十二個。其中八個可以藉由把第一個或是第二個句子否定掉來達成。第一句可以藉由在真值表詞前接上na否定,而第二句可以在詞之後加上nai否定。例如,既然.e表示TFFF,.e nai就一定是「1為真且2為假」,就是FTFF。同理,na .a表示「只要不是『1為真且2為假』就好」,所以是TFTT。要在腦中即時做這種轉換非常困難,所以也許你應該專注在學習邏輯連接詞概念上是如何運作的,然後把邏輯連接詞本身記下來。
有四種真值表無法以以上的方式做出來:TTTT,TFTF,FTFT和FFFF。第一個和最後一個根本沒辦法用邏輯連接詞表達,但反正它們也沒什麼用。使用像這種的邏輯連接詞表示「我喜歡我的咖啡有牛奶FFFF糖」其實就是在說「我不喜歡咖啡」,只是更複雜而已。另外兩個,TFTF和FTFT,可以用在.u前面加上我們的老朋友se,就是將兩個句子對調。像是se .u就是「B,無論有沒有A」,就是TFTF。下面是所有邏輯連接詞的列表:
TTTT: 無法做出
TTTF: .a
TTFT: .a nai
TTFF: .u、.u nai
TFTT: na .a
TFTF: se .u
TFFT: .o、na .o nai
TFFF: .e
FTTT: na .a nai
FTTF: na .o、.o nai
FTFT: se .u nai
FTFF: .e nai
FFTT: na .u、na .u nai
FFTF: na .e
FFFT: na .e nai
FFFF: 無法做出
邏輯上而言,說出一個有邏輯連接詞的句子,像是mi nelci lo'e cirla .e nai lo'e ckafi,和說出兩個bridi以相同的邏輯連接詞連接mi nelci lo'e cirla .i {E NAI} mi nelci lo'e ckafi是等價的。這就是邏輯連接詞在定義時賦予的功能。我們很快就會看到要如何將邏輯連接詞作用在bridi上面。
在邏輯連接詞的核心前加上j,它就可以連接兩個selbri。一個例子是mi ninmu na jo nanmu「我是男人或女人,但不會同時是兩個」
- ninmu = x1 是女人
這是tanru內部的,就是指它會將selbri稍稍綁在一起,就算它們形成了tanru:lo dotco ja merko prenu的意思是「德國或美國人」,而會被理解為是lo (dotco ja merko) prenu。這樣綁的強度比一般tanru的結合超強一點(但不及專門的分群詞),所以lo dotco ja merko ninmu ja nanmu會被理解為lo (dotco ja merko) (ninmu ja nanmu)。這種selbri邏輯連接詞也可以接在.i後面把兩個句子連接在一起:la .kim. cmene mi .i ju mi nanmu「我叫做金,無論我是不是男人」。.i je這個組合表示兩個句子都是真的,就像是沒有邏輯連接詞時我們會假定的那樣。
困難到不公平的問題:使用邏輯連接詞,你要如何翻譯「如果你叫鮑伯,你就是男人」?
答案:zo .bab. cmene do .i na ja do nanmu 或 「要嘛你不叫鮑伯而且是男人,要嘛你不叫鮑伯而且不是男人,要嘛你叫鮑伯而且是男人。但你不可以叫鮑伯而且不是男人。」唯一不被允許的組合是「你叫鮑伯,但是不是男人」。這也表示,如果你叫做鮑伯,你一定是男人。
如果我們想要翻譯一件非常非常悲傷的事,「我哭了並且給出我的狗」,我們會遇到問題。
如果試著將je放到selbri「給」和「哭」中間,每個詞都會一一對應,但它的意思會變成「我哭出狗並且給出狗」,參見邏輯連接詞的定義。你可以哭出眼淚甚至是哭出血來,但哭出狗就只是沒道理。
不過,我們可以用bridi尾端的事後邏輯連接詞來繞過這個問題。它們做的事情是讓前方的sumti和sumtcita作用在bridi尾端的事後邏輯連接詞包住的兩個selbri上,但後方的sumti和sumtcita就只作用在後面的那個selbri:你可以把它比喻為是將bridi從一顆頭切出兩條尾巴。
bridi尾端的事後邏輯連接詞的形式是gi'V,其中V是真值表的母音。
你要如何把中文的句子正確地翻譯成邏輯語?
答案:mi pu klaku gi'e dunda le mi gerku
ro remna cu palci gi'o zukte lo palci是什麼意思?
- palci = x1 在 x2 標準下是邪惡的
答案:人很邪惡若且唯若他做邪惡的事。
還有一類稱為「事前非tanru內部連接詞」,其形式為在真值表母音前加上g。「事前」在這裡的意思是它們要在它們連接的東西前面出現,所以你在說出它們之前要先想好句子的結構。「非tanru內部」的意思是它可以連接sumti、bridi、selbri或bridi的尾巴,但不能連接同一個tanru中的兩個selbri。為了讓你瞭解這是如何運作的,我將上面的句子重新表達一遍:
go lo remna cu palci gi lo remna cu zukte lo palci
這種結構的第一個邏輯連接詞攜帶了表示真值表的母音。第二個邏輯連接詞一定是gi,和.i一樣,它不攜帶真值表。它就只是分隔兩個被連接的詞而已。如果你想要否定第一個或是第二個句子的話,nai可以接在第一個(如果你要否定第一句)或第二個(如果你要否定第二句)邏輯連接詞的後面。
只要包住的結構有被適當地終止,它使用起來非常有彈性,就像是以下的例子展現的:
mi go klama gi cadzu vau le mi zdani「我去,若且唯若我走,到我家」或「我只能走回家」。注意在這邊vau是必須的,因為這樣才能使le mi zdani同時作用在cadzu和klama上面。
se gu do gi nai mi bajra le do ckule「無論你是否,我不,跑到你的學校」或「我不會跑到你的學校無論你是否這樣做」
tanru內部對應gV的是gu'V。它們的意思一樣,除了它們只能用在tanru內部,而且它們把selbri綁在gi上的強度比平常的tanru分群還強,但不及明確綁定的sumti:
la xanz.krt. gu'e merko gi dotco nanmu 和
la xanz.krt. merko je dotco nanmu 是等價的
所以你已經讀了好幾頁,就為了學習「你的咖啡要加牛奶或是糖嗎?」的邏輯語的先備知識。在邏輯語,你就將邏輯連接詞以疑問邏輯連接詞取代,然後就像ma一樣,它會要求聽者去填入正確的回覆。很不幸地,這些疑問邏輯連接詞的形狀並沒有和它們詢問的邏輯連接詞配得很好:
- ji = 疑問邏輯連接詞:詢問sumti邏輯連接詞(A)
- je'i = 疑問邏輯連接詞:詢問tanru內部的selbri邏輯連接詞(JA)
- gi'i = 疑問邏輯連接詞:詢問bridi尾端的邏輯連接詞(GIhA)
- ge'i = 疑問邏輯連接詞:詢問事前非tanru內部邏輯連接詞(GA)
- gu'i = 疑問邏輯連接詞:詢問事前tanru內部邏輯連接詞(GUhA)
所以…你要怎麼問一個人她想要糖或是牛奶在她的咖啡裡?
- ladru = x1 是/包含來自 x2 的牛奶
- sakta = x1 是/包含來自 x2 、成分是 x3 的糖
可能的答案:sakta je'i ladru le do ckafi,不果我覺得沒那麼優雅但比較像中文的do djica le nu lo sakta ji lo ladru cu nenri le do ckafi應該也可以。
第二十六章:非邏輯連接詞
「邏輯連接詞」的「邏輯」表示邏輯連接詞和真值表之間有緊密的關係。但是不是所有有用的連接詞都可以用真值表定義,所以除了邏輯連接詞外還有其他的連接詞。
邏輯連接詞表達的意思是以兩個不同的bridi以該連接詞連接來定義。例如mi nitcu do .a la .djan.的意思被定義為和mi nitcu do .i ja mi nitcu la .djan.等價。把這個定義記下來很有用,因為這表示有時候sumti無法以邏輯連接詞連接而不改變意思。考慮以下句子:「傑克和喬寫了這齣戲。」一個可能的翻譯嘗試會是ti draci fi la .djak. e la .djous.
- draci = x1 是關於 x2 ,由 x3 寫成,對於聽眾 x4 ,演員是 x5 的戲劇
這個翻譯的問題是它的意思其實是ti draci la .djak. ije ti draci la .djous.,而這不是真的。傑克或喬都沒有寫它,他們是一起這樣做的。在這邊我們想要的是一個群體,以及可以把傑克和喬組成群體的方法。這和真值表沒什麼關係,所以我們得用非邏輯連接詞,在JOI這個selma'o裡面。我們很快就會回到傑克和喬的問題,現在我們先看看JOI的四個成員:
| ce | ce'o | joi | jo'u | |
| 結合後視為: | 集合 | 序列 | 群體 | 不同個體 |
這些詞的功能很直白:lo'i remna jo'u lo'i gerku會分配性地考慮人的集合和狗的集合(將集合視為個體)。記得第二十二章(量化)有提到,「分配性」表示對群體是對的事物對群體中的每個個體也都是對的。同理loi ro gismu ce'o loi ro lujvo ce'o loi ro fu'ivla是由所有gismu構成的群體,接上所有lujvo構成的群體,接上所有fu'ivla構成的群體形成的序列。就像是JOI裡面所有有隱含順序的詞一樣,se可以放在ce'o前面將順序調換:A ce'o B和B se ce'o A的意思一樣。
你要如何正確地翻譯「傑克和喬寫了這齣戲」?
答案:ti draci fi la .djak. joi la .djous.
JOI裡面的cmavo使用上很有彈性:它們可以做為sumti連接詞,也可以做為tanru內部連接詞,所以它們可以拿來連接sumti、selbri和bridi。這個彈性也就表示在使用JOI時必須小心使用正確的終止詞。
lo dotco jo'u mi cu klama la dotco gugde這個bridi出了什麼問題?
答案:jo'u放在selbri的後方,所以它會期待它的後方是一個selbri,但它後面不是。如果ku在連接詞前出現的話,它就會是合文法的了。
如果使用了許多JOI的話,bo和/或ke可以用來覆蓋正常情況下由左而右的結合規則。
- mi joi do ce'o la .djak. joi bo la .djous. cu pu'o ci'erkei damba lei xunre
- 我和你,然後傑克和喬要和紅隊競技
比對
- mi joi do ce'o la .djak. joi la .djous. cu pu'o ci'erkei damba lei xunre
- 我和你然後傑克,要和喬一起和紅隊競技
將bridi用JOI串起來可以表示bridi一些有趣的關係:
- la .djak. morsi ri'a lo nu ri dzusoi .i joi le jemja'a po ri cu bebna
- 傑克死了,因為他是步兵而且他的將軍是笨蛋。
隱含了這兩個bridi構成的群體是他死亡的原因:如果他是在裝甲車上,或是他的指揮官有能力,他都可以活下來。
- dzusoi = x1 是軍隊 x2 的步兵
- jemja'a = x1 是軍隊 x2 的將軍,軍隊的功能是 x3
- bebna = x1 在 x2 方面很愚笨
非邏輯連接詞也可以以nai否定,此時它表示其他連接詞才是正確的:lo djacu ce'o nai .e'o lo ladru cu cavyfle fi le mi tcati「請別再我的茶裡先倒水再倒牛奶」。很顯然,這並沒有說哪個連接詞是適當的--你有可能會猜se se'o(先牛奶,再水),結果發現.e nai(只要水,不要牛奶)才是對的。
- cavyfle = x1 ,包含 x2 ,流到 x3 ,從 x4
就像是邏輯連接詞可以是非邏輯連接詞的否定一樣,ji或je'i種類的問題可以以兩種連接詞回答:A: ladru je'i sakta le do ckafi B: se se'o(「你的咖啡要牛奶還是糖?」「先後者再前者」)在這時回答ce不會有任何意義,因為你無法把集合放進咖啡裡,而joi(兩個混在一起)和jo'u(兩個都要)的意思會一樣,除非回答的人想要他咖啡中的糖是完整的一塊。
第五個JOI表現得有些奇怪:
- fa'u = 非邏輯連接詞:不混合的有序分配(個別為A和B)
當bridi中只有一個fa'u時,fa'u可以視為和jo'u相等。不過當同一個bridi中有許多fa'u時,fa'u前的結構會互相作用,fa'u後的結構也會互相作用。看個例子:
- mi fa'u do rusko fa'u kadno
- 我和你分別是俄羅斯人和加拿大人
表示mi和rusko一起而do和kadno一起,而沒有表示任何其他配對之間的關係。當然,在這個例子裡,說mi rusko .i do kadno簡單多了。
最後三個JOI將兩個集合接在一起形成新的集合:
- jo'e = A 和 B 的聯集
- ku'a = A 和 B 的交集
- pi'u = A 和 B 的笛卡兒積
它們對一般的邏輯語使用者不會太有用,但我還是把它們放在這裡。
第一個,jo'e,包含了所有集合A和集合B的元素。同時在兩個集合中的元素不會被重複算進去。
ku'a從兩個集合中生出一個新的集合。新的集合只包含同時在兩個集合中的元素。
pi'u比較複雜。A pi'u B這個集合包含了所有可能a ce'o b的組合,其中a是A的成員,b是B的成員。因此,它是成員序列的集合。假設,舉個例子,集合A的成員有p和q,集合B的成員有f和g,則A pi'u B就會是有四個成員p ce'o f、p ce'o g、q ce'o f和q ce'o g的集合。
第二十七章:邏輯語的邏輯:da、bu'a、zo'u和項
現在開始我們講的是高階的邏輯語了。在這一章之後的邏輯語在一般狀晃下很少會需要用到,不過在講到語言與邏輯時會很常冒出來。
邏輯語的這些地方是最新、最複雜、而且最實驗性的,所以你可能會看到許多搖擺的定義、過時的定義,或是作者反對或沒搞清楚的地方。有這些地方我很抱歉。
我要替這一章的主題辯護一下:這一章其實不太是如何在邏輯語裡做邏輯,因為第一,所有語言的邏輯應該都是相同的,而且第二,邏輯本身根本沒辦法在一章的篇幅內講完。這一章講的是一些和邏輯學家使用的相似的結構。這些結構在邏輯語中非常有用。
如果往更細部、更偏門的方向鑽的話,邏輯結構可以變得非常困難,而且在這個語言裡總是有些大家各說各話的角落。
學習這些邏輯結構會需要先學一些本身不是邏輯的結構。我們從zo'u開始:
- zo'u = 把前述範式和bridi分開
在zo'u之前的東西是前述範式,之後的是bridi。不精確地說,前述範式就是bridi前一塊你可以把各個項放進去的地方。「項」是一個中文詞,用來描述一些邏輯語結構:sumti、有或沒有sumti的sumtcita、na ku、以及一些叫做「項集合」、我不想在這課程中提到的糟糕東西。前述範式不是bridi的一部份,但是它裡面的項可以告訴我們bridi的一些資訊。舉個例子,你可以用它來表示主題:lo pampe'o je nai speni zo'u mi na zanru - 「關於沒結婚的戀人:我不認同」。這種句型沒什麼好處,但是有些變化總是比較好。而且,這種句型和中文(和一些其他語言)很相近,也就是這種句型對這些語言的使用者會比較直觀。
- pampe'o = x1 是 x2 的愛人
- zanru = x1 認同 x2 (計畫、事件或行為)
當然,前述範式裡的項和bridi之間的關係很模糊。你可以把前述範式裡的sumti和bridi的關係想成是sumti在bridi裡,前面接著do'e,而前述範式裡的sumtcita就像是它們在bridi裡一樣。你也可以把和bridi的關係很不明確的項放在前述範式裡:
- le vi gerku zo'u mi to'e nelci lo cidjrpitsa - 「對於這邊的狗:我不喜歡比薩。」
- cidjrpitsa = x1 是配料/原料為 x2 的比薩
如果前述範式裡有na ku,它的意思很明確:整個bridi都會被否定,就像是bridi本身以na ku開始一樣。
那麼前述範式會持續多久?它會持續到接下來的bridi結束為止。如果你不想要這樣的話,有兩種方法可以讓它同時作用在許多bridi上面:一種是用某種連結詞放在分隔bridi的.i後方,另一種是將所有的文字都放在tu'e ... tu'u的括號裡面。這些括號基本上就是把所有的bridi黏在一起,讓各種結構可以作用在它們上面。
講了zo'u,我們可以使用的第一批「邏輯」的詞如下:
- da = 邏輯量化的存在性sumka'i 1
- de = 邏輯量化的存在性sumka'i 2
- di = 邏輯量化的存在性sumka'i 3
這些詞都一樣,就像是數學中的變數x、y、z。但是一旦你定義了它們,它們就會一直指稱相同的東西。這些詞會在前述範式裡被定義,所以當前述範式的作用範圍結束時,這三個詞的定義就取消了。
da、de和di可以指稱任何的sumti,所以除非限縮它們的範圍,不然它們沒什麼用。限縮它們最重要的方法就是去量化它:它們叫「邏輯量化的存在性sumka'i」不是叫假的。它們是sumka'i,它們在量化時最有用,而且它們是存在性的。「存在性的」是什麼意思?這個的意思是它們預設的作用是斷言某物存在。例子:
pa da zo'u da gerku在前述範式裡有pa da,表示「存在一個東西使得:」,然後da,現在已經定義了,出現在da gerku這個bridi裡面。翻譯成中文就是:「存在一個東西是狗」。這顯然是錯的,地球上有大約四億隻狗。如果da系列的詞沒有被量化,su'o是預設值。所以da zo'u da gerku表示「存在至少一個東西是狗」,這就是對的了。注意在這裡,量化要更精確或更不精確才會是對的:顯然一隻狗存在,但在邏輯語中,pa da zo'u da gerku表示不僅一隻狗存在,而且不超過一隻狗存在。
存在性sumka'i有一些特定的規則:
- 如果ro在da前面出現,它表示的是「所有存在的東西」。
- 很重要地,使用存在性sumka'i只斷言它在其『真實的領域』存在。所以,so'e verba cu krici lo du'u su'o da crida並不表示da crida,因為其真實的領域只在du'u-抽象裡面。大致上來講,抽象自己有真實的領域,所以在抽象裡用da系列的詞通常是安全的。
- 如果同一個變數被量化許多次的話,第一個量化的效果會持續到最後:之後出現的該變數,如果有量化,指稱的一定得是該變數在第一次出現時指稱的東西,如果沒量化,變數就會獲得其第一個量化詞。例子:ci da zo'u re da barda .ije da plexu表示「存在三個東西,使得其中的兩個很大,而且三個都是黃色的」。re da,因為在ci da的後面,只能指稱三個講過的東西中的兩個。當da出現而沒有量化詞時,量化詞會被認定為是ci。
- 如果前述範式裡有許多項的話,項一定是由左往右讀。有時這會影響到意思:ro da de zo'u da prami de表示「對於所有存在的X,對於至少一個東西Y,X愛Y」,就是「所有東西都至少愛一樣東西」,這裡的「東西」可以是任何東西,包含東西本身。注意在這邊,對於不同的da,de可以指稱不同的東西--de指稱的東西視da而定。因為da在de之前,所以不同的東西可以愛不同的東西。如果我們把前述範式中的da和de位置互換,結果就會不同:de ro da zo'u da prami de = 「對於至少一個東西Y,對於所有存在的X,X愛Y」,表示「存在一個所以東西都愛的東西」。
當然,這兩個主張都完完全全是錯的。有很多東西並不愛任何東西--石頭或抽象概念就是。同理,不可能會有東西是所有東西都愛的,因為「所有東西」包含了沒有意識的東西。我們需要另一個可以限制變數指稱範圍的方法。其中一個好方法就是讓它們成為關係子句的主詞:
ro di poi remna zo'u birka di = 「對於所有是人類的東西X:X有一個或多個手臂。」或「所有人都有手臂」,這是對的,至少在潛在、不考慮時間的狀況下是如此。
- birka = x1 是 x2 的手臂
當使用限縮過的邏輯「存在性」變數時,必須記得一件事:除非有no或ro作為量化,不然這種句子隱含da指稱的東西一定「確實存在」。所以,任何沒有否定,而且da指稱的東西不存在的句子必為偽。
ro da在原先的定義裡也隱含存在性,不過現在通常認為它和no da naku「不存在…不…」等價。人們認為無論變數指稱什麼,等價性比讓ro的用法接近自然語言還要重要。
事實上,定義變數不需要用到前述範式。你可以直接把它像是sumti一樣放進bridi裡面,並在那邊對它量化。你只需要在它第一次出現時量化它就是了。所以,前面關於人有手臂的句子可以寫成birka ro di poi remna。不過變數的順序還是很重要,所以前述範式可以讓你在不動到bridi的情況下把變數的順序弄對。當你有許多變數時,前述範式常常是好主意。
第二種邏輯詞和我們剛剛看過的那三個基本上一樣,只是它們是brika'i而非sumka'i:
- bu'a = 邏輯量化的存在性brika'i 1
- bu'e = 邏輯量化的存在性brika'i 2
- bu'i = 邏輯量化的存在性brika'i 3
它們的使用方式和另外三個基本上一樣,只是有幾點要注意的地方:
因為只有項可以出現在前述範式裡,這些brika'i需要量化詞將它們變為sumti。不過在前述範式裡量化時,量化詞的作用和作用在一般selbri上的量化詞非常不一樣:它不量化可以放在selbri的x1的東西,而是直接量化可能的selbri的數量。一樣,預設的量化詞是su'o。所以re bu'a zo'u的意思不是「對於兩個在X關係的東西:」,而是「對於兩個關係X:」
直接看bu'a實際使用的例子:
ro da bu'a la .bab. = 「對於所有存在的X:X和鮑伯至少有一種關係」=「所有東西都和鮑伯以至少一種方式相關」。一樣要注意順序很重要:su'o bu'a ro da zo'u da bu'a la .bab.的意思是「至少有一種關係,使得所有存在的東西和鮑伯都有那種關係」第一個句子是對的--對於任何東西,你的確都可以編出一個selbri表示一個叫鮑伯的人和那個東西的關係。但後者我就不確定了--我不確定你是否可以編出一個關係把任何東西,無論它是甚麼,和鮑伯連接起來。
一個量化selbri的例子:
ci'i bu'e zo'u mi bu'e do --「對於無限種關係:我和你在所有那些關係裡面」或「我和你之間有無限種關係」
不過,你不能在bridi裡直接量化selbri變數,因為這樣它會變成sumti:mi ci'i bu'a do不是bridi。有些情況下這樣會遇到問題--第二十九章會教你如何克服這些問題。
第二十八章:類別
接下來的三章會討論語意--如何理解特定結構的意思。這一章會討論不同sumti類別的意思,而且內容會很哲學但有些模糊。接下來的兩張會討論抽象,就算你在二十二章之前就已經熟悉它了,當我解釋它們的語意及文法特性時會變得很技術性。
教(或學)語意比教語法難多了,尤其是在邏輯語。在邏輯語,語法是非黑即白的,但語意不是。所以,我必須要重複前面的聲明:底下的內容不是官方的,而是一些對語言的(有認知的)意見。
錯誤的語法在邏輯語中很容易發現--事實上其正確與否是沒有歧義的。相對的,說一個jufra語意上是錯的就像是說那位使用邏輯語的人對世界的想法是錯的。說「你不能說X」和「你不能這樣理解X,你要這樣理解」完全不一樣。在了解語言、或構造語言的句子時加上這些限制很容易層層導致創造力上的限制,甚至是假定一種哲學觀點,而將其他的排除在外。
那我們幹嘛在教科書中放入語意的標準?我們不能讓說話者想說什麼就說什麼,而讓聽者自由決定他聽到的是什麼意思嗎?
這是程度的問題。講個極端的狀況,如果沒有任何語意的標準,那麼任何東西都可以表示任何東西,那麼對話就都會沒有意義。在任何要促進溝通的語言內,一個人必須要可以以一種可以信任他的訊息以想要的方式被理解的方式表達。邏輯語語意的標準不是為了讓人不說A,而是為了避免有人說B,其他人卻覺得他表示的是A。
這一章是關於類別的。「類別」,不精確的翻譯是klesi,被邏輯語使用者用來描述sumti描述事物存在的本質。這個本質是,而且必須和用其他語言(像是中文)描述事物的本質相同。不過,在邏輯語中,不同製造sumti的方法表示了sumti的類別,所以在中文我們可以忽略sumti的本質,邏輯語使用者卻不得不和它們打交道。
在講到類別時,邏輯語使用者常常會提到sumti「到底是什麼」。我們必須記得,這打從一開始就沒什麼哲學的立論基礎。從唯物主義的角度來看,由粒子和波組成的自然世界對不上人類對,舉個例子,恨意的理解。畢竟人對恨意的理解並不是以某特定粒子或特定腦部活動所定義的。這是一個完全抽象的概念。同樣的,以極端歸納法(像是休謨)的角度來看,所有人類經驗都是隨時間的主觀印象--一長串事件,或是也有人說是一堆感質(這是「綠的」,這是「脆的」,這是「圓的」,這是「美味的」→這是蘋果)。這個觀點對不上人類對,舉個例子,貓的理解。畢竟貓就算沒有觸發人的感質還是會存在,而且不同的貓會觸發不同的感質,而且貓的死亡會將貓特有的感質從貓身上抽離。
換句話說,你雖然可以採取宣稱物體和概念不存在而哲學上前後一致的世界觀,這個世界觀對處理人間的事情沒什麼用:在我們的生活中,我們就是會需要去指稱物體,並且假裝它們就是存在。有一個有名的故事是,有一位叫做塞繆爾·詹森的哲學家,在為另一位哲學家提出的物質世界不存在、哲學上無法反駁的解釋時,憤怒地踢一塊石頭,大叫:「我『這樣』反駁他!」
在邏輯語,大多數的sumti都是由selbri以某種方式變過來的,表示sumti的核心是selbri,一個事物「做」的事。太陽通常不會被稱為la solri「太陽」,而是被稱為lo solri「是太陽的東西」。這隱含了一些令人困惑的哲學議題:之前提過,「是貓」的意思或是怎麼樣叫做「開始是貓」或「結束是貓」非常、非常模糊。一則小故事《Tlön, Uqbar, Orbis Tertius》描述了一個具有這種特性的虛構語言,該語言表達「月亮從海上升起」的方式是使用類似的動詞/副詞衍生的名詞:「是月亮,在流動物的後方,向上」。在那則故事中,該語言幾乎導致社會崩潰,因為該語言隱含的世界觀無法處理在地球上遇到的真實物品。
講了這麼多,重點是:要精確地定義各種sumti類別是不可能的事,因為這些類別對不上真實世界。只是在說話時,我們還是需要類別。
類別有可能有無限多種,不過我只會在這邊講邏輯語最常遇到的:
物品應該是最容易理解的,就算它們很難由哲學上被定義。它們一定佔據了時空中的某個位置,不過它們會被認為在時間上是持續的。也就是,物品不會被認為是暫時的:香蕉在熟成的過程中一直保持著香蕉的屬性,直到它被分解掉而不是香蕉了為止。如果你可以凍結香蕉的時間的話,它們在凍結的時間內會一直是香蕉。
事件,像是物品一樣,佔據了時空中的某個位置,但是事件是隨時間發展的:時間和空間一樣重要。香蕉可以被視為事件,不過在這個時候,「是香蕉的事件」是由香蕉隨時間經過的改變組合而成的,而使香蕉是香蕉的東西是所有那些沒有改變的東西。把時間凍結也會同時把是香蕉的事件凍結。
函數是一些邏輯語使用者用來描述一群類型的術語。所有的函數都是抽象概念,所以它們本身並不存在於真實世界中。如何做出這些東西是第三十章的事,在這邊,我們只關心它們的語意。
selbri應該是你已經很熟悉的東西了。它表示一個事件或存在的行為。crino可以視為「是綠色」的selbri,而darxi是「打」。selbri本身和參與selbri的sumti是完全不同的。所以,它們不同於任何一件綠色的狀態或打的行為,而可以視為是某種一般化的事件。在不需要selbri的實例時候,就可以使用一般化的事件。舉個例子,如果我在下星期三有一場婚禮,我在思考的就是就是在時空中某個點上的事件(就算婚禮後來因為一些悲傷的事情而沒有發生也一樣);而如果我說我之後打算結婚,我要的就是結婚的行為,所以我想要的是selbri,或是那個selbri作用在我身上。
程度和selbri的文法性質幾乎一模一樣,你在兩章之後會看到。但是在語意上,它們完全不同。程度是指「某物有多適合放入selbri裡」,和selbri本身完全不一樣。程度是某種數字,或是可以精確或不精確地以數字表示,無論衡量的東西實際上有沒有辦法測量。
在無法測量的事情上使用程度抽象量化的正確性有些爭議。所以,「我的綠的程度」一定是合理的,因為它可以用數位相機測量。相較之下,量化「我是鮑伯的朋友的程度」在哲學上可能說不通。一個可以清楚展現selbri和程度在同一sumti上的差別的例子是「我的黑改變了」。當「黑」被視為selbri時,它表示我從「是黑色的」變為「不是黑色的」或反過來。當「黑」被視為程度時,它表示我的皮膚變得更黑或更不黑(像是冬天陽光少的時候)。
概念也許是函數,也許不是,看你問誰。這個「也許是函數」的定位會在第三十章解釋。概念和selbri或程度不同,它無法作用在sumti上。你不能以說一個東西「適合放入一個selbri」或「適合放入一個selbri的程度」的想法,說一個東西「適合放入一個概念」。概念不存在於真實世界中,甚至無法以真實世界的事物表示,相較之下selbri或程度在作用在sumti上時是可以表示的。概念,像是「戰爭的概念」,只在人們的腦中存在,而且會被認為是「戰爭」這個詞的定義。所以「愛」,當作為概念時,會被理解為愛本身,而和愛的人與被愛的人無關。
selbri、程度和概念的差別也許可以以以下例子說明:
當我說「我喜歡愛人」或「我喜歡被愛」時,我說的是selbri。
在「我喜歡我多麼愛人」,我喜歡的是程度,而當我說「我喜歡『愛』」時,我指的是愛的概念。
bridi是一個你也很熟悉的類別。bridi一定不是函數,但之後會看到它和函數有些關係。bridi本身是想像出來的:它們不存在於真實世界中,而是在文本,我們下一個會看到的類別,中。不過,bridi不是由表示它的符號組成的:因為bridi本身是想像出來的,不同的句子可能表達相同的bridi。不同的句子可以是不同的語言,語序不同,或是指稱相同sumti的用詞不同。所以mi do prami/mi prami do「我愛你」、mi ko prami或是第一個句子的do指稱的人說的do mi prami指稱的都是相同的bridi。bridi位置結構中的所有位置一定都填有一個非零值。
文本的概念和bridi的概念是纏繞在一起的。所有bridi都在文本裡面,但不是所有文本都有bridi。你的確可以把文本定義為「包含bridi」的東西,只是這樣在定義bridi時很容易導致循環論證。現在對於「什麼才算是文本」的理解依然非常模糊。和bridi一樣,文本是超越存在的,你可以把它想成是在真實世界外的一個範疇中。雖然你面前的課程一定是文本,但文本不是由印著課程的紙張構成的,也不是由形成儲存這些課程的位元的磁場構成的。這些物理媒介只是表示文本的方法。那麼什麼可以表示文本?詞,顯然。那肢體語言呢?行為可以比文字表現更多文本嗎?我在這個課程中不打算回答,也不打算去碰這些問題。
集合就容易處裡多了。它們比較像是「類別的類別」:一個想像的盒子,裡面打包著一群sumti。而這個盒子本身和裡面的東西關聯性很小。一個很大的集合不代表它裡面的東西很大,而表示它有很多成員。集合擁有的性質很少,所以集合只有在講到類別成員個數、不同類別共享成員個數、成為類別成員的條件等等時會用到。
最後一個類別是真偽值。我看過它的次數屈指可數,而我把它放在這邊只是因為它在下一章討論一些抽象的時候會有一點用。真偽值表示的是一個bridi為真、為偽或兩者之間的任意值。真偽值的本質就是類似「真」、「偽」、「多數為真」的判斷,它很常以數字表示,像是0(偽)、1(真)或0.5(半真半偽),但這只是表示真偽值的一種方式,而非真偽值本身。你也可以將它用紅色到藍色之間的顏色表示。
第二十九章:簡單抽象的語意
有了可以用來討論類別的詞彙,我們可以更加容易地談論抽象的語意了。通常,抽象就是一個被視為某個類別的bridi。我們從我認為是最簡單的抽象開始:
- nu = x1 是BRIDI發生的事件
你已經很熟悉這個詞,也知道它怎麼用了。nu-抽象一定是一個事件,所以它會在時空上的特定點。於是:
- mi catlu lo nu lo prenu cu darxi lo greku
- 我看著人打狗
是正確的,而
- mi kakne lo nu bajra fi lo mi birka
- 我可以做一件用我的手臂跑步的事
是錯的,因為我並不打算隱含某個跑步的事件:你可以跑步是selbri--一個一般化的事件,所以以上邏輯語的句子聽起來應該要和其中文翻譯一樣奇怪。
看一件事件的角度有很多種,所以有另外四個抽象詞也可以形成事件。這四個詞都有nu的意思,不過它們的意思更特定。我在這邊把它們一一帶過:
- mu'e = x1 是BRIDI發生的點狀事件
- za'i = x1 是BRIDI為真的狀態
- pu'u = x1 是BRIDI發展的程序,階段是x2
- zu'o = x1 是BRIDI表示的活動,包含了重複發生的行為x2
這些抽象詞和事件輪廓高度相關。mu'e和事件輪廓co'i一樣會將bridi視為時空中的點狀事件:
- lo mu'e mi kanro binxo cu se djica mi
- 我想要我變健康
帶有一層「變健康的過程沒有被考慮」的語意。如果它包含了痛苦的化療,那麼我可能一點都不想要那個過程。不過,我還是想要「變健康」的點狀事件。
za'i和ca'o很類似,lo za'i BRIDI在bridi開始為真時開始適用,直到bridi停止為真的時候,它就會突然結束,就像ca'o一樣。
za'o za'i mi kanro binxo表示「我變健康」的狀態花太長時間了:表示從我的健康開始變好到我真的達到健康的時間很長很長。
治療本身用pu'u比較好詮釋,它像是事件輪廓一樣把重點放在整個事件隨時間發展的過程。.ii ba zi co'a pu'u mi kanro binxo .oi表示對痛苦的變健康的過程即將開始感到害怕。x2放的是事件階段的序列,可以將不同的階段用非邏輯連接詞ce'o串起來:ze'u pu'u mi kanro binxo kei lo nu mi facki ce'o lo nu mi jai tolsti ce'o lo mu mi renvi表示「某物是一個我變健康的很長的過程,包含了1)我發現2)關於我的某事發生3)我度過。」
最後,zu'o會將抽象視為是由一串重複的行為組成:
- lo za'a zu'o darxi lo tanxe cu rinka lo ca mu'e porpi
- 觀察到的擊打箱子的行為導致了它現在破掉
比用nu來的精確,因為zu'o表明了原因是重複的打擊,而非某次特定的打擊使箱子破掉。
zu'o的x2可以是一個事件或是重複發生的序列。如果你想要表明到非常不必要的程度的話,我們可以說箱子現在破掉是因為lo zo'u darxi lo tanxe kei lonu lafti lo grana kei ku ce'o lonu muvgau lo grana lo tanxe kei ku ce'o ... 等等。
注意mu'e bajra、za'i bajra、pu'u bajra、zu'o bajra和nu bajra之間的差異:跑步的點狀事件強調的是事件有發生,就這樣。跑步的狀態在跑者開始時開始,而在跑者結束時結束。跑步的程序包含了一開始的熱身、中間的維持速度、還有最後的衝刺。跑步的活動則包含了抬起一隻腳、向前移動那隻腳、把那隻腳放下、對另一隻腳重複此動作的循環。所有的這些方面都可以由跑步的事件,nu bajra,表示。
另一個抽象詞是經驗抽象詞li'i:
- li'i = 經驗抽象詞:x1 是 x2 對BRIDI的內在經驗
經驗可以視為是一種事件的類別。它和事件的特性幾乎一樣:它在時空上有位置、它關注它隨時間的發展、而且不是函數。
但是和事件抽象不一樣的是,經驗是純粹精神上的:li'i-抽象在人的心智之外就不存在了。這個差異完全是語意上的,而且把事件和經驗搞混不會被視為像是mi kakne lo nu...的型別錯誤。它不一定會合理,像是lo kacma cu vreji lo li'i lo mi pendo cu cliva kei mi「相機記錄了我對我朋友離開的經驗」。不過,電影的存在依賴於相機可以記錄演員的心境。
我認為像是mi ciksi lo li'i lo mi pendo cu cliva kei mi或lo li'i lo mi tunba cu morsi cu mukti lo nu mi catra等句子是完全合理的。
li'i是從lifri來的,而且它的確是se lifri--一場經驗。
du'u-抽象應該是除了nu之外你最熟悉的抽象了:
- du'u = bridi抽象詞:x1 是BRIDI表達的bridi,以文本 x2 表示
就標準來看,像是真相、謊言、發現的事情或是被相信的事情都是純粹的bridi:
- .ui sai zi facki lo du'u zi citka lo cidjrpitsa
- 耶!我剛剛發現比薩很快就會被吃了!
- mi krici lo du'u la turni cu zbasu pi ro lo munje zi'o
- 我相信主創造了整個宇宙。
發現的事情或是被相信的事情都是抽象bridi表示的真相,所以du'u是合適的。
你可以從du'u的定義中看到,du'u的x2用來表示包含了bridi的文本。之前提過,文本的本質很難被明確認知,但是在實務上,du'u的x2可以做為間接引用:
- .ue do pu cusku ku'i lo se du'u do necli lo ckafi
- 噢!但你說了你喜歡咖啡!
因為我似乎不得不這麼做,這一章會包含真偽值抽象詞,jei。我們來看看它的定義:
- jei = 真偽值抽象詞:x1 是BRIDI的真偽值,由認識論 x2
jei很少用,不是因為真偽值很少用到,而是因為多數邏輯語使用者使用別的方式去獲取它們。真的需要用到jei時候,是在需要一個不是「真」也不是「偽」的真偽值時,也就是幾乎完全不會。我還是給一些例子:
- mi di'i pensi lo jei mi merko
- 我常常在想我是不是美國人
(比對「我常常在想我有多像美國人」,此時使用的是程度抽象,而非真偽值抽象)
- li pi bi jei tinjin cu mikce
- 「Tindjin是醫生」有80%正確。
(管它這什麼意思)
在這一章結束時,su'u是一個通用抽象詞,其x2可以用來表示這個抽象要如何被看待--像是抽象的種類。它已經定義過了,不過我們這邊還是再定義一次:
- su'u = 通用抽象詞:x1 是BRIDI以 x2 看待的抽象
抽象的想法很簡單,所以我給幾個例子就好了:
中文的子句「我愛你」可以是一個sumti,因為它可以做為一個句子的主語或賓語。也可以看出它是抽象而來的。所以它可以被翻譯為lo su'u mi do prami。不過沒有中文的情境的話,你實在很難猜出它想表達的是哪一種抽象。「在我愛你的時候我會死得很開心」將抽象視為在時間中發生的事件,「事實是我愛你」將抽象視為bridi,因此可以是真或偽。「你不知道我愛你多少」將(幾乎一樣的)抽象視為程度。它們可以以su'u的第二個位置明確地區別:
lo su'u mi do prami kei be lo fasnu 是事件。
lo su'u mi do prami kei be lo bridi 是bridi。
lo su'u mi do prami kei be lo klani 是程度。
這樣做的話,所有抽象詞的語意(但不含語法)都可以涵蓋了。不過通常人們會使用其他的抽象詞。
最後,邏輯語使用者J. Cowan將書名《耶穌被釘十字架,視為下坡的腳踏車賽》翻譯成lo su'u la .iecuas. kuctai selcatra kei be lo sa'ordzifa'a ke nalmatma'e sutyterjvi。
第三十章:函數的語義
函數是二到三種抽象的總稱。這個詞不是官方的,但我在這裡還是會用它。
函數的定義和一個可愛的小詞ce'u高度相關。ce'u是填入一個sumti位的sumka'i。不過它只在同時是函數的抽象中有用。同時,所有是函數的抽象都有至少一個ce'u在裡面--就是這讓它們成為函數。ce'u可以省略,這時它會被認為是填在函數中第一個省略了sumti的sumti位,除非情境告訴我們更好的選擇。
那它是做什麼的?我們來看一下它的定義:
- ce'u = 偽量化詞,綁在抽象的其中一個變數上,表示抽象中的空位。
呃,這個定義沒什麼用。我試試看用另一個方法解釋:
將ce'u放在sumti位中會將sumti位留空。和zi'o不一樣,那個位置沒有被刪除,但那個位置就是沒有任何東西--不是特定的東西,不是zu'i,不是zo'e,就是沒有東西。如此一來,空的sumti位就像是中文brivla定義中殘留下來的x1、x2和x3,表示「這裡可以放東西」。
所以mi citka lo ti badna就是「我吃這根香蕉」,而mi citka ce'u是「我吃X」。
當然,「我吃X」沒有任何意義,除非有人把某個東西填進X裡,而mi citka ce'u在邏輯語中也沒有意義。
這種句子要有用,我們需要函數抽象。我們從最常用的開始:selbri抽象ka。我們來看它的官方解釋:
- ka = 性質/特性抽象詞:x1是BRIDI表示的特性/性質。
在我的理解下,這個解釋有點誤導人。我認為ka的解釋應該要如下:
- ka = 性質/特性抽象詞:x1是BRIDI的謂語/selbri(需要最少一個空位,i.e. ce'u)
在這個selbri抽象下,「我吃X」可以有意義,如以下例子所示:
- ckaji = x1 具有selbri x2 表示的特性
lo ti badna cu ckaji lo ka mi citka ce'u「這根香蕉具有以下selbri表示的特性:我吃X」,這個翻譯可以重寫為「這根香蕉適合放入以下selbri:被我吃」,其意思當然就是mi citka lo ti badna「我吃這根香蕉」。
這種陳述要合理的話,ce'u留空的sumti位通常,但不必填入一些東西。陳述的主要selbri,在這個例子裡是ckaji,告訴了我們要如何填入空的sumti位。因為selbri總是用主要selbri的某個sumti將它填滿,邏輯語使用者們曾經爭論說ce'u是如何獲得非零值的。不過現在這個爭議已經差不多平息了:ce'u會把一個sumti位留空,然後主要sumti會把某個東西填進去,而填的是什麼就視selbri而定。
雖然很常這樣做,抽象中ce'u的位置不一定要被selbri填滿才會有意義:lo ka ce'u te vecnu lo finpe本身的意思是「買魚」。這可以在ce'u不被selbri填東西進去的情況下用在句子裡:
lo se lisri cu srana lo ka ce'u te vecnu lo finpe「劇情是關於買魚」。在這邊,srana沒有把任何東西放進ce'u裡,而那個抽象本身就被視為是selbri。
另外一種解釋ce'u的方法是將詞視為λ函數中的變數。舉個例子,考慮以下句子:
la .alis. cu djica lo ka ce'u te vecnu lo finpe「愛麗絲想要買魚」
在這裡,djica的第一個變數是想要某物的東西,在這裡是愛麗絲。第二的變數是愛麗絲想要達成的selbri:買魚。
我們可以將ce'u視為被λ抽象,也就是ka,綁定的自由變數。現在,ka ce'u terve'u lo finpe可以視為一個λ函數:
λ x -> te vecnu(x, lo finpe, zo'e, zo'e)
然後在我們的例子裡djica把λ函數傳給愛麗絲。
λ可以存起來,所以它們可以在各種狀況下被傳著使用:
ca'e ko'a ka ce'u dansu .i mi ko'a ckaji .i do ko'a djica .i ma'a ko'a kakne「這是跳舞。我在做它。你想要它。大家都能做它。」
現在,你可以用ka正確地翻譯「我可以用我的手臂跑步」了。怎麼做?
答案:mi kakne lo ka {ce'u} bajra fi lo mi brika
許多常用的gismu都會吃一個selbri作為sumti,這就表示lo ka很常用。幾個值得注意的例子有troci、djica、zukte、snada和fraxu:
lo xasli na'e kakne lo ka silcu la'e la'oi X-files「驢子無法以口哨吹出X-files的歌」
.e'o ko lo jai se zgike cu fraxu lo ka draxi lo damri ca lo nu do sipna「請原諒音樂家在你在睡覺時打鼓的行為!」
至少一個sumti可以填ka-抽象裡兩個ce'u,就是simxu。以下的jufra是什麼意思?
mi lo pampe'o cu simxu lo ka {ce'u ce'u} gletu
答案:我和我的愛人互相有性行為
當然,雖然ce'u預設是在ka-抽象最開始的地方,這不是一定的。你也可以說:
lo ka .bab. melbi ce'u「『鮑伯對X而言很漂亮』的selbri」,或換句話說「覺得鮑伯很漂亮」
的確,在函數中移動ce'u會產生非常不同的意義:
lo ka ce'u panzi la .maik.「『X是麥克的小孩』的selbri」=「是麥克的小孩」
lo ka la .maik. panzi ce'u「『麥克是X的小孩』的selbri」=「是麥克的父母」
你也可以想到ce'u擺在很奇怪的地方但意思還是很符合直覺的陳述:
mi .e nai do ckaji lo ka lo bruna cu jbocre,在這裡ce'u被省略了,但它最有可能是在lo bruna be ce'u,表示「我,但不是你,具有以下selbri表示的特性:X的兄弟的邏輯語很好」,意思就是「我有邏輯語很好的兄弟,而你沒有」
你可以做一個函數,像是ka-抽象,但把它所有的sumti位都填滿,讓ce'u沒地方去。這樣出來的bridi會很奇怪:
mi kakne lo ka mi merko lo mi bangu「我可以我的語言是美語」,這顯然是型態錯誤。有些人會將沒有任何ce'u的函數視為bridi抽象,所以:
mi krici lo ka mi vrude la cavni和mi krici lo du'u mi vrude la cevni都是「我相信神覺得我是好的」,而且兩個句子都是合文法的,就像是它們的中文翻譯一樣。在我的看法裡,你如果不想用函數,就不要用任何函數抽象詞。如果你的意思是du'u,你就用du'u。
另一個顯然會產出函數的抽象詞是ni。和ka一樣,ce'u可以放在ni-抽象裡面,但和ka不同的是,ni不一定需要ce'u。所以,如果ni-抽象裡沒有ce'u的話,你不能假定它就是被省略了--它可能就是不在那邊。如果主要selbri沒有清楚告訴你如何把ce'u填滿,像是zmadu或mleca,那很有可能根本就沒有ce'u。
在所有其他方面,抽象中的ce'u的運作方式和ka中的一模一樣,所以這個差別是純粹語意上的。ka創造一個selbri,而ni創造一個程度。定義在此:
- ni = 程度抽象詞:x1 是BRIDI在 x2 上的程度
既然你跟ka已經很熟了,ni的用法應該就很直白了:
mi zmadu do lo ni {ce'u} xekri「我在這個程度上超過你:X是黑色的」或「我比你黑」。第二十八章提過了,大家都同意這句話很合理因為人的皮膚的亮度可以由相機測量。可是,有些人無法接受無法測量的東西:
mi zmadu do lo ni mi pendo la .maik.「我比你更是麥克的朋友」。我覺得利用程度表示無法測量的東西是OK的,只是我在兩章前已經跳過這個問題了,所以我不打算在這裡對付它。
不過,有一件事情很清楚:你不能用ni表示適合selbri的物品的數量--它一定表示某個sumti適合selbri的程度。所以:
do mleca mi lo ni panzi ce'u的意思是「你比我還不家長」,而非「你的小孩比我少」
如果你好奇的話(我好奇),前一個例子的zo'e panzi ce'u這個jufra指稱的其實是兩個不同的bridi,因為selbri填了ce'u-空格兩次,一次是do,一次是mi,所以產生了兩個小bridi:zo'e panzi do和zo'e panzi mi。因為這兩個bridi被認為是不同的,兩個zo'e不必指稱相同的東西。
那如果ni-抽象裡沒有ce'u會是什麼意思?嗯,那麼主要selbri就沒辦法把任何sumti填進抽象裡,所以如果和zmadu或mleca一起用的話,它很可能會沒有任何意思。不過,如果ni本身就是主要selbri的話,不用ce'u是完全可以的:
- li du'e ni do nelci lo vanju
- 你太喜歡葡萄酒了。
我們在這一章會看到的最後的抽象詞是概念抽象詞si'o。si'o可以視為是函數,也可以視為不是函數。si'o-抽象一定包含ce'u--事實上,依照我的理解,si'o-抽象包含的就只有ce'u!這些ce'u,和ka或ni不一樣,一直維持是空的而不會被任何selbri填滿。換句話說,這個函數無法作用在任何東西上,所以它才被稱為「也許是函數」。
- si'o = 概念抽象詞:x1 是 x2 對BRIDI的概念
來看一些例子:
lo si'o xebni,因為所有的sumti位都被ce'u填滿了,所以它等價於:
lo si'o ce'u xebni ce'u「『X恨Y』的概念」=「恨的概念」=「恨」
魔戒中的虛構生物炎魔被描述為「黑影與火焰的生物」。在邏輯語中,這個詩意會更強烈:la barlog cu si'o fagri joi manku不只表示它是由黑影與火焰組成的,還暗示它是黑影與火焰的原型,就是衍生出所有其他黑影與火焰的事物。
補充一提,語源上來說,si'o是從sidbo「想法」來的,但是在現在的用法裡,想法會被認為是文本而非概念。
三個抽象詞ka、ni和si'o的差異可以藉著比較更多例子來闡明:
- lo ka crino pluka mi
- 是綠色的使我愉悅
- lo ni crino pluka mi
- {zo'e}綠色的程度使我愉悅(沒有ce'u!)
- lo si'o crino pluka mi
- 「綠」使我愉悅
- mi nitcu lo ka sipna ku lo ka kanro
- 我需要睡眠才能健康
- mi nitcu lo si'o sipna lo ka tavla fi lo sipna
- 我需要睡眠的概念才能談論關於睡眠的東西的事情
我很想寫mi nitcu lo ni sipna ku lo ka vreji ri「我需要{zo'e}睡眠的程度」,只是這意思好像說不太通。
第三十一章:一些沒那麼可愛的詞
對,這一章又是專注在各式各樣詞的上的章節。不過這次,這一章的內容不是由常用程度決定的:和jai或si不一樣,在這一章見到的詞在一般對話中都很少會用到。不過,有些詞在理解之後章節的內容時很重要,所以它們必須在這裡先出現。
在我們看到一些很偏門的詞之前,有一個詞我覺得需要更詳細地解釋一下:kau。
kau在第十二章就解釋過了,不過它真正的意涵不是我們說過的那樣。如果你忘了它是什麼意思的話,我建議你回去看看。很不幸地,我無法解釋kau在主要bridi裡會做什麼,只能解釋它在抽象裡做的事。
一個包含有kau的抽象的bridi宣稱了兩件事:bridi本身做出了一個宣稱,然後抽象裡又隱含地宣稱了kau作用的詞有一個真實的、非零的意思。
這要用例子做解釋:mi pu viska lo nu ma kau cliva le salci(我看到了誰離開了派對)這個bridi宣稱了兩件事。首先,它隱含地宣稱了ma指稱某真實存在的東西。也就是,那個bridi其實宣稱了da cliva le salci(X離開了派對)。第二,主要bridi宣稱了ma指稱的是被看到的東西,也就是邏輯語的mi pu viska lo nu da cliva le salci(我看到了X離開了派對)。
這個原則不只對抽象詞nu及疑問詞ma適用。同樣的原則可以套用在任何其他抽象詞或疑問詞上,如以下bridi所示:
la .bab. na'e birti lo du'u xu kau la .mias. pampe'o(鮑伯不確定蜜雅是否有男朋友)首先表示xu是真實的,也就是該bridi的確有一個正確的真偽值,然後再表示鮑伯不確定的是該bridi正確的真偽值。
kau也可以作用在非疑問詞上,此時那個詞的意義不會被改變。相同的程序依然適用:
- do ca'o djuno lo du'u la krestcen kau cu cinba la .an.
- 你已經知道是克里斯蒂安親了安了。
首先表示la krestcen cu cinba la .an.,然後do ca'o djuno lodu'u la krestcen cu cinba la .an.。
往更偏門的方向走,我們從xi開始。它很容易。
- xi = 下標。將它之後的數字串轉為下標,使它具有指示詞的語法(也就是可以放在任何位置)。
官方鼓勵使用的xi的用法很少,但是因為xi+數字的結構具有指示詞的自由語法,xi可能的用途無邊無際。大致上說,它可以用來列舉任何詞、變數、或語法結構,而不表示它們原先指稱的東西。來看一些例子:
- la tsani cu cusku zo coi .i ba bo la .triliyn. cu cusku lu .ui coi la tsani coi la klaku li'u .i ba bo la klaku cu spusku fi lu coi ty. xi pa .e ty. xi re do'u zo'o li'u
- Tsani說「嗨」,然後Triliyn說「嗨Tsani,嗨Klaku :)」,然後Klaku回應「嗨T1和T2 :P」。
- spusku = x1 回應 x2 (文本)給 x3
因為ty.在標準下是指稱最近一個由T開始的sumti,如果Klaku只說ty的話,它會指稱Tsani。用xi下標可以生成兩個「不同的」ty.。
在一些很罕見的情況下,我們會需要比語言中有的da或bu'a還要多的變數。這時將已有的變數下標可以生成無限多種這種變數。注意沒有下標的變數並沒有被定義為任何有下標的變數。也就是:ty不一定是ty xi pa或ty xi no或任何之類的東西。我覺得這會很少用到,因為任何有超過三個da-變數或十個ko'a-變數的句子會很難讓人理解。
接下來,我們看到ki。我沒印象在IRC中有看到它任何一次過:可能不是它沒用,而是邏輯語的文本很少是它會出現的文類。
- ki = 「黏滯時態」。設定/使用預設時態;建立新的時空/情態參考基準。
任何一串時態詞後面都可以接ki,使這些時態作用在之後所有的bridi上。像是,在說故事的時候,這就可以用來表明預設的時間(沒有任何時態詞時的時間)是故事中的時間。這通常不必要,在童話故事的開頭說出pu zu vu ku,聽者就會假設整個故事都是在很久以前在很遠的地方發生的。舉個例子:
- pu zu vu ki ku zasti fa lo pukclite je cmalu nixli goi ko'a .i ro da poi pu zu vu viska ko'a cu nelci ko'a
- 很久,很久以前,有一個甜美的小女孩。看到她的人都喜歡她。
ki讓我們可以將第二個bridi,以及之後所有bridi的三個時態詞都省略掉。
那麼,如果我們用ki釘住一些時態了,我們要如何把它們拿下來?單獨用ki,所有黏滯時態就都會脫落了。
最後,不同組的時態可以用有下標的ki釘住。如果你有定義了許多組時態的話,你可以用有下標的ki將對應的時態釘住。沒有下標的ki還是會使所有釘住的時態脫落,所以如果你要用許多組時態的話,要小心不要用到沒有下標的ki。
換個主題,底下是一組常用的sumtcita,但是如果不是有免責聲明的話,我不敢試著在這裡定義它。我們先來看看其中兩個的官方定義。
- ca'a = 情態詞:事實性/正在發生的事件。bridi在{sumti}的情況下已經/正在/即將發生
- ka'e = 情態詞:內在能力,可能沒有實現。bridi在{sumti}的情況下是可能的
我們先將ca'a和ka'e區別開來。ka'e的意思是bridi「如果SUMTI的事件已經/正在/即將發生的話是有可能的」。另一方面,ca'a的意思是bridi「如果SUMTI的事件已經/正在/即將發生的話,brisi也已經/正在/即將發生」。
和所有sumtcita一樣,其對應的sumti在sumtcita出現在selbri的正前方時可以省略:
- le vi sovda ka'e fulta .i ja'o bo ri fusra「這顆蛋浮得起來。所以,它壞掉了」
因為它用了ka'e,這個句子並不表示蛋的確有浮,或是之後會浮,只表示了它可以浮。
- pu'i = 情態詞:可以且有;展現出的能力。bridi在{sumti}的情況下可能或不能發生,但的確已經/正在/即將發生
- nu'o = 情態詞:可以但沒有;未實現的能力。bridi在{sumti}的情況下是可能的,但沒有/不會發生
理解ka'e和ca'a後,nu'o的意思就是ka'e je na ku ca'a,而pu'i的意思是ca'a je ka'e na ku。
這四個詞以前是時態詞。當時所有的時態詞都不被認為是sumtcita,而被認為是selbri tcita。不過在現今對邏輯語的理解中,時態詞被認為是sumtcita,和BAI幾乎一模一樣,而selbri tcita就走入歷史了。
因為這四個詞曾經是selbri tcita,它們可以隨時被省略。事實上,因為這四個詞中一定有一個會適用,所以你可以假定一定有一個被省略。通常這個詞是ca'a。事實上,它太常是ca'a了,你可能會想說ca'a怎麼不是預設值。
其中一個原因是因為有些selbri有兩個有用的定義,其中一個隱含ka'e SELBRI,而另一個隱含ca'a SELBRI。fasnu就是一個例子,它可以表示「x1正在發生」或「x1是事件」,其中前者隱含ca'a fasnu而後者隱含ka'e fasnu。
另一個「隱含ka'e」的用途是來迴避一些語言中惱人的哲學問題。selbri只在其所有位置適用時適用。對於有些selbri,像是kabri,這就會出問題。
- kabri = x1 是盛裝 x2 、由 x3 為原料製造的杯子
這個定義暗示如果杯子是空的,x2就不適用,杯子就不是lo kabri了。隱含的ka'e,或更適合的nu'o,可以讓我們迴避這個問題。
抱歉,但就現在而言,這個系列沒有章節了。也許之後會再加。