Leçons d'onde
Rédigées par la klaku, avec l'aide de lojbanistes variés. Basée sur le travail de la .kribacr. Printemps 2013.
Traduites de l'anglais vers le français par Daeldir, lomicmenes et la communauté de duolingo.com (merci en particulier à gourlaouen).
Préface
Ces leçons sont une tentative de développer les « Leçons de Google Wave », un excellent didacticiel consacré au lojban, écrit par kribacr, xalbo, et d'autres, qui, hélas, ne couvrait que les quatres premiers chapitres du présent didacticiel. Il traite des règles les plus récentes du lojban, qui ne sont pas couvertes par de plus anciens cours tels que « What is Lojban? », et « Lojban for Beginners ».
Si le lojban est totalement nouveau pour vous, je vous recommande d'écouter tout les enregistrements de lojban parlé que vous pourrez trouver, tant avant que pendant la lecture de ce didacticiel, afin de vous familiariser avec les sons et les mots du langage. De plus, essayez de prononcer ce que vous lisez avec l'accent lojban si vous le pouvez. Ceci vous aidera à prononcer le lojban.
En suivant ce didacticiel, il est conseillé de prendre des pauses entre les leçons afin de digérer ce que vous avez appris. J'ai essayé de construire ces leçons du simple au complexe, et d'exclure tout mot ou concept qui n'a pas été expliqué dans les leçon précédente. Une fois expliqués, ils sont utilisés librement tout au long du reste du didacticiel. J'exhorte le lecteur à ne pas faire l'impasse sur un contenu incompris : si vous avez une question ou n'êtes pas certains d'une chose, n'ayez pas de complexe à demander à la communauté lojban, qui peut être trouvée sur #lojban sur le réseau IRC Libera, ou sur la mailing-list. Elle sera heureuse d'aider.
Dans ce didacticiel, le texte en lojban est écrit en gras. Les mots empruntés du lojban au français ne sont toutefois pas soumis à cette emphase. Les réponses des exercices sont affichées comme une barre grise. Sélectionnez cette barre pour voir le texte.
Enfin, j'ai autant que possible essayé d'utiliser les mots du lojban pour désigner les constructions grammaticales – sumka'i au lieu de pro-sumti, sumtcita au lieu de modal, et jufra au lieu d'énoncé – parce que j'ai l'impression que les mots français sont souvent soit arbitraires – juste des mots en plus à apprendre –, soit trompeurs – donc pire qu'inutiles. Dans les deux cas, puisque ces mots sont de toute façon spécifiques à l'apprentissage du lojban, il n'ont pas de raison d'exister comme des mots français distinct.
Leçons de lojban – leçon zéro. Sons
La première chose à faire quand vous apprenez une langue étrangère est de vous familiariser avec les sons du langage et leur écriture. Il en va de même pour le lojban. Heureusement, les sons du lojban (phonèmes) sont plutôt simples.
Voyelles
Il y a six voyelles en lojban.
| a | comme dans « papa » |
| e | comme dans « bergère » |
| i | comme dans « machine » |
| o | comme dans « oméga », « automobile » |
| u | comme dans « ou », « loup » |
| y | comme dans « matelot » |
La sixième voyelle, y, est appelée un schwa en linguistique. C'est un « e » très léger, non accentué, juste milieu entre le « e » marseillais (« mateulot ») et le « e » muet parisien (« mat'lot »).
Deux voyelles ensemble sont prononcées comme un son (diphtongue). Par exemple :
| ai | comme dans « canaille » |
| au | comme dans « chaos » |
| ei | comme dans « soleil » |
| oi | comme dans « goy » |
| ia | comme dans « piano » |
| ie | comme dans « pierre » |
| iu | comme dans « sioux » |
| ua | comme dans « quoi » |
| ue | comme dans « couette » |
| uo | comme dans « statu quo » |
| ui | comme dans « oui » |
Les voyelles doublées sont rares. Les seuls exemples sont ii, prononcé comme dans « failli », et uu, prononcé comme dans « Ouhou ! » (quand on appelle quelqu'un, mais pas comme dans « Houhou » : dans le premier exemple, le h est muet, dans le deuxième, le h est aspiré – ce qui se transcrirait en lojban u'u)
Consonnes
Il y a dix-sept consonnes en Lojban, plus une «quasi-consonne». Les consonnes du Lojban sont les mêmes que celles du français, à l'exception du fait que le Lojban n'utilise pas les caractères « H », « Q », « W » ou « Ç ». La plupart des consonnes sont prononcées comme en français, à quelques exceptions près :
|class='wikitable' |- |g |se prononce toujours comme dans « gâteau », jamais comme dans « genoux » (on utilise alors le « j ») |- |s |se prononce toujours comme dans « serpent », jamais comme dans « rose » (on utilise alors le « z ») |- |c |se prononce ch, comme dans « chateau » |- |x |se prononce comme dans l'allemand « Bach », l'espagnol « Jose » ou l'arabe « Khaled » |- |r |se prononce comme dans « arrivederci ». « r » accepte beaucoup de prononciations (à la française, à l'anglaise…) mais la prononciation italienne (r roulé) est préférée |- | |}
La « quasi-consonne » est l'apostrophe «'», qui est prononcée comme le son [h]. Ce son n'existe pas vraiment en français, hormis dans certaines interjections («haha!», «héhé») ou dans certains mots d'origine étrangère comme « maharadja » (dans les mots français comme « haricot », la lettre "h" n'est jamais prononcée). En Lojban, l'apostrophe «'» ne peut apparaitre qu'entre deux voyelles, afin de les séparer et de les empêcher de former une diphtongue. Par exemple, « ui » est normalement prononcé comme « oui », mais « u'i » est prononcé comme « ou-hi ».
Pour être complet, voici la liste des consonnes restantes du Lojban:
b, d, f, k, l, m, n, p, t, v, z, j.
Caractères spéciaux
Le lojban ne requiert aucune ponctuation, mais certain caractères, habituellement utilisés comme ponctuation dans d'autres langues, affectent la manière dont le lojban est prononcé.
Le seul de ces caractères qui soit obligatoire en lojban est l'apostrophe. En fait, l'apostrophe est considérée comme une lettre du lojban.
Un point est une courte pause évitant à deux mots de se confondre l'un dans l'autre. Les règles du lojban rendent facile la fusion de deux mots quand le second commence par une voyelle, et donc, par convention, chaque mot commençant par une voyelle est précédé par un point (les mots finissant par un « y » sont aussi suivit par un point). Le point est ce qu'on appelle un « coup de glotte », justement cette fois-ci, équivalent au « h » de « haricot ».
Les virgules sont rare en lojban, mais peuvent être utilisées pour empêcher deux voyelles de se fondre l'une dans l'autre quand vous ne voulez pas utiliser d'apostrophe, ce qui ajouterais un « h » entre elles. Aucun mot lojban n'a de virgule, mais elle est parfois utilisée dans l'écriture des noms d'autres langues. Par exemple, « no,el. » (Noël), au lieu de « noel. » (qui ressemble alors à « moëlle »), « no.el. » (No; Elle), ou « no'el » (No-hell).
Les lettres capitales ne sont normalement pas utilisées en lojban. Nous les utilisons dans des mots non lojban (comme « Pierre »), quand l'accent tonique d'un mot est différent de celui de la norme lojban. La norme consiste à mettre un accent tonique sur l'avant dernière syllabe. Par exemple, kujmikce (infirmière), est « kujMIKce », et non pas « KUJmikce ». Le nom « Juliette » s'écrirait « juLIET. » si prononcé comme en français, mais « DJUli,et. » si prononcé comme en anglais.
Alphabet
Dans la plupart des manuels, lors de l'apprentissage d'une langue, vous apprenez l'alphabet du langage, et sa prononciation. Les lettres (lerfu) étant plus importantes en lojban qu'à l'accoutumée, autant apprendre leur noms rapidement.
Les consonnes sont simples : le nom d'une consonne est cette lettre, suivie de « y ». Ainsi, les consonnes du lojban, « b », « c », « d », « f », « g »… sont appelées « by. » (beu), « cy. » (cheu), « dy. » (deu), « fy. » (feu), « gy. » (gueu)… en lojban (en utilisant un point, comme décrit dans la partie précédente).
Les voyelles seraient appelées « .ay », « .ey », « .iy »…, si c'était moins difficile à prononcer. Au lieu de ça, elles sont nommée en suivant le son de la voyelle par le mot bu, qui signifie simplement « lettre ». Ainsi, les voyelles du lojban sont : « .abu » (abou), « .ebu » (aibou), « .ibu » (ibou), « .obu » (aubou), « .ubu » (oubou), « .ybu » (eubou).
L'apostrophe est considérée comme une vrai lettre en lojban, et est nommée « .y'y. » (« euheu »… Un peu comme une petite toux).
Le lojban a un moyen de se référer à la plupart des lettres auxquelles vous pouvez penser. Si vous désirez dès maintenant épeler votre nom en lojban, et que celui ci possède un « H », « Q » ou « W », vous pouvez utiliser « .y'y.bu », « ky.bu » et « vy.bu ». Ainsi, « Schwarzenegger » est épelé en lojban :
sy. cy. .y'y.bu vy.bu. .abu ry. zy. .ebu ny. .ebu gy. gy. .ebu ry.
Et épeler ça est une tâche digne du Terminator !
Maintenant, épelez votre nom en lojban (le cas échéant, de la manière la plus proche que vous pouvez avec les 26 lettres que nous venons d'apprendre, et l'apostrophe).
Prononciation « correcte »
Vous n'avez pas à avoir une prononciation précise du lojban, car chaque phonème est distribué de manière à ce qu'il soit difficile de confondre deux sons. Ceci signifie que, pour une lettre, plutôt qu'une prononciation « correcte », il y a une gamme de sons acceptés – le principe général étant qu'un son est bon tant qu'il ne ressemble pas trop à une autre lettre. Par exemple, le « r » lojban peut être prononcé comme en anglais, italien, français…
Cependant, bien que le « r » français soit considéré comme un « r », celui-ci est aussi proche du « x » lojban. Pour comprendre la différence entre ces deux sons, observez la différence entre le son « d » et le son « t » : l'un est vocalisé, l'autre non. La même distinction s'opère entre le « r » français et le « x ». Je vous conseille donc d'opter pour un « r » moins ambigu. Concernant le « r » roulé, deux prononciations sont possible : le « r » espagnol, situé à l'avant du palais, et un « r » plus proche de la gorge, comme celui d'Edith Piaf. Choisissez la prononciation qui vous pose le moins de problème, tant qu'elle ne se confond pas avec une autre lettre du lojban.
Faites aussi attention à bien appuyer les voyelles – mis à part le « y » qui doit être court. La raison en est que les voyelles « non-lojban » peuvent être utilisées pour séparer les consonnes par les personnes qui n'arrivent pas à les prononcer. Par exemple, si vous avez un problème avec le « zd » de « zdani » (maison), vous pouvez dire « zɪdani », avec un « ɪ » très court, mais le « i » final long.
Noms lojban (cmevla)
Dans les films où les protagonistes n'ont pas de langue commune, ils commencent souvent par dire des choses telles que « Moi Tarzan », ce qui est une manière comme une autre de débuter en lojban. Et donc :
mi'e .rafael.
« Je-suis-nommé Rafael »
« Je suis Rafael »
mi'e est apparenté à mi, qui signifie « moi », « je »… C'est un bon exemple de l'apostrope séparant deux voyelles, prononcé « mi hai ».
Ce Rafael est chanceux : son nom se transcrit directement en lojban, sans changement. Il y a toutefois des règles pour les noms lojban, ce qui signifie que certains noms doivent êtres « lojbanisés ». Cela peut sembler étrange. Après tout, un nom est un nom… En fait, tout les langages font ce genre d'adapation à un certain niveau. Par exemple, les anglais tendent à prononcer « Jose » comme « Hozay », et « Margaret » devient « Magelita » en chinois.
Prenons le nom « Cyril ». Si Cyril essaye d'imiter Rafael, les lojbanistes vont l'appeler « cheuril », ce qui n'est pas très joli. Ici, le « C » est en fait un « s », et le « y » un « i ». Cyril devient, en lojban, « .siril. ».
Certains sons n'existent pas dans certains langages. Ainsi, la première chose à faire est de réécrire votre nom de manière à ce qu'il ne contienne que des sons lojban, et soit écrit comme un mot lojban.
En français, Robin se prononce « raubain ». Et « ain » n'existe pas en lojban. Généralement, on utilisera le « n » pour obtenir la nasalisation. Ainsi, Robin s'écrira « .robin. », Jean « .jan. », et Dupond « .dupon. ». Notez aussi que dans ce dernier cas, le « u » sera prononcé « ou » : « douponne ». Comme le prononcerait un italien !
La langue d'origine du nom est aussi importante : un Michael français transcrira son nom « .mikael. », mais un Michael anglais transcrira son nom « .maikyl. », ou « .maik,l ». Ou encore, pour Robin, en anglais, les voyelles anglaises et américaines sont assez différentes. Le Robin anglais peut être raisonnablement approximé par « .robin. », mais la version américaine est plus proche de « .rabyn. » ou « .rab,n. ». Et à l'intérieur d'un même pays, de nombreuses variations sont possibles. Aussi devriez vous prendre les transliterations données ici avec des pincettes.
Notez aussi que pour les noms de villes, par exemple, on préférera la version locale du nom à la version française. Ainsi, Londre ne sera pas transcrit « .londr. », mais « .london. », et Belgrade sera « .beograd. » plutôt que « .belgrad. ».
Vous avez peut-être noté les deux points qui apparaissent dans chaque nom lojban… Ceux-ci sont nécessaires car sans pause, il peut être difficile de savoir quand le mot précédent finit, et quand le mot suivant débute.
Vous devriez aussi placer un point entre le nom et le prénom d'une personne (bien que ce ne soit pas obligatoire). Ainsi, « Joseph Benard » devient « .jozef.benar. ».
Une règle importante dans la lojbanisation des noms est que la dernière lettre d'un cmevla (nom lojban) doit toujours être une consonne. Encore, ceci a pour but d'éviter la confusion quant à savoir où est la fin d'un mot, et si un mot est ou n'est pas un nom (tout les autres mot lojban finissant par une voyelle). Dans le cas où un mot finit par une voyelle, « s » est souvent ajouté à la fin. Ainsi, « Marie » devient en lojban « .maris. », « Joe » devient « .djos. », et ainsi de suite. Une alternative consiste à supprimer la dernière voyelle, « Marie » devenant « .mar. ».
Une dernière chose : comme nous l'avons vu, l'accent tonique des mots lojban est situé sur l'avant dernière syllabe. Si l'accent tonique d'un nom se trouve ailleurs, des lettres majuscules sont utilisées. Ceci signifie que le nom « Robert » sera écrit différemment suivant qu'il soit anglais ou français : « .roBER. » en français, « .robyt. » en anglais et « .rab,rt. » en américain.
Afin de vous donner une idée de comment tout ceci fonctionne, voici une liste de noms de quelque personnages célèbres dans leur propre langue et en lojban.
Exercice :
Où sont ces lieux ?
- .nu,IORK.
- .romas.
- .xavanas.
- .kardif.
- .beidjin.
- .ANkaras.
- .ALbekerkis.
- .vankuver.
- .keiptaun.
- .taibeis.
- .bon.
- .diliys.
- .nis.
- .atinas.
- .lidz.
- .xelsinkis.
Réponses:
- New York: États-Unis d'Amérique
- Rome: Italie
- Havana: Cuba
- Cardiff: Pays de Galles (Le gallois pour « Cardiff » est « Caerdydd », se qui se lojbaniserait comme « .kairdyd. ».)
- Beijing: Chine
- Ankara: Turkie
- Albequerque: Nouveau-Mexique, États-Unis d'Amérique
- Vancouver: Canada
- Cape Town: Afrique du sud
- Taipei: Taiwan (Note : on utilise « b », et non « p ». Bien qu'en fait, le b en Pinyin soit prononcé p… Mais nous ne sommes pas dans un cours de mandarin !)
- Bonn: Allemagne
- Delhi: Inde (L'hindi pour « Delhi » est « Dillî », ce qui donne « .diliys. » ou « .dili'is. ».)
- Nice: France
- Athens: Grèce (« Athina » en grecque)
- Leeds: Angleterre
- Helsinki: Finlande
Exercise :
Lojbanisez les noms suivant :
- John
- Melissa
- Amanda
- Matthew
- Mathieu
- Michael
- David Bowie
- Jane Austen
- William Shakespeare
- Sigourney Weaver
- Richard Nixon
- Istanbul (indice : les turcs prononcent "Stamboul")
- Madrid
- Tokyo
- San Salvador
Réponses :
Il y a souvent d'autres épellations pour les noms, soit parce que les gens prononcent l'original différemment, soit parce que le son exact n'existe pas en lojban, et que l'on doit choisir entre deux lettres. Ce n'est pas important, du moment que tout le monde sait de qui ou quoi vous parlez.
- .djon. (ou .djan. avec certains accents, et parfois .jon. en français)
- .melisas. (.melisys. en anglais)
- .amandas. (En anglais, suivant les accents, le « a » final peut être un « y », de même pour le « a » initial, et le « a » du milieu peut être un « e ».)
- .matius.
- .maTIYS.
- .mikael. (.maikyl. ou .maik,l. en anglais.)
- .deivyd.bau,is. ou .bo,is. (pas .bu,is. — ce serait alors le couteau Bowie)
- .djein.ostin.
- .uiliam.cekspir.
- .sigornis.uivyr. ou .sygornis.uivyr.
- .ritcyrd.niksyn.
- .stabul.
- .maDRID.
- .tokios.
- .san.salvaDOR. (avec l'accent tonique espagnol)
Leçons
Leçons de lojban – leçon un (bridi, jufra, sumti et selbri)
Une phrase en lojban est appelée un bridi. Elle est le type d'expression le plus couramment rencontré. Un bridi est une déclaration qu'un sujet est en relation avec un objet a travers un verbe, ou que ce sujet possède certaines propriétés.
Exemple : Je mange la pomme. Le verbe 'mange' met en relation le sujet 'je' avec l'objet 'pomme'.
Il est a contraster avec les jufra, qui représentent n'importe quelle expression lojbane, que ce soit des bridi ou d'autres types de phrases. La différence entre un bridi et un jufra est qu'un jufra ne spécifie pas forcément quelque chose, mais un bridi le fait. Ainsi, un bridi peut être vrai ou faux, mais un jufra peut ne pas être qualifié de la sorte.
Pour avoir quelques exemples, en français pour commencer, « Mozart était le meilleur musicien de tout les temps » est un bridi, parce qu'il déclare quelque chose comme vrai, et qu'il implique un objet, Mozart, et une propriété, être le plus grand musicien de tout les temps. Au contraire, « Aïe ! Mon orteil ! » n'est pas un bridi, puisqu'il n'implique pas de relation, et ne déclare donc rien. Ces deux phrases sont toutefois des jufra.
Essayez d'identifier les bridi parmi ces jufra français :
- « Je déteste quand tu fais ça. »
- « Cours ! »
- « Mmmh ! Ça semble délicieux. »
- « Oh non, pas encore… »
- « Maintenant, je possède trois voitures. »
- « Huit heures et dix-neuf minutes. »
- « Ce samedi, oui. »
Réponse : 1, 3 et 5 sont des bridi. 2 ne contient pas d'objet, et les autres ne contiennent pas de relation ni de déclarent de propriétés.
Décomposé en termes lojban, un bridi est constitué d'un selbri (le verbe), et d'un ou plusieurs sumti. Le selbri est la relation ou déclaration à propos des objets, et les sumti sont les objets impliqués dans la relation. Notez que « objet » n'est pas une traduction parfaite de « sumti », parce qu'un sumti peut se référer autant à un objet physique qu'à des choses purement abstraites comme « l'idée de la guerre ». Une meilleure traduction serait quelque chose comme « sujet, objet direct ou indirect » pour les sumti, et « verbe » pour les selbri, bien que, comme nous le verrons plus tard, ce n'est pas non plus optimal.
Nous pouvons maintenant écrire notre première leçon importante :
- bridi = selbri + un ou plusieurs sumti
Dit d'une autre manière, un bridi définit qu'un ou plusieurs sumti sont/font quelque chose expliqué par un selbri.
Identifiez l'équivalent des sumti et du selbri dans ces jufra français :
« Je vais récupérer mes filles avec ma voiture. »
Réponse : selbri: « vais récupérer (avec) ». sumti: « Je », « mes filles », « ma voiture »
« Il a acheté cinq nouveaux shirts à Mark pour à peine deux-cent euros ! »
Réponse : selbri: « a acheté (à) (pour) » sumti: « Il », « cinq nouveau shirts », « Mark » et « deux-cent euros »
Puisque ces concepts sont si fondamentaux en lojban, regardons un troisième exemple :
« Jusqu'à maintenant, l'EPA n'a rien fait à propos de la quantité de dioxyde de soufre. »
Réponse : selbri: « a fait (à propos de) » sumti: « l'EPA », « rien » et « la quantité de dioxyde de soufre »
Maintenant, essayez de créer des bridi en lojban. Pour cela, vous aurez besoin de mots, qui peuvent faire office de selbri :
dunda x1 donne x2 à x3 (sans paiement)
pelxu x1 est jaune
zdani x1 est une maison de x2
Notez que ces mots, « donner », « jaune » et « maison », seraient considérés comme un verbe, un adjectif et un nom, respectivement. En lojban, il n'y a pas ces catégories, et donc pas de distinction. dunda peut être traduit par « donner » (un verbe), « un donneur » (nom), « donnant » (adjectif), ou même comme un adverbe. Ils se comportent tous comme des selbri, et sont utilisés de la même manière.
Vous aurez aussi besoin de quelque mots, qui feront office de sumti :
mi « moi », « je » ou « nous » – Celui ou ceux qui parle/parlent.
ti « ceci » – Une chose ou un évènement proche, qui peut être pointé par le locuteur.
do « tu » ou « vous » – Celui où ceux à qui l'on s'adresse.
Vous voyez la traduction bizarre des selbri ci-dessus — notamment le x1, x2 et x3 ? Ils sont appelés des emplacements de sumti. Ce sont des emplacements où l'on peut mettre un sumti pour compléter un bridi. Compléter un emplacement de sumti signifie que le sumti s'accorde à cet emplacement. Le second emplacement de dunda, par exemple, x2, est la chose qui est donnée. Le troisième emplacement est l'objet recevant le don. Notez comme la traduction de dunda contient le mot « à ». Ceci est dû au fait qu'en français, « à » est utilisé pour signifier le receveur, qui est au troisième emplacement de dunda. Ainsi, quand vous complétez le troisième emplacement de dunda, le sumti que vous y placez est toujours le receveur, et vous n'avez pas besoin d'un équivalent au mot « à ».
Pour exprimer un bridi, vous utilisez simplement le sumti x1 en premier, puis le selbri, puis les autres sumti.
Un bridi habituel : {sumti x1} {selbri} {sumti x2} {sumti x3} {sumti x4} {sumti x5} {et ainsi de suite}
L'ordre peut varier, mais pour le moment, nous nous contenterons de la forme habituelle. Pour dire « Je donne ceci à toi », vous dîtes juste : « mi dunda ti do », avec chaque sumti au bon emplacement.
Donc, comment diriez vous « Ceci est une maison de moi ” ?
Réponse : ti zdani mi
Essayez de répondre à ces quelques autres questions pour vous familiariser avec l'idée de cette structure par emplacements :
Comment traduire « Tu donnes ceci à moi. » ?
Réponse : do dunda ti mi
Et que veut dire « ti pelxu » ?
Réponse : Ceci est jaune.
Plutôt facile une fois que l'on a compris, non ?
Plusieurs bridi les uns à la suite des autres sont séparés par « .i ». « .i » est l'équivalent lojban d'un point, mais se place en général avant le bridi, plutôt qu'après. Il est souvent omis avant le premier bridi, cependant, comme dans cet exemple :
.i Séparateur de phrases. Sépare des jufra (et par conséquent des bridi aussi).
ti zdani mi .i ti pelxu « Ceci est une maison de moi. Ceci est jaune. »
Avant de continuer avec la leçon suivante, je vous recommande de faire une pause d'au moins sept minutes pour digérer ces informations.
Leçons de lojban – leçon deux (FA et zo'e)
La plupart des selbri a de un à cinq emplacements, mais certains en ont plus. Voici un selbri avec quatres emplacements de sumti :
vecnu x1 vend x2 à x3 pour le prix x4
Si je voulais dire « Je vends ceci », il serait ennuyeux d'avoir à remplir les emplacements x3 et x4, qui précisent à qui je vends, et pour quel prix. Heureusement, ce n'est pas nécessaire. Les emplacements peuvent être complétés par zo'e. zo'e nous indique que la valeur de l'emplacement de sumti est indéfinie, parce qu'elle n'est pas importante ou peut être devinée à partir du contexte.
zo'e « quelque chose ». Remplit un emplacement de sumti avec quelque chose, mais ne précise pas quoi.
Ainsi, pour dire « Je te vend », je pourrais dire « mi vecnu zo'e do zo'e » — Je vends quelque chose à toi pour un prix.
Comment diriez-vous « C'est une maison (pour quelqu'un) » ?
Réponse : ti zdani zo'e
Et « (quelqu'un) donne ceci à (quelqu'un) » ?
Réponse : zo'e dunda ti zo'e
Bien. Mais ajouter trois zo'e juste pour dire qu'une chose est vendue prend du temps. Pour cette raison, vous n'avez pas à préciser tout les zo'e d'un bridi. La règle est simplement que si vous omettez des sumti, ils seront considérés comme des zo'e. Si le bridi commence par un selbri, x1 est considéré comme omis et devient un zo'e.
Essayez. Quel est le lojban pour « Je vends. » ?
Réponse : mi vecnu
Et que signifie « zdani mi » ?
Réponse : « Quelque chose est une maison de moi », ou juste « J'ai une maison ».
Comme mentionné plus tôt, la forme n'a pas à être {sumti x1} {selbri} {sumti x2} {sumti x3} {etc.}. En fait, vous pouvez placer le selbri où vous voulez, excepté au début du bridi. Si vous faites ça, le x1 sera considéré omis et remplacé par zo'e. Ainsi, les trois jufra suivant sont exactement le même bridi :
mi dunda ti do
mi ti dunda do
mi ti do dunda
C'est parfois utilisé pour un effet poétique. « Tu te vends toi-même » pourrait être « do do vecnu », qui sonne mieux que « do vecnu do ». Ou cela peut être utilisé pour la compréhension, si le selbri est très long et donc mieux placé à la fin du bridi.
Il y a plusieurs manières de jouer avec l'ordre des sumti dans un bridi. La manière la plus simple est d'utiliser les mots « fa », « fe », « fi », « fo », et « fu ». Notez comme les voyelles sont les cinq voyelles dans l'ordre de l'alphabet lojban… Utiliser ces mots marque le sumti suivant comme étant x1, x2, x3, x4 et x5, respectivement. Le sumti après celui-là sera considéré comme l'emplacement suivant. Pour utiliser un exemple :
dunda fa do fe ti do – « Donné par toi, ceci, à toi ». fa marque le x1, le donneur, qui est « toi ». fe marque la chose donnée, le x2. On continue à compter à partir de fe, ce qui signifie que le dernier sumti est x3, le receveur.
Essayez de traduire la phrase suivante :
mi vecnu fo ti fe do
Réponse : « Je vends, pour le prix de ceci, toi » ou « Je te vend pour le prix de ceci » (probablement en pointant un tas de billets…).
zdani fe ti
Réponse : « Ceci a une maison ». Ici, fe est redondant.
vecnu zo'e mi ti fa do
Réponse : « Tu me vends quelque chose pour ce prix »
Leçons de lojban – leçon trois (tanru et lo)
Dans cette leçon, vous allez vous familiariser avec le concept de tanru. Un tanru est créé quand un selbri est mis devant un autre selbri, modifiant sa signification. Un tanru est en soit un selbri, et peut se combiner avec d'autres selbri ou tanru pour former des tanru plus complexes. Ainsi, « zdani vecnu » est un tanru, de même que « pelxu zdani vecnu », qui est constitué du tanru pelxu zdani et du brivla vecnu. Pour comprendre le concept de tanru, considérez la combinaison de mots français « canne à sucre ». Si vous ne savez pas ce qu'est la canne à sucre, mais connaissez la définition d'une canne, et du sucre, vous ne pouvez pas deviner ce qu'est la canne à sucre. Est-ce que c'est une canne pour touiller le sucre ? Une canne qui produit du sucre ? Une canne qu'on remplit de sucre ? Une canne pour transporter le sucre ? Tout ce que vous savez, c'est que c'est une canne, et qu'il y a une histoire de sucre dans l'équation.
Un tanru ressemble à ça. On ne peut pas dire exactement ce qu'un zdani vecnu est, mais on peut dire que c'est bien un vecnu, et que ça a quelque chose de zdani, d'une certaine manière. Et de n'importe quelle manière. En théorie, l'absurdité de la connexion entre zdani et vecnu importe peu, cela reste un zdani vecnu. Toutefois, ce doit être un vecnu dans le sens ordinaire du terme pour que le tanru soit valide. Vous pouvez interpréter zdani vecnu comme « vendeur de maison », ou mieux « un vendeur type-maison ». Les emplacements de sumti d'un tanru sont toujours ceux du selbri le plus à droite. On dit aussi que le selbri de gauche modifie le selbri de droite.
« Vraiment ? », demandez-vous, sceptique, « Peu importe à quel point la connexion au mot de gauche du tanru est absurde, il reste vrai ? Donc, je pourrais appeler chaque vendeur zdani vecnu, et créer une excuse tordue pour expliquer pourquoi je pense qu'il est un peu zdani sur les bords ? »
Tout à fait. Mais vous seriez un chieur. Ou au moins, vous seriez intentionellement trompeur. En général, vous devriez utiliser un tanru quand la relation entre le mot de gauche et celui de droite est évidente.
Essayez de traduire ceci :
ti pelxu zdani do
Réponse : « Ceci est une maison jaune pour toi ». Encore, on ne sait pas en quoi la maison est jaune : elle est sûrement peinte en jaune, mais ce n'est pas certain.
mi vecnu dunda
Réponse : « Je donne comme-vend. ». Qu'est ce que ça signifie ? Aucune idée. Ça ne veut sûrement pas dire que vous avez vendu quelque chose, puisque par définition, avec dunda, il ne peut y avoir de paiement. Ça doit être un don, mais qui, par certains aspects, est comme une vente.
Et maintenant, quelque chose de totalement différent. Comment faire si je veux dire « Je vends à un allemand. » ?
dotco x1 est allemand/reflète la culture allemande par l'aspect x2
Je ne peux pas dire mi vecnu zo'e dotco, parce que ça mettrait deux selbri dans un bridi, ce qui n'est pas permis. Je pourrais dire mi dotco vecnu, mais ce serait inutilement vague – je pourrais vendre comme un allemand. De la même manière, si je veux dire « Je suis ami avec un américain. », que dire ?
pendo x1 est un ami de x2
merko x1 est américain/reflète la culture des États Unis d'Amérique par l'aspect x2
Encore, la manière évidente serait de dire mi pendo merko, mais cela formerait un tanru, signifiant « Je suis américain comme-un-ami », ce qui est faux. Ce que nous voulons vraiment, c'est prendre le selbri, merko et le transformer en un sumti, afin qu'il soit utilisable avec le selbri pendo. Pour cela, nous utilisons les deux mots lo et ku.
- lo = – Débute la conversion générique d'un selbri en sumti. Extraie le x1 du selbri pour l'utiliser comme un sumti.
- ku = – Termine la conversion du selbri en sumti.
Vous placez simplement un selbri entre ces deux mots, et ils prennent n'importe quoi qui puisse convenir comme x1 de ce selbri, et le transforment en sumti.
Par exemple, les choses qui peuvent remplir le x1 de zdani sont uniquement les choses qui sont des maisons de quelqu'un. Donc, lo zdani ku veut dire « une maison, ou des maison, pour quelqu'un ». De la même manière, si je dis que quelque chose est pelxu, je veux dire qu'il est jaune. Donc, lo pelxu ku se réfère à quelque chose de jaune.
Maintenant que vous avez la grammaire nécessaire pour dire « Je suis ami avec un américain. », comment le dites vous ?
Réponse : mi pendo lo merko ku
Il y a une bonne raison pour que ku soit nécessaire. Essayez de traduire « Un allemand vend ceci à moi. »
Réponse : lo dotco ku vecnu ti mi Si vous omettez le ku, vous n'avez plus un bridi, mais trois sumti. Puisque lo…ku ne peut pas convertir les bridi, le ti est ejecté du sumti, et la « construction lo » doit se terminer, laissant trois sumti : lo dotco vecnu (ku), ti et mi.
Vous devez toujours être attentif avec des jufra comme lo zdani ku pelxu. Si le ku est omis, le processus de conversion ne se termine pas, et on se retrouve avec un simple sumti, composé du tanru zdani pelxu, puis convertit avec lo.
Leçons de lojban – leçon quatre (les attitudinaux)
Un autre concept qui peut être peu familier aux locuteurs français est celui des attitudinaux. Les attitudinaux sont des mots qui expriment les émotions directement. Le principe des attitudinaux puise son origine dans la langue construite "féministe" le Láadan, et était supposée permettre de vraies émotions féminines. L'idée était que l'expression d'émotions féminines était entravée par les langages à dominance masculine, et que si seulement il leur était possible de s'exprimer plus librement, ceci donnerait du pouvoir aux femmes en les libérant du langage.
En lojban, il n'y a pas un tel programme, et les attitudinaux ont plus sûrement été introduits dans le langage du fait qu'ils sont incroyablement expressifs et utiles. Ils ont une grammaire dite « libre », ce qui signifie qu'ils peuvent apparaître quasiment n'importe où dans un bridi sans perturber la grammaire du bridi, ou quelconque construction grammaticale.
Dans la grammaire lojban, un attitudinal s'applique au mot précédent. Si ce mot précédent débute une construction (comme « .i » ou « lo »), l'attitudinal s'applique à la construction entière. De la même manière, si l'attitudinal suit un mot qui termine une construction, comme « ku », il s'applique à la construction terminée.
Prenons deux attitudinaux pour créer quelques exemples :
- .ui = attitudinal : émotion pure et simple : joie - tristesse
- za'a = attitudinal : évidentiel : j'observe directement
Remarquez que dans la définition de .ui, prononcé "oui", deux émotions sont indiquées : joie et tristesse. Ceci signifie que .ui est défini comme la joie, tandis que sa « négation » signifie la tristesse. « Négation » est peut-être le mauvais terme ici. En pratique, la seconde définition de .ui est une autre construction, .ui nai se prononçant "oui naille". La plupart du temps, la seconde définition de l'attitudinal – celle suffixée par nai – est vraiment la négation de l'attitudinal seul. Parfois, pas tant que ça.
- nai = (divers) négation : attaché à un attitudinal, change la signification de l'attitudinal en sa « négation ».
Et quelque selbri de plus, juste comme ça :
- citka = – x1 mange x2
- plise = – x1 est une pomme de race/espèce x2
La phrase « do citka lo plise ku .ui » signifie « Tu manges une pomme, youpi ! » (exprimant surtout que c'est la pomme qui fait plaisir au locuteur, pas l'ingestion, ni le fait que c'était vous). Dans la phrase « do za'a citka lo plise ku », le locuteur observe directement que c'est bien « toi » qui mange la pomme, et pas quelqu'un d'autre.
Si un attitudinal est placé au début du bridi, il s'applique à un « .i », explicite ou implicite, s'appliquant ainsi au bridi entier :
.ui za'a do dunda lo plise ku mi – « Youpi, je vois que tu me donnes une pomme ! »
mi vecnu .ui nai lo zdani ku – « Je vends (et ça craint) une maison. »
Essayez avec quelques exemples. Mais avant, voici quelques attitudinaux supplémentaires :
- .u'u = attitudinal : émotion pure et simple : culpabilité - absence de remords - innocence.
- .oi = attitudinal : émotion pure et complexe : complainte - plaisir.
- .iu = attitudinal : émotion diverse pure : amour - haine.
Qu'avons-nous là ? Un mot est défini par trois émotions ! L'émotion du milieu est accédée en suffixant l'attitudinal par « cu'i ». Elle est considérée comme le « point médian » d'une émotion.
- cu'i = scalaire du point médian de l'attitudinal : s'attache à un attitudinal pour changer sa signification en le « point médian » de l'émotion.
Essayez de dire « Je donne quelque chose à un allemand, que j'aime (l'allemand) »
Réponse : « mi dunda fi lo dotco ku .iu » ou zo'e au lieu de fi
Maintenant, « Aah, je mange une pomme jaune. »
Réponse: « .oi nai mi citka lo pelxu plise ku »
Prenons un autre attitudinal d'un genre différent pour illustrer quelque chose de particulier :
- .ei = Attitudinal : émotion propositionnelle complexe : obligation - liberté.
Donc, simplement, « Je dois donner la pomme » est « mi dunda .ei lo plise ku », non ? Oui ! Quand on y pense, c'est bizarre… Pourquoi tous les autres attitudinaux que nous avons étudiés jusqu'ici expriment les sentiments du locuteur à propos du bridi, mais celui-ci change la signification du bridi ? De manière certaine, en disant « Je dois donner la pomme », on ne précise pas si la pomme est ou non donnée. Pourtant, si j'avais utilisé .ui, j'aurais déclaré avoir donné la pomme, et que ça me rendait heureux. Alors…?
Ce problème, ou pour être exact, comment un attitudinal modifie la condition pour laquelle un bridi est vrai, est sujet à un débat mineur. La règle officielle du « manuel », qui ne sera probablement pas changée, est qu'il existe une distinction entre les émotions « pures » et les émotions « propositionnelle ». Seules les émotions propositionnelles peuvent changer la condition de vérité, tandis que les émotions pures n'en sont pas capables. Pour exprimer un attitudinal d'émotion propositionnelle sans changer la valeur de vérité du bridi, vous pouvez juste le séparer du bridi avec .i. Il y a aussi un mot pour conserver ou changer de manière explicite la condition de vérité d'un bridi :
- da'i = attitudinal : discursif : en supposant - en fait
Dire da'i dans un bridi change la condition de vérité en hypothétique, ce qui est l'usage par défaut d'un attitudinal propositionnel. Dire da'i nai change la condition de vérité en normal, ce qui est l'usage par défaut d'un attitudinal pur.
Donc, quelles sont les deux manières de dire « je donne une pomme » ? (et m'y sens obligé)
Réponse : mi dunda lo plise .i .ei et mi dunda da'i nai .ei lo plise
- dai = modificateur d'attitudinal : empathie (attribue un attitudinal à une autre personne non spécifiée)
Le « sentiment » d'un attitudinal peut être assigné à quelqu'un d'autre en utilisant « dai ». En général, dans un discours normal, l'attitudinal est assigné à celui qui écoute, mais ce n'est pas obligatoire. Aussi, parce que le mot est connoté comme « empathique » (ressentir les émotions des autres), certains lojbanistes supposent à tort que l'orateur doit partager les émotions assignées aux autres.
Exemple : « u'i .oi dai citka ti » – « Ha ha, ça a été mangé ! Ça a dû faire mal ! »
Quelle expression courante peut signifier « .oi u'i dai »?
Réponse : “Aïe, très drôle.”
Et un autre pour tester vos connaissances : tentez de traduire « Il culpabilisait d'avoir vendu sa maison » (souvenez-vous, le temps est implicite et n'a pas besoin d'être spécifié. « Il » peut aussi être évident dans le contexte).
Réponse : u'u dai vecnu lo zdani ku
Enfin, l'intensité d'un attitudinal peut être précisée avec certains mots. Ils peuvent être utilisés après un attidudinal, y compris quand ce dernier a nai ou cu'i en suffixe. Ce qui arrive est moins clair quand ils sont attachés à d'autres mots, comme un selbri : c'est généralement compris comme intensifiant ou affaiblissant le selbri d'une manière non spécifiée.
| Modificateur | Intensité |
|---|---|
| cai | Extrême |
| sai | Fort |
| (none) | Non spécifié (moyen) |
| ru'e | Faible |
Quelle émotion est exprimée avec .u'i nai sai ?
.u'i: attitudinal: émotion pure et simple : amusement - ennui
Réponse : Fort ennui
Et comment pourriez-vous exprimer que vous n'avez pas trop de remords ?
Réponse : .u'u cu'i ru'e
Leçons de lojban - leçon cinq (SE)
Avant de nous intéresser à des constructions plus complexes, il nous faut apprendre un moyen de changer l'ordre des sumti d'un selbri. C'est, comme nous allons le voir, très utile pour faire des sumti descriptifs (le genre avec lo).
Considérons la phrase "J'ai mangé un cadeau.", qui peut avoir du sens si ce cadeau est une pomme. Pour traduire cette phrase nous voudrons d'abord chercher un selbri signifiant "cadeau". Si nous étudions attentivement la définition de dunda, x1 donne x2 à x3, nous réalisons que le x2 de dunda est quelque chose qui est donné - un cadeau.
Donc pour traduire notre phrase nous ne pouvons pas dire mi citka lo dunda ku, parce lo dunda ku fait référence au x1 de dunda qui est le donneur d'un cadeau. A moins d'être anthropophage, ce n'est pas ce que nous voulons dire. Ce que nous voulons c'est un moyen d'extraire le x2 d'un selbri.
C'est un cas où nous allons utiliser le mot se. La fonction de se est d'échanger les places x1 et x2 d'un selbri. La construction se + selbri est elle-même considérée comme un selbri. Essayons avec une phrase ordinaire:
- fanva = x1 traduit x2 du langage x3 dans le langage x4 avec comme résultat de la traduction x5
ti se fanva mi = mi fanva ti
Ceci est traduit par moi (= je traduis ceci). Souvent, mais pas toujours, les bridi utilisants une construction avec se sont traduits en utilisant le passif, puisque x1 est souvent le sujet ou l'objet actif.
se a sa propre famille de mots. Chacun échangeant une place différente avec x1.
| se échange | x1 et x2 |
| te échange | x1 et x3 |
| ve échange | x1 et x4 |
| xe échange | x1 et x5 |
Remarque : s, t, v et x sont des consonnes consécutives de l'alphabet lojban.
Exercice : Utilisant ce nouveau savoir, que signifie ti xe fanva ti ?
Réponse Ceci est une traduction de ceci.
se et sa famille peuvent bien sûr être combinés avec fa et sa famille. Le résultat pouvant être outrancièrement compliqué si vous le voulez :
- klama = x1 va jusqu'à x2 depuis x3 en passant par x4 par le moyen de transport x5
fo lo zdani ku te klama fe do ti fa mi = mi te klama do ti lo zdani ku et comme te échange x1 et x3 := ti klama do mi lo zdani ku
"Ceci va jusqu'à toi depuis moi en passant par une maison." Bien sûr personne ne ferait une telle phrase à moins de vouloir être incompréhensible, ou de vouloir tester le niveau de grammaire lojban de son interlocuteur.
Et ainsi nous en sommes arriver au point où nous pouvons dire "J'ai mangé un cadeau.". Il suffit d'échanger les places des sumti de dunda pour avoir le cadeau en x1, puis d'extraire ce nouveau x1 avec lo…ku. Alors comment le dites-vous ?
Une réponse possible : mi citka lo se dunda ku
Voilà un exemple d'une des nombreuses utilisations de se et de sa famille.
Leçons de lojban – leçon six (abstractions)
Nous n'avons jusqu'à maintenant exprimé qu'une phrase à la fois. Pour exprimer des choses plus complexes, cependant, vous avez souvent besoin de subordinations. Heureusement, celles-ci sont plus simples en lojban que ce que vous pourriez croire.
Commençons avec un exemple : « Je suis heureux que tu sois mon ami. ». Ici, le bridi principal est « Je suis heureux que X. », et le sous-bridi est « Tu es mon ami. ». En regardant la définition de « heureux », traduit par « gleki » :
- gleki = x1 est heureux à propos de x2 (évènement/état)
On peut voir que x2 doit être un évènement ou un état. C'est naturel, parce qu'on ne peut pas être heureux à propos d'un objet lui-même, seulement de l'état dans lequel il est. Mais hélas ! Seuls les bridi peuvent exprimer des états ou des évènements, et seul un sumti peut combler le x2 de « gleki » !
Comme vous l'avez peut-être deviné, il existe une solution. Les mots « su'u … kei » ont une fonction générique de « convertit un bridi en selbri », et fonctionnent juste comme « lo … ku ».
- su'u = x1 est une abstraction de {bridi} de type x2
- kei = fin de l'abstraction
Exemple :
- melbi = x1 est beau pour x2.
- dansu = x1 danse sur l'accompagnement/la musique/le rythme x2.
melbi su'u dansu kei – « belle danse »
Il est souvent compliqué de trouver un bon usage d'un bridi comme selbri. Cependant, puisque « su'u BRIDI kei » est un selbri, on peut le convertir en sumti grâce à « lo … ku ».
Nous avons maintenant les moyens de dire « Je suis heureux que tu sois mon ami ». Essayez !
- pendo = x1 est un ami de x2
Réponse : mi gleki lo su'u do pendo mi kei ku
Cependant, « su'u … kei » n'est pas souvent utilisé. Les gens préfèrent utiliser les mots plus spécifiques « nu … kei » et « du'u … kei ». Ils fonctionnent de la même manière, mais ont une signification différente. « nu … kei » traite le bridi qu'il entoure comme un évènement ou un état, et « du'u … kei » le traite comme un bridi abstrait, pour exprimer des choses comme des idées, pensées ou vérités. Tous ces mots (excepté « kei ») sont appelés des « abstracteurs ». Il y en a beaucoup, mais seule une poignée est régulièrement utilisée. « su'u … kei » est un abstracteur général, et marchera dans tout les cas.
Utilisez « nu ...kei » pour dire « Je suis heureux de parler avec toi. ».
- tavla = x1 parle à x2 à propos du sujet x3 dans la langue x4.
Réponse : mi gleki lo nu tavla do kei ku (remarquez comme le français est aussi vague que le lojban à propos de qui parle.)
D'autres abstracteurs importants sont : « ka … kei » (abstraction de propriété/d'aspect), « si'o … kei » (abstraction de concept/d'idée), « ni … kei » (abstraction de quantité), parmi d'autres. La signification de ceux-ci est un sujet compliqué, et sera discutée bien plus tard, dans la leçon vingt-neuf. Pour le moment, vous devrez vous en passer.
Il est important de noter que certains abstracteurs ont plusieurs places pour les sumti. Par exemple, « du'u », qui est défini comme suit :
- du'u = abstracteur. x1 est le prédicat/bridi de {bridi} exprimé dans la phrase x2.
Les places de sumti autres que x1 sont rarement utilisées, mais « lo se du'u {bridi} kei ku » est parfois utilisé comme sumti pour les citations indirectes : « J'ai dit qu'un chien m'a été donné » peut être écrit : « mi cusku lo se du'u mi te dunda lo gerku ku kei ku », si vous excusez cet exemple bizarre.
- cusku = x1 exprime x2 à x3 par le moyen x4
- gerku = x1 est un chien de la race x2
Leçons de lojban – leçon sept (NOI)
Pendant qu'on y est, il y a un autre type de bridis subordonnés. Ils sont appelés les clauses relatives. Ce sont des phrases qui rajoutent des descriptions à un sumti. En effet, le « qui » dans la phrase précédente a débuté une clause relative en français. En lojban, les clauses relatives viennent en deux parfums, et il peut être utile de distinguer ces deux sortes avant d'apprendre comment les exprimer. Ces deux formes sont appelées les clauses relatives restrictives, et non-restrictives (ou incidentales).
Il serait bon de donner un exemple :
« Mon frère, qui fait deux mètres de haut, est un politicien. »
Cette phrase peut être comprise de deux manières. Je pourrais avoir plusieurs frères, auquel cas dire qu'il fait deux mètres de haut va nous aider à savoir de quel frère on parle. Ou je pourrais n'avoir qu'un seul frère, et juste être en train de vous donner des informations supplémentaires.
En français la distinction entre la première interprétation (restrictive) et la seconde (non-restrictive) n'est pas très marquée. Parfois l'intonation, ou l'utilisation de structures un peu lourde (« Mon frère, celui qui fait deux mètre... ») peut aider à faire la différence. Le lojban utilise les constructions « poi…ku'o » pour les clauses restrictives et « noi…ku'o » pour les non-restrictives.
Prenons un exemple lojban, qui pourrait nous aider à comprendre l'étrange comportement de l'exemple de la leçon cinq, « manger des cadeaux » :
- noi = débute une clause relative Non-restrictive (ne peut s'attacher qu'à un sumti)
- poi = débute une clause relative restrictive (ne peut s'attacher qu'à un sumti)
- ku'o = termine une clause relative
« mi citka lo se dunda ku poi plise ku'o » = « Je mange un cadeau, précisément celui qui (quelque chose) est une pomme ».
Ici, le « poi…ku'o » est placé juste après « lo se dunda ku », donc il s'applique au cadeau. Pour être strict, la clause relative ne précise pas « qu'est ce » qui est une pomme, mais vu que la clause relative s'applique au cadeau, on peut assumer en toute sécurité que c'est le cadeau qui est une pomme. Après tout, dans le contexte de la leçon cinq, ceci semble raisonnable. Si l'on veut être sure que c'est bien le cadeau qui est une pomme, on utilise le mot « ke'a », qui est un sumka'i (un pronom lojban, on en parlera plus tard) représentant le sumti auquel la clause relative est attachée.
- ke'a = sumka'i; se réfère au sumti auquel la clause relative est attachée.
« .ui mi citka lo se dunda ku poi ke'a plise ku'o » = « ☺ Je mange un cadeau qui est une pomme ».
Pour souligner la différence entre les clauses restrictives et non-restrictives, voici un autre exemple :
- lojbo = « x1 reflète la culture/communauté lojbane selon l'aspect x2; x1 est lojbanique. »
« mi noi lojbo ku'o fanva fo lo lojbo ku » = « Moi, qui soit dit en passant suis lojbanique, traduit à partir d'un langage lojbanique. »
Ici, il n'y a pas vraiment de choix à propos de qui « mi » peut indiquer, et le fait que je suis lojbanique est surtout une information supplémentaire, inutile pour m'identifier. Ainsi, « noi…ku'o » est approprié.
Voyons si vous pouvez traduire « Je flirte avec l'homme qui est beau/élégant. ».
- nanmu = « x1 est un homme »
- melbi = « x1 est beau pour x2 selon l'aspect (ka) x3 et le standard x4 »
- cinjikca = « x1 flirte/courtise x2, présentant de la sexualité x3 selon le standard x4 »
Réponse : mi cinjikca lo nanmu ku poi {ke'a} melbi ku'o
Sur une note plus technique, il peut être utile de savoir que « lo {selbri} ku » est souvent définit comme « zo'e noi ke'a {selbri} ku'o ».
Leçons de lojban – leçon huit (élision des famyma'o ; « terminateurs »)
« .au da'i mi djica lo nu le merko poi tunba mi vau ku'o ku jimpe lo du'u mi na nelci lo nu vo'a darxi mi vau kei ku vau kei ku vau kei ku vau » – « J'aimerais que l'américain, qui est mon frère, comprenne que je n'aime pas qu'il me frappe. »
Ignorant le fait que cette phrase est comprise (elle ne devrait pas, vu qu'elle contient des mots qui n'ont pas encore été abordés dans ces leçons), une chose est claire : plus nous apprenons de structures complexes en lojban, plus les phrases se remplissent de « ku », « kei », « ku'o » et d'autres de ces mots qui, en soit, ne convoient pas de sens.
La fonction de ces mots est de signaler la fin d'une construction grammaticale, comme par exemple « convertit un selbri en sumti » dans le cas de « ku ». Un nom français pour ce genre de mot serait « terminateur » (de l'anglais « terminator », « qui termine »). Comme ce mot n'a pas de réelle existence en français, nous allons utiliser le mot lojban : famyma'o. Dans l'exemple ci-dessus, ces mots sont écrits en gras.
Note : Les vau dans l'exemple ci-dessus sont les famyma'o pour « fin de bridi ». Il y a une bonne raison pour que vous ne les ayez pas vu, nous en parlons plus bas.
- vau = famyma'o : Termine un bridi.
Dans la plupart du lojban parlé et écrit, une grande partie des famyma'o est omise (élidée). Ceci nous économise bien des syllabes, à l'oral comme à l'écrit. Cependant, il est nécessaire de bien faire attention quand on élide des famyma'o : dans le simple exemple « lo merko ku klama », supprimer le famyma'o « ku » donnerait « lo merko klama », qui est un sumti composé du tanru « merko klama ». Ainsi, cela signifierais « un voyageur américain » au lieu de « un américain voyage ». L'élision de famyma'o peut provoquer de grosses erreurs si pratiquée de manière incorrecte, et c'est pourquoi vous ne l'avez pas vu avant maintenant.
La règle pour élider des famyma'o est simple, au moins en théorie : « Vous pouvez élider un famyma'o si et seulement si faire ainsi ne change pas la structure grammaticale de la phrase. »
La plupart des famyma'o peuvent être élidés sans problème à la fin d'un bridi. Les exceptions sont évidentes, comme le famyma'o « fin de citation » ou le famyma'o « fin de groupe de bridi ». C'est pourquoi « vau » n'est quasiment jamais utilisé : débuter un nouveau bridi avec « .i » va presque toujours terminer le bridi précédent, de toute façon. « vau » a un usage fréquent, cependant : puisque les attitudinaux s'appliquent toujours au mot précédent, l'appliquer à un famyma'o l'applique à la construction grammaticale terminée entière. En utilisant « vau », il est possible d'utiliser un attitudinal à posteriori et de l'appliquer au bridi entier :
« za'a do dunda lo zdani {ku} lo prenu {ku}... vau i'e » – « Je vois que tu donnes une maison à quelqu'un… J'approuve ! »
- prenu = x1 est une personne ; x1 a une personnalité.
Connaissant les règles basiques d'élision de famyma'o, nous pouvons donc retourner à notre phrase originale et commencer à supprimer des famyma'o :
.au da'i mi djica lo nu le merko poi tunba mi vau ku'o ku jimpe lo du'u mi na nelci lo nu vo'a darxi mi vau kei ku vau kei ku vau kei ku vau
Nous pouvons voir que le premier « vau » n'est pas necessaire, parce que le mot non-famyma'o suivant est « jimpe », qui est un selbri. Puisqu'il ne peut y avoir qu'un selbri par bridi, « vau » n'est pas nécessaire. Puisque « jimpe », comme selbri, ne peut pas être dans la clause relative non plus (seul un bridi par clause, seul un selbri par bridi), nous pouvons élider « ku'o ». De même, « jimpe » ne peut pas être un second selbri dans la construction « le merko poi {…} », donc « ku » n'est lui non plus pas utile. De plus, tout les famyma'o à la fin de la phrase peuvent être élidés, puisque le début d'un nouveau bridi va terminer toute ces constructions de toute façon.
Nous finissons donc avec :
« .au da'i mi djica lo nu le merko poi tunba mi jimpe lo du'u mi na nelci lo nu vo'a darxi mi » – sans aucun famyma'o du tout !
Quand on élide les famyma'o, c'est une bonne idée de s'habituer à « cu ». « cu » est l'un de ces mots qui peut rendre notre vie (lojbane) beaucoup plus simple. Ce qu'il fait : il sépare n'importe quel sumti précédent du selbri. On pourrait dire qu'il définit le prochain mot pour être un selbri, et termine exactement autant de construction nécessaires pour ce faire.
- cu = marqueur élidable : sépare le selbri du sumti précédent, permettant l'élision des famyma'o précédents.
- prami = x1 aime x2
« lo su'u do cusku lo se du'u do prami mi vau kei ku vau kei ku se djica mi » = « lo su'u do cusku lo se du'u do prami mi cu se djica mi »
« Que tu dises que tu m'aime est désiré par moi », ou : « J'aimerais que tu dises que tu m'aime. »
Note : « cu » n'est pas un famyma'o, parce qu'il n'est pas associé à une construction en particulier. Mais il peut-être utilisé pour élider d'autres famyma'o.
L'une des plus grandes forces de « cu » est qu'il devient rapidement facile à comprendre intuitivement. Seul, il ne signifie rien, mais il révèle la structure des expressions lojbanes en identifiant le selbri principal. Dans l'exemple original, avec le frère américain violent, utiliser « cu » avant « jimpe » ne change pas le sens de la phrase du tout, mais la rend plus simple à lire.
Dans les leçons suivante, « cu » sera utilisé quand nécessaire, et tout les famyma'o élidés si possible. Les famyma'o élidés seront entre entre accolades, comme ci-dessus. Essayez de traduire cette phrases :
« .a'o do noi ke'a lojbo .o'a dai {ku'o} {ku} cu jimpe lo du'u lo famyma'o {ku} cu vajni {vau} {kei} {ku} {vau} »
- vajni = x1 est important pour x2 pour la/les raison(s) x3
- jimpe = x1 comprend que x2 (abstraction du'u) est vrai à propos de x3
- a'o = Attitudinal : émotion propositionnelle simple : espoir – désespoir
- o'a = Attitudinal : émotion propositionnelle simple : fierté – modestie/humilité – honte
- dai = modificateur d'attitudinal : empathie (attribue un attitudinal à une autre personne non spécifiée)
Réponse : « J'espère que toi, un fier lojbaniste, comprend que les famyma'o sont importants »
Apartée amusante : la plupart des gens habitués à l'élision des famyma'o le font de manière si instinctive qu'ils doivent être rappelés de l'importance de comprendre les famyma'o pour comprendre le lojban. Ainsi, chaque jeudi a été désigné « jour du terminateur », ou « famyma'o djedi » sur le canal IRC lojban. Durant le jour du terminateur, les gens essayent (et souvent échouent) de se rappeler d'écrire tout les famyma'o, avec quelques conversations très verbeuses pour résultat.
Leçons de lojban – leçon neuf (sumtcita)
Pour le moment, nous nous sommes bien débrouillés avec les selbris dont nous disposions. Cependant, il y a une quantité limitée de selbri, et dans beaucoup de cas, les places pour les sumti ne sont pas utiles pour ce à quoi nous pensons. Comment faire si, par exemple, je veux dire que je traduis en utilisant un ordinateur ? Il n'y a pas de place dans la structure de « fanva » pour préciser l'outil utilisé pour la traduction, puisque, la plupart du temps, ce n'est pas nécessaire. Pas de problème, cette leçon traite de l'ajout de places de sumti aux selbri.
La manière la plus basique d'ajouter des places de sumti est avec « fi'o SELBRI fe'u » (Oui, un nouvel exemple de famyma'o, « fe'u ». Il n'est quasiment jamais nécessaire, et ce pourrait être la dernière fois que vous le croisez.). Entre ces deux mots va un selbri, et comme « lo SELBRI ku », « fi'o SELBRI fe'u » extrait le x1 du selbri qu'il contient. Cependant, avec « fi'o SELBRI fe'u », la place de selbri est convertie, non pas en sumti, mais en « sumtcita », ce qui signifie « étiquette de sumti », avec comme place de structure le x1 du selbri convertit. Ce sumtcita absorbe ensuite le sumti suivant. On pourrait dire qu'en utilisant un sumtcita, on importe une place de sumti d'un autre selbri, et l'ajoute au bridi énoncé.
Note : parfois, surtout dans les anciens textes, le terme « tag », ou « modal » est utilisé pour sumtcita. Ignorez ces piteuses expressions anglaises/françaises. On enseigne un lojban correct, ici.
Bien qu'il soit compliqué de saisir le processus juste en le lisant, un exemple montrera peut-être sa réelle simplicité :
- skami = x1 est un ordinateur pour l'usage x2
- pilno = x1 utilise x2 comme outil pour faire x3
« mi fanva ti fi'o se pilno {fe'u} lo skami {ku}{vau} » – « Je traduis ceci avec un ordinateur ».
Le x2 de « pilno », qui est le x1 de « se pilno », est une place de structure pour un outil utilisé par quelqu'un. Cette place de structure est capturée par « fi'o SELBRI fe'u », ajoutée au selbri principal, puis complétée par « lo skami ». L'idée d'un sumtcita est parfois exprimée en français avec la traduction suivante :
« Je traduis ceci avec-l'outil : un ordinateur »
Un sumtcita ne peut absorber qu'un sumti, qui est toujours le sumti suivant. On peut autrement utiliser le sumtcita seul, sans sumti, auquel cas vous devez le mettre soit devant le selbri, ou le terminer avec « ku ». On considère alors que le sumtcita a le mot « zo'e » comme sumti.
- zukte = x1 est une entité volitive qui accomplit l'action x2 pour la raison x3
« fi'o zukte {fe'u} ku lo skami {ku} cu pilno lo lojbo {ku}{vau} » – « Avec volonté, un ordinateur a utilisé quelque chose lojbanique » (Impliquant peut-être que l'ordinateur est devenu sentiant ? Quoi qu'on ne spécifie pas ce qui avait de la volonté. Peut-être était-ce juste le développeur qui a programmé la machine ? Quel ennui…)
Notez qu'il y a « ku » dans « fi'o zukte {fe'u} ku ». Sans cela, le sumtcita aurait absorbé « lo skami {ku} », ce que nous ne voulons pas.
On peut aussi dire :
« fi'o zukte {fe'u} zo'e lo skami {ku} cu pilno lo lojbo {ku}{vau} »
« lo skami {ku} cu fi'o zukte {fe'u} pilno lo lojbo {ku}{vau} »
ce qui signifie la même chose.
Que veut dire « mi jimpe fi la lojban {ku} fi'o se tavla {fe'u} mi » ?
Réponse : « Je comprend quelque chose à propos de lojban, qui m'est parlé »
Mettre le sumtcita juste devant le selbri le fait s'auto-terminer, puisqu'un sumtcita ne peut absorber qu'un sumti, et pas un selbri. Ce fait sera important dans la leçon suivante, comme vous le verrez.
Malheureusement, « fi'o » n'est pas utilisé très souvent, malgré sa flexibilité. Ce qui est utilisé souvent, cependant, est BAI. BAI est une classe de mots, qui en eux mêmes agissent comme des sumtcita. Un exemple est « zu'e », le BAI pour « zukte ». Grammaticalement, « zu'e » et « fi'o zukte fe'u » sont identiques. Ainsi, l'exemple précédent peut être réduit à :
« zu'e ku lo skami {ku} cu pilno lo lojbo {ku} {vau}. »
Il existe environ 60 BAI, et nombre d'entre eux sont en effet très utiles. De plus, les BAI peuvent aussi être convertit avec « se » et ses amis, ce qui veut dire que « se zu'e » est équivalent à « fi'o se zukte », ce qui a pour résultat encore plus de BAI.
Leçons de lojban – leçon dix (PU, FAhA, ZI, VA, ZEhA, VEhA)
Que le lojban peut paraître étrange à un francophone, quand on lit neuf leçons sans jamais croiser un seul temps. C'est parce que, à la différence de beaucoup de langues naturelles (la plupart des langues indo-européennes, par exemple), tous les temps en lojban sont optionnels. Dire « mi citka lo cirla {ku} » peut signifier « Je mange du fromage. », « J'ai mangé du fromage. », « Je mange toujours du fromage. » ou « Dans un moment, je vais avoir fini de manger du fromage. ». Le contexte permet de détermniner ce qui est correct, et dans la plupart des conversations, les temps ne sont pas nécessaires du tout. Cependant, quand c'est requis, c'est requis, et ça doit s'apprendre. De plus, les temps en lojban sont inhabituels, parce qu'ils traitent le temps et l'espace de la même manière – dire que j'ai travaillé il y a longtemps n'est pas différent, grammaticalement, de dire que j'ai travaillé loin au nord.
Comme dans beaucoup d'autres langages, le système des temps en lojban est peut-être la partie la plus difficile à apprendre. Contrairement à beaucoup d'autres langues, par contre, il est tout à fait régulier et sensé. N'ayez crainte, donc, cela ne va pas impliquer la difficulté d'apprendre à modifier un selbri ou quoi que ce soit d'aussi d'absurde que ça.
Non, dans le système de temps lojban, tout les temps sont des sumtcita (avec lesquels nous venons de nous familiariser, quel heureux hasard ! ). D'accord, d'accord, techniquement, les temps sont légèrement différents des autres sumtcita, mais on n'expliquera pas ça maintenant. Sur beaucoup d'aspect, ils sont comme tout les autres sumtcita. Ils sont terminés par « ku », rendant explicite que PU est terminé par « ku ». Il y a beaucoup de sortes de sumtcita de temps, commençons donc par ceux familiers à un francophone :
- pu = sumtcita : avant {sumti}
- ca = sumtcita : en même temps que {sumti}
- ba = sumtcita : après {sumti}
Ils sont semblables aux concepts français « avant », « maintenant » et « après ». En fait, on pourrait dire que deux évènements ponctuels ne peuvent jamais arriver en même temps, rendant « ca » inutile. Mais « ca » s'étend légèrement dans le passé et le futur, signifiant juste « à peu près maintenant ». C'est parce que les humains ne perçoivent pas le temps d'une manière parfaitement logique, et les temps lojban reflètent ça.
Petite aparté : il a été suggéré de rendre le système des temps lojban relativiste. Cette idée, cependant, a été abandonnée, parce qu'elle est contre-intuitive, et signifierait qu'avant d'apprendre le lojban, on devrait apprendre la théorie de la relativité.
Donc, comment diriez-vous « J'exprime ceci après être venu ici » (en pointant un papier) ?
Réponse : « mi cusku ti ba lo nu mi klama ti {vau} {kei} {ku} {vau} »
Habituellement, en parlant, on ne précise pas à quel évènement cette action dans le passé est relative. Dans « J'ai donné un ordinateur », on peut assumer que l'action est relative à « maintenant », et l'on peut donc élider le sumti du sumtcita, parce qu'il est évident :
« pu ku mi dunda lo skami {ku} {vau} » ou
« mi dunda lo skami {ku} pu {ku} {vau} » ou, plus régulièrement
« mi pu {ku} dunda lo skami {ku} {vau} ».
Le sumti qui remplit le sumtcita par défaut est « zo'e », qui est quasiment toujours comprit comme relatif à la position dans le temps et l'espace du locuteur (ce qui est particulièrement important quand on parle de droite ou gauche). Si l'on parle d'un évènement qui est arrivé dans un autre temps que le présent, il est parfois assumé que tout les temps sont relatifs à l'évènement qui est traité. De manière à clarifier que tout les temps sont relatifs au locuteur, le mot « nau » peut être utilisé n'importe quand. Un autre mot, « ki » marque un temps qui est alors considéré comme la nouvelle référence. Nous apprendrons cela bien plus tard.
- nau = met à jour le cadre spatial et temporel de référence comme étant l'ici et maintenant du locuteur.
- gugde = x1 est le pays du peuple x2 avec le territoire x3
Notez aussi que « mi pu {ku} klama lo merko {ku} {vau} » (« Je suis allé en Amérique ») n'implique pas que je suis toujours en train de voyager aux États-unis, seulement que c'était vrai à un moment dans le passé, par exemple, il y a cinq minutes.
Comme dit plus tôt, les temps spatiaux et temporels sont très proches. Contrastez les trois temps précédents avec ces quatre temps spatiaux :
- zu'a = sumtcita : à gauche de {sumti}
- ca'u = sumtcita : devant {sumti}
- ri'u = sumtcita : à droite de {sumti}
- bu'u = sumtcita : au même endroit que {sumti} (équivalent spatial de « ca »)
- .o'o = attitudinal : émotion complexe pure : patience - tolérance - colère
Que voudrait dire « .o'onai ri'u ku lo prenu {ku} cu darxi lo gerku {ku} pu {ku} {vau} » ?
- darxi = x1 bat/frappe x2 avec l'instrument x3 à l'endroit x4
Réponse : « {colère !} À (ma) droite et dans le passé (d'un évènement), quelque chose est l'évènement d'une personne frappant un chien. » ou « Un homme a frappé un chien à ma droite ! »
S'il y a plusieurs sumtcita de temps dans un bridi, la règle veut que vous les lisiez de gauche à droite, en pensant à un « voyage imaginaire », où vous commencez à un point dans le temps et l'espace qui est impliqué (par défaut, l'ici et maintenant du locuteur), puis suivez le sumtcita un par un de gauche à droite. Par exemple :
« mi pu {ku} ba {ku} jimpe fi lo lojbo famyma'o {ku} {vau} » : « À un point dans le passé, je comprendrais plus tard les famyma'os. »
« mi ba {ku} pu {ku} jimpe fi lo lojbo famyma'o {ku} {vau} » : « À un point dans le futur, j'aurais eu compris les fa'ormaos. »
Puisqu'on ne spécifie pas la quantité de temps que nous parcourons d'avant en arrière, les deux phrases peuvent traiter d'un évènement futur ou passé par rapport au point de référence.
Aussi, si des temps spatiaux et temporels sont mélangés, la règle est de toujours mettre le temps avant l'espace.
Supposons que nous voulons spécifier qu'un homme a frappé un chien il y a juste une minute. Les mots « zi », « za » et « zu » précisent une courte, non spécifiée (sûrement moyenne) et longue distance dans le temps. Notez l'ordre des voyelles, « i », « a », « u ». Cet ordre apparaît encore et toujours en lojban, et ça peut valoir le coup de le mémoriser. « Court » et « long » sont toujours dépendant du contexte, relatifs et subjectifs. Deux cent ans est très court pour qu'une espèce évolue, mais très long quand on attend le bus.
- zi = sumtcita : survient à une courte distance de {sumti} dans le temps, depuis le point de référence
- za = sumtcita : survient à une distance non spécifiée (moyenne) de {sumti} dans le temps, depuis le point de référence
- zu = sumtcita : survient à une longue distance de {sumti} dans le temps, depuis le point de référence
De la même manière, les distances spatiales sont marquées par « vi », « va » et « vu » pour de courtes, non spécifiées (moyennes) et longues distances dans l'espace.
- vi = sumtcita : survient à une courte distance de {sumti} dans l'espace, depuis le point de référence
- va = sumtcita : survient à une distance non spécifiée (moyenne) de {sumti} dans l'espace, depuis le point de référence
- vu = sumtcita : survient à une longue distance de {sumti} dans l'espace, depuis le point de référence
- gunka = x1 travaille à x2 avec comme objectif x3
Traduisez : « ba {ku} za ku mi vu {ku} gunka {vau} »
Réponse : « Quelque part dans le futur, je vais travailler dans un endroit lointain. »
Note : Les gens utilisent rarement « zi », « za », et « zu », sans un « pu » ou « ba », devant. C'est parce que la plupart des gens ont toujours besoin de spécifier le passé ou futur dans leur langue maternelle. Quand vous y pensez de manière lojbane, la plupart du temps, la direction dans le temps est évidente, et « pu » ou « ba » sont superflus !
L'ordre dans lequel un sumtcita de direction et un sumtcita de distance sont dit fait une différence. Souvenez vous que la signification de plusieurs mots de temps mis ensemble est donnée par un voyage imaginaire, en lisant de gauche à droite. Ainsi, « pu zu » est « Il y a longtemps », alors que « zu pu » est « Dans le passé d'un point dans le temps qui est longtemps avant ou après maintenant ». Dans le premier exemple, « pu » montre que l'on commence dans le passé, et « zu » que c'est à une longue distance dans le passé. Dans le second exemple, « zu » montre que l'on commence quelque part loin de maintenant dans temps, et « pu » que nous nous déplaçons en arrière par rapport à ce point. Ainsi, « pu zu » est toujours dans le passé. « zu pu » peut être dans le futur. Le fait que les temps se combinent de cette manière est une des différences entre les sumtcita de temps et les autres sumtcita. Le sens des autres sumtcita n'est pas modifié par la présence de sumtcita supplémentaires dans un bridi.
Comme impliqué brièvement plus tôt, toutes ces constructions traitent a priori les bridi comme s'ils étaient des points dans le temps et l'espace. En réalité, la plupart des évènements arrivent sur une plage de temps et d'espace. Dans les quelques paragraphes suivants, nous allons apprendre comment spécifier les intervalles de temps et d'espace.
- ze'i = sumtcita : dure le temps (court) de {sumti}
- ze'a = sumtcita : dure le temps (non spécifié, moyen) de {sumti}
- ze'u = sumtcita : dure le temps (long) de {sumti}
- ve'i = sumtcita : s'étend sur le court espace de {sumti}
- ve'a = sumtcita : s'étend sur l'espace non spécifié (moyen) de {sumti}
- ve'u = sumtcita : s'étend sur le long espace de {sumti}
Six mots à la fois, je sais, mais se souvenir de l'ordre des voyelles et la similarité de la lettre initiale « z » pour les temps temporels et « v » pour les temps spatiaux peut aider à s'en souvenir.
- .oi = attitudinal : douleur - plaisir
Traduisez : « .oi dai do ve'u {ku} klama lo dotco gugde {ku} ze'u {ku} {vau} »
Réponse : « Aïe, tu as passé longtemps à voyager une longue distance vers l'Allemagne. »
Bien que la plupart des gens ne soit pas familière avec les temps spatiaux, ces nouveaux mots nous offrent d'intéressantes possibilités. On pourrait, par exemple, traduire « C'est un gros chien » par : « ti ve'u {ku} gerku {vau} ». Dire « Cette chose chien sur un long espace » vous donne l'air idiot en français, mais bon parleur en lojban !
« ze'u » et ses semblables peuvent aussi se combiner avec d'autres temps pour former des temps composés. La règle pour « ze'u » et autres est qu'un temps le précédant marque une limite d'un processus (relatif au point de référence), et un temps le suivant marque l'autre limite, relativement à la première.
Ceci devrait se voir avec quelque exemples :
« .o'ocu'i do citka pu {ku} ze'u {ku} ba {ku} zu {ku} {vau} » : « (tolérance) Tu manges commençant dans le passé et pour une longue durée finissant à un point dans le futur de quand tu as commencé. » ou « Hum, tu as mangé longtemps. ». On peut aussi contraster « do ca {ku} ze'i {ku} pu {ku} klama {vau} » avec « do pu {ku} ze'i {ku} ca {ku} klama {vau} ». Le premier évènement de voyager a une limite dans le présent, et s'étend un peu dans le passé, tandis que le second évènement a une limite dans le passé et s'étend seulement dans le présent (c'est à dire, légèrement dans le passé ou futur) de cette limite.
- jmive = x1 est vivant selon le standard x2
Que veut dire « .ui mi pu {ku} zi {ku} ze'u {ku} jmive {vau} » ?
Réponse : « (joie) Je vis depuis un peu dans le passé et jusqu'à long dans le futur ou passé (évidemment le futur, dans ce cas) de cet évènement » ou « Je suis jeune, et ai toute la vie devant moi :-) »
Juste pour souligner la similarité avec les temps spatiaux, voyons un autre exemple, cette fois ci avec des temps spatiaux :
- .u'e = attitudinal : merveille - lieu commun
Que veut dire « .u'e za'a {ku} bu'u {ku} ve'u {ku} ca'u {ku} zdani {vau} » ?
Réponse : « (merveille) (observe) S'étendant sur un long espace d'ici à là bas devant moi est une maison » ou « Ouah ! Cette maison qui s'étend devant est immense ! »
Avant de continuer avec ce système de temps lourd en syntaxe, je recommande au moins dix minutes à faire quelque chose qui n'occupe pas votre esprit afin de laisser l'information s'imprimer. Chantez une chanson ou mangez un cookie très lentement – n'importe quoi, tant que vous laissez votre esprit se reposer.
Leçons de lojban – leçon onze (ZAhO)
Bien que nous n'allons pas traverser tout les temps lojban pour le moment, il y a une autre sorte de temps qui, je pense, devrait être enseignée. Ils sont nommés les « contours d'évènement », et représentent une manière très différente de voir les temps par rapport à ce que l'on a vu jusqu'ici. Allons-y :
En utilisant les temps que l'on a apprit jusqu'ici, on peut imaginer une ligne de temps indéfinie, et placer des évènements sur cette ligne relatifs au « maintenant ». Avec les contours d'évènements, cependant, on voit chaque évènement comme un processus, qui a certaines étapes : un moment avant l'évènement, un moment quand il commence, un moment quand il est en cours, un moment quand il se termine, et un moment après qu'il se soit terminé. Les contours d'évènements nous disent à quel moment dans le processus de l'évènement nous étions pendant le temps spécifié par les autres temps. Nous avons besoin de quelque temps pour commencer :
- pu'o = – sumtcita: contour d'évènement : le bridi n'est pas encore arrivé pendant {sumti}
- ca'o = – sumtcita: contour d'évènement : le bridi est en cours pendant {sumti}
- ba'o = – sumtcita: contour d'évènement : le bridi s'est terminé pendant {sumti}
Ceci demande quelque exemples. Que signifie « .ui mi pu'o {ku} se zdani {vau} » ?
Réponse : « ☺ Je vais commencer à avoir une maison »
Mais, demandez vous, pourquoi ne pas juste dire « .ui mi ba {ku} se zdani {vau} » et s'économiser une syllabe ? Parce que, souvenez-vous, dire que vous allez avoir une maison dans le futur ne dit rien à propos de si vous en possédez déjà une. En utilisant « pu'o », par contre, vous dîtes que vous êtes maintenant dans le passé du moment où vous avez une maison, ce qui veux dire que vous n'en avez pas encore.
Notez au passage que « mi ba {ku} se zdani {vau} » est similaire à « mi pu'o {ku} se zdani {vau} », de même pour « ba'o » and « pu ». Pourquoi semble-t'ils à l'envers ? Parce que les contours d'évènements voient le présent du point de vue du processus, alors que les autres temps voient les évènements dans notre présent.
Souvent, les contours d'évènements sont plus précis que les autres types de temps. Encore plus de clareté est obtenue en combinant plusieurs temps : « .a'o mi ba{ku} zi {ku} ba'o {ku} gunka {vau} » – « J'espère que j'ai bientôt finit de travailler. ».
En lojban, on travaille aussi avec le « début naturel » et la « fin naturelle » d'un évènement. Le terme « naturel » est hautement subjectif ici, et la fin naturelle se réfère au point où processus devrait se terminer. Vous pouvez dire, à propos d'un train en retard, par exemple, que sont processus d'arriver à vous est maintenant en train de s'étendre au delà de sa fin naturelle. Un plat pas assez cuit, mais servit, de même, est mangé avant le début naturel du processus « manger ». Les contours d'évènements utilisés dans ces exemples sont les suivants :
- za'o = – sumtcita: contour d'évènement :le bridi est en cours au delà de sa fin naturelle pendant {sumti}
- xa'o = – sumtcita: contour d'évènement :le bridi est en cours, trop tôt, pendant {sumti}
- cidja = x1 est de la nourriture, que x2 peut manger
Traduisez : « .oi do citka za'o lo nu do ba'o {ku} u'e citka zo'e noi cidja do {vau} {ku'o} {vau} {kei} {ku} »
Réponse : « Ouch, tu continues de manger quand tu as finit, incroyablement, de manger quelque chose de comestible ! »
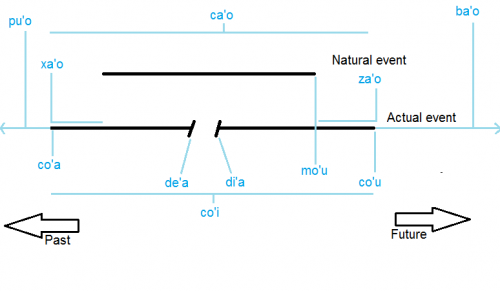
Image ci-dessus : les temps de ZAhO (contours d'événements). Tous les temps au dessus de la ligne de l'événement indique des étapes couvrant une certaine durée. Tous les temps en-dessous de la ligne de l'événement indique des étapes instantanées.
Tous ces temps décrivaient des étapes d'un processus ayant une certaine durée (comme montré par le graphe ci-dessus; ces temps au-dessus de la ligne de l'événement). Mais beaucoup des contours d'événements décrivent des étapes instantanées dans le processus, comme son commencement. Comme c'est le cas pour ca et bu'u, ils s'étendent en fait légèrement dans le passé et le futur de cet instant, et n'ont pas besoin d'être précis.
Les deux contours d'événement instantanés les plus importants sont :
- co'a = sumtcita : contour d'événement : Le bridi est à son commencement durant {sumti}
- co'u = sumtcita : contour d'événement : le bridi arrive à sa fin durant {sumti}
En outre, à un certain point, l'événement est naturellement complet, mais n'est pas forcément terminé :
- mo'u = sumtcita : contour d'événement : le bridi arrive à sa fin naturelle durant {sumti}
Bien que la plupart du temps, les processus s'arrête effectivement à leur fin naturelle, c'est ce qui la rend naturelle. Habituellement les trains ne sont pas en retard, habituellement les gens se contente de manger de la nourriture comestible.
Comme un processus peut-être interrompu et relancé, ces points aussi ont mérité leurs propres contours d'événements :
- de'a = sumtcita : contour d'événement : le bridi est en pause durant {sumti}
- di'a = sumtcita : contour d'événement : le bridi recommence durant {sumti}
En fait comme jundi signifie « x1 est attentif à x2 », de'a jundi et di'a jundi sont des façons, communes en lojban, de dire « je reviens » ( « dans le sens je m'en vais et je vais bientôt revenir » )et « je suis de retour ». Bien sûr on peut se contenter de dire les contours d'événement seuls et espérer être compris.
Finalement, on peut considérer un événement entier, du début à la fin, comme un seul instant en utilisant co'i :
- penmi = x1 rencontre x2 à l'endroit x3
mi pu {ku} zi {ku} penmi lo dotco prenu {ku} {vau} - « Il y a longtemps, j'été à l'instant où je rencontrais une personne allemande ».
Leçons de lojban – leçon douze (ordres et question)
Pfiou, ces deux longues leçons avec du lojban chargé en syntaxe ont donné matière à réfléchir au cerveau. En particulier parce que c'est très différent du français. Tournons-nous donc vers quelque chose d'un peu plus léger : les ordres et les questions.
Qu'est-ce que… assis et concentré !
Puisqu'en français les ordres sont exprimés en laissant le sujet hors de la phrase, pourquoi avez-vous supposez que c'était à vous que je m'adressais, et que je ne me commandais pas moi-même, ni n'exprimais l'obligation de quelqu'un d'autre ? Parce que la langue française comprend que les ordres, de par leur nature-même, sont toujours dirigés vers le récepteur - le « tu », et que le sujet n'est donc pas nécessaire.
En lojban, l'ellipse du sujet équivaut à zo'e, cette possibilité nous est donc malheureusement inaccessible. À la place nous utilisons le mot ko, qui est la forme impérative de do. Grammaticalement et du point de vue du bridi, c'est équivalent à do, mais ça rajoute une couche de sémantique, puisque ça transforme toute proposition contenant ko en un ordre. « Fais en sorte que cette phrase soit vraie pour toi=ko ! » Pour la même raison pour laquelle on a pas besoin du sujet dans les phrases anglaises, on a pas besoin de mots de commande dérivé d'un autre sumti que do.
Comment pouvez-vous ordonner à quelqu'un de partir loin et pour longtemps (en utilisant klama comme unique selbri ?)
Réponse : ko ve'u ze'u klama
(.i za'a dai a'o mi ca co'u ciska lo famyma'o .i ko jimpe vau .ui) - regarder ciska et essayez de comprendre.
Les questions en lojban son très facile à apprendre. Il y en a deux sortes : Remplissez le blanc, et les questions « vrai ou faux ». Commençons avec les questions de type « vrai ou faux » - c'est assez accessible, vu que cela ne fait intervenir qu'un seul mot, xu.
xu fonctionne comme un attitudinal en ceci qu'il peut se mettre partout et qu'il s'applique au mot (ou à la construction) précédent. Il transforme alors la phrase en une question, demandant si c'est vrai ou non. Pour répondre par l'affirmative, vous répetez simplement le bridi :
xu ve'u zdani do .i ve'u zdani mi, ou bien vous répetez uniquement le selbri, qui est le bridi privé de tous ses sumti et tous ses temps: zdani.
Il y a une façon encore plus facile de confirmer en utilisant un brika'i, mais ce sera pour une autre fois. Pour répondre « non » ou « faux », vous répondez simplement avec la négation du bridi. Ceci aussi est laissé pour plus tard, mais nous reviendrons aux façons de répondre aux questions d'ici là.
L'autre genre est « remplir le blanc ». Ici vous demandez que le mot-question soit remplacé par une construction qui rende le bridi correct. Il existe plusieurs de ces mots, selon ce sur quoi vous questionnez :
- ma = demande le sumti
- mo = demande le selbri
- xo = demande le nombre
- cu'e = demande le temps
Et bien d'autres. Pour questionner sur un sumti, vous placez donc simplement votre mot de questionnement là où vous voulez votre réponse : do dunda ma mi- demande de remplir le x2 avec un sumti correct. « Tu me donnes quoi ? ». La combinaison sumtcita + ma est en effet très utile :
mu'i- sumtcita : motivé par l'abstraction de {sumti}
.oi do darxi mi mu'i ma- « Aïe, pourquoi me frappes-tu ?! »
Essayons-en une autre. Cette fois, vous traduisez :
.ui dai do ca ze'u pu mo
Réponse : « Tu es heureux, qu'as-tu fais tout ce temps jusqu'à maintenant ? ». Techniquement, cela peut aussi vouloir dire « qu'étais-tu ? », mais répondre par .ua nai li'a remna (Ben, humain, évidemment) c'est juste une façon d'être volontairement affreusement pénible.
Comme le ton de la voix et la structure des phrases n'indique pas qu'une phrase est ou n'est pas une question, il vaut mieux ne pas rater le mot de questionnement. C'est pourquoi, puisque les gens ont tendance à se concentrer plutôt sur les mots au début et à la fin des phrases, ça vaut généralement le coût de réordonner la phrase de façon à ce que les mots de questionnement se retrouvent à ces places là. Si ce n'est pas faisable, pau est un attitudinal indiquant que la phrase est une question. À l'inverse, pau nai indique explicitement qu'une question est rhétorique.
Tant qu'on est sur le sujet des questions, il est pertinent de mentionner le mot kau, qui est un marqueur signalant « question indirect ». Mais alors, c'est quoi une question indirecte ? Bon, regardez cette phrase : mi djuno lo du'u ma kau zdani do - « Je sais ce qu'est ta maison ».
- djuno = x1 sait que les faits x2 sont vrais à propos de x3 selon l'épistémologie x4
On peut le voir comme la réponse à la question ma zdani do. Plus rarement, on peut étiquetter un mot qui n'est pas un mot de questionnement avec kau, auquel cas on peut toujours l'imaginer comme la réponse à une question : mi jimpe lo du'u dunda ti kau do - « Je sais ce qui t'a été donné, c'est ceci ».
Leçons de lojban – Leçon treize (morphologie et classes de mots)
Retour à une matière plus consistante (et intéressante)
Si vous ne l'avez pas déjà fait, je vous suggère fortement de trouver l'enregistrement en lojban intitulé « Story Time with Uncle Robin », ou d'écouter quelqu'un parler lojban avec Mumble, et d'exercer votre prononciation. Avoir une conversation en lojban dans votre tête n'est bon que si elle ne se fait pas avec de mauvais sons, et apprendre la prononciation depuis l'écrit est difficile. Par conséquent, cette leçon ne portera pas sur les sons du lojban, aussi importants soient ils, mais sur une courte introduction à la morphologie du lobjan.
Qu'est ce que la morphologie ? Le mot est issu de la signification grecque "l'étude des formes", et dans ce contexte, nous parlons de comment nous formons des mots à partir de lettres et de sons, au contraire de la syntaxe - comment nous formons des phrases avec des mots. Le lobjan utilise différentes classes morphologiques de mots, qui sont toutes définies par leur morphologie. Pour que tout soit simple et systématique quand même, les mots ayant certaines fonctions ont tendance à être groupés par classes morphologiques, mais il peut y avoir des exceptions.
| Classe | Signification | Défini par | Fonction typique |
|---|---|---|---|
| Mots : | |||
| brivla | mot bridi | Il y a un groupement de consonnes parmi les 5 premières lettres (sans compter les « ' ». Termine par une voyelle. | Par défaut, agit comme un selbri. A toujours une structure de position. |
| gismu | Mot racine | 5 lettres avec la forme CVCCV ou CCVCV | Une à cinq position pour des sumti. Couvre les concepts de base. |
| lujvo | Mot composé. Dérivé de « lujvla » signifiant « mot complexe ». | Au moins 6 lettres. Créé par l'enchainement de rafsi, avec des lettres de liaison si besoin. | Couvre des concepts plus complexes que les gismu. |
| fu'ivla | Mot emprunté | Comme brivla, mais sans respecter les critéres définis pour les gismu ou les lujvo, ex : angeli | Couvre des concepts uniques comme des noms de lieus ou d'organismes. |
| cmevla | Nom propre | Commence et fini par une pause (point). Le dernier son/lettre est une consonne. | Agit toujours comme un nom ou comme le contenu d'une citation. |
| cmavo | Mot de grammaire. De « cmavla » signifiant « petit mot » | Zéro ou une consonne, toujours au début. Termine par une voyelle. | Fonctions grammaticales. Variées. |
| Morceaux de mots : | |||
| Rafsi | Affixe | CCV, CVC' CV'V, -CVCCV, CVCCy- ou CCVCy- | Pas de vrai mots, mais ils peuvent être combinés pour former des lujvo. |
Les cmevla sont très facile à identifier, car ils commencent et finissent par une pause, signalée à l'écrit par un point, et la dernière lettre est une consonne. Les cmevla ont deux fonctions : ils peuvent agir comme nom propre, s'ils sont préfixés par l'article la (expliqué dans la prochaine leçon), ou ils peuvent agir comme contenu d'une citation. Comme déjà vu, on peut marquer l'accentuation dans un nom en écrivant en capitale les lettres qui sont accentuées. Des exemples de cmevla : .io'AN. (Johan), .mat. (Matt) et .luitciMIN. (Lui-Chi Min). Les noms qui ne finissent pas par une consonne doivent en ajouter une : .evyn. (Eve), ou (probablement mieux dans ce cas) en retirer une : .ev.
Les brivla sont appelés " mots bridi " parce qu'ils sont par défaut des selbri, en conséquence presque tous les mots lojban avec une structure de position sont des brivla Ça leur a aussi valu le surnom français de « mots de contenu ». C'est à peu près impossible de dire quoi que ce soit d'utile sans brivla, et presque tous les mots pour des concepts hors de la grammaire lojban (et même la plupart des mots pour des choses dans le langage) sont des brivla. Comme la table le montre, il y a trois catégories de brivla :
Les gismu sont les mots-racines du langage. Il n'en existe qu'environ 1450, et très peu de nouveaux sont ajoutés. Ils couvrent les concepts les plus basiques tels que « cercle », « ami », « arbre » et « rêve ». zdani, pelxu et dunda en sont quelques exemples.
Les lujvo se construisent en combinant des rafsi (voir plus bas rafsi), qui représentent des gismu. En combinant des rafsi, on restreint la signification du mot. Les lujvo sont produits par un algorithme sophistiqué, faire des lujvo valides à la volée est donc preque impossible, à quelques exceptions près comme selpa'i, de se prami, qui ne peut avoir qu'une définition. Au lieu de ça les lujvo sont fait une fois pour toutes, leurs structures de position définie, et ensuite cette définition est officialisée par le dictionnaire. Parmi les lujvo il y a des brivla (mots-bridi) comme cinjikca (sexuel-socialisation = flirt) ou cakcinki (coquille-insect = scarabée).
Les fu'ivla sont faits en fabriquant des mots qui correspondent à la définition des brivla, mais pas à celles des lujvo ou des gismu. Ils ont tendance à couvrir des concepts difficiles à transcrire par des lujvo, comme les noms d'espèces, les nations ou des concepts très spécifiques à une culture. On trouve, par exemple, gugdrgogurio (la Corée) , cidjrpitsa (pizza) ou angeli (ange).
Les cmavo sont de petits mots avec zéro ou une consonne. Ils ont tendance à ne rien représenter dans le monde extérieur, et à n'avoir qu'une fonction grammaticale. Il y a des exceptions, et savoir à quel point les attitudinaux existent pour leur fonction grammaticale est sujet à débats. Les mots de la classe GOhA qui agissent comme des brivla sont un autre exemple bizarre. Il est correct d'enchaîner plusieurs cmavo à la suite pour former un mot, mais nous ne le ferons pas dans ces leçons. Néanmoins, en groupant certains cmavo en unités fonctionelles, c'est parfois plus facile à lire. Ainsi, .uipuzuvukumi citka est correct, et s'analyse et se comprend comme .ui pu zu vu ku mi citka. Comme avec les autres mots lojban, on devrait (mais on a pas toujours besoin) placer un point devant chaque mot commençant par une voyelle.
Les cmavo de la forme xVV, CV'VV et V'VV sont expérimentaux, et sont hors de la grammaire formelle, mais ils ont été ajouté par des lojbanistes pour répondre à un certain usage.
Les rafsi ne sont pas des mots lojban et ne peuvent jamais apparaître seuls. Néanmoins, on peut combiner plusieurs rafsi (strictement plus d'un) pour former un lujvo. Ceux-là doivent encore obéir à la définition des brivla, par exemple lojban est invalide parce qu'il finit par une consonne (ce qui en fait un cmevla), et ci'ekei est invalide parce qu'il ne contient pas de groupement de consonne et se lit donc comme deux cmavo écrits comme un seul mot. Souvent, une chaîne de 3-4 lettres est à la fois un cmavo et un rafsi, comme zu'e qui est à la fois le mot de la classe BAI et le rafsi pour zukte. Remarquez qu'il n'y a pas de situation dans laquelle les cmavo et les rafsi sont tous deux grammaticalement corrects, et ils ne sont donc pas considérés comme homophones. Tous les gismu peuvent servir de rafsi s'ils sont préfixés par un autre rafsi. Les quatre premières lettres d'un gismu suffixées avec un " y " peuvent aussi agir comme rafsi, si elles sont suffixées par un autre rafsi. La voyelle " y " ne peut apparaître que dans des lujvo ou des cmevla. Les combinaisons de lettres valides pour un rafsi sont : CVV, CV'V, CCV, CVCCy-, CCVCy-, -CVCCV et -CCVCV.
En utilisant ce que vous savez, vous devriez pouvoir réussir le test que je vous présente :
Classez chacun des mots suivants en tant que cmevla (C), gismu (g), lujvo (l), fu'ivla (f) ou cmavo (c) :
| A ) jai | G ) mumbl |
|---|---|
| B ) .irci | H ) .i'i |
| C ) bostu | I ) cu |
| D ) xelman | J ) plajva |
| E ) po'e | K ) danseke |
| F ) djisku | L ) .ertsa |
Réponse : a-c, b-f, c-g, d-C, e-c, f-l, g-C, h-c, i-c, j-l, k-f, l-f. J'ai laisser tomber les points avant et après les noms pour que ce ne soit pas trop facile. Remarque : certains de ces mots, comme bostu n'existe pas dans le dictionnaire, mais ça n'a pas d'importance. La morphologie en fait quand même un gismu, donc c'est juste un gismu sans définition. De même pour .ertsa.
Leçons de lojban – Leçon quatorze (les sumti lojbans 1 : LE et LA)
Si vous avez lu et compris le contenu de toutes les leçons jusqu'à présent, vous avez accumulé une assez grande connaissance du Lojban pour que l'ordre dans lequel vous apprenez le reste n'ait pas d'importance. En conséquence, l'ordre des prochaines leçons sera un mélange de tri par difficulté croissante et par importance dans la conversation lojbane de tous les jours.
L'une des plus grosses contraintes pour votre expression maintenant est votre connaissance limitée sur la façon de construire des sumti. Pour l'instant, vous ne connaissez que ti et lo SELBRI , ce qui ne vous ménera pas loin étant donnée l'importance des sumti en lojban. Cette leçon, comme les deux suivantes, portera sur les sumti lojbans. Pour l'instant, nous nous concentrerons sur les sumti descriptifs, ceux construits avec des articles comme lo.
Les articles s'appellent gadri en lojban, et tous ceux discutés dans cette leçon se terminent avec ku, à l'exception des combinaisons la CMEVLA, lai CMEVLA et la'i CMEVLA. Nous commencerons par décrire trois types simples de sumti descriptifs, puis nous découvrirons aussitôt qu'ils ne sont pas si simples en fait :
- lo = gadri : Factuel générique « convertit un selbri en sumti ». Le résultat est flou en ce qui concerne l'individualité/groupement.
- le = gadri : Descriptif générique « convertit un selbri en sumti ». Le résultat est flou en ce qui concerne l'individualité/groupement.
- la = gadri : Artcile nommant : Conventionnel, « convertit un selbri ou un cmevla en sumti ». Traitez le résultat comme un/des individu(s).
Vous êtes déjà familier avec lo et ce qu'il fait. Mais qu'est-ce que ça signifie, « factuel » et « flou en ce qui concerne l'individualité/groupement » ? Le second à propos des individus et des groupements, j'y reviendrais plus tard. Pour l'instant, « factuel » dans ce contexte signifie que pour pouvoir être étiquetée comme lo klama une chose doit effectivement klama. Donc les gadri factuels énonce une proposition qui peut-être vrai ou fausse - que l(es)'objet(s) en question sont effectivement le x1 du selbri suivant lo.
Cela peut-être contrasté avec le, qui est descriptif, et donc pas factuel. Dire le gerku signifie que vous avez un ou plusieurs objets spécifiques en tête, et que vous utilisez le selbri gerku pour les décrire, de sorte que le récepteur puisse identifier ces objets spécifiques. Cela signifie que le a deux différences majeures avec lo : d'abord, il ne peut pas faire référence à des objets en général, mais toujours à des objets spécifiques. Ensuite, alors que lo gerku est définitivement un ou plusieurs chiens, le gerku peut-être n'importe quoi tant que le locuteur pense que la description aide à identifier les bons objets. Peut-être que le locuteur fait référence à une hyène, mais n'étant pas familier avec elles, il pense que « chien » est une approximation assez bonne pour être comprise. Cet aspect non factuel est peut-être trop mis en avant dans beaucoup de texte. La meilleure façon de décrire un chien est souvent de le décrire comme étant un chien, et à moins qu'il y ait de bonnes raison de ne pas le faire, le gerku sera généralement supposé faire référence à quelque chose qui est aussi lo gerku.
Dans une traduction, lo gerku devient généralement « un chien » ou « des chiens », alors que le gerku devient « le chien » ou « les chiens ». Une traduction encore meilleure pour le gerku serait « le(s) « chien(s) » ».
la est le dernier des trois gadri basiques, le gadri qui nomme, que j'ai, de façon peu conventionnelle, appelé « conventionnel ». Ce que je veux dire par là c'est qu'il n'est ni descriptif, ni factuel, puisqu'il fait référence à un nom propre. Si en anglais j'appelle quelqu'un nommé Innocent par son nom, je ne le décrit pas comme innocent ni n'annonce qu'il l'est. J'annonce simplement que par convention, ce selbri ou ce cmevla fait référence à cet objet. Remarquez que la et les gadri qui en dérivent peuvent convertir les cmevla en sumti au contraire des autres gadri. Attention : d'autres textes ne mentionnent pas le fait que les noms peuvent être formé à partir de selbri ordinaire en utilisant le gadri la. Mais ces hérétiques doivent brûler, les noms selbri sont bien comme ils sont, et bien de fiers lojbanistes en portent.
la, comme lai et la'i sont un peu excentriques, puisque ils marquent toujours le début d'un nom. À la différence des autres gadri, tout ce qui peut-être grammaticalement placé après la et ses frères est considéré comme faisant parti du nom. Par exemple, le mi gerku c'est « mon chien », mais la mi gerku c'est quelqu'un nommé « Mon Chien ».
À ces trois gadri de base trois autres peuvent être ajoutés, qui correspondent aux précédents :
- loi = gadri : Factuel « convertit un selbri en sumti ». Traitez le résultat comme une/des masse(s).
- lei = gadri : Descriptif « convertit un selbri en sumti ». Traitez le résultat comme une/des masse(s).
- lai = gadri : Article nommant : Conventionnel, « convertit un selbri ou un cmevla en sumti ». Traitez le résultat comme une/des masse(s).
Ce sont les mêmes dans tous les aspects sauf un : ils traitent explicitement les sumti comme des masses. Et c'est là que la distinction entre individus et masses devient importante. S'il n'y a qu'un objet en jeu, un individu ou une masse constituée d'un sel objet sont équivalents. La différence entre ces deux concepts réside dans l'application des selbri, soit à un groupe d'individus, soit à une masse. Un groupe d'individu peut-être décrit comme vérifiant un selbri particulier, si et seulement si tous les membres du groupe vérifient le selbri individuellement. C'est correct de décrire une meute de lo gerku, considérés individuellement, comme étant noire, si pour chacun des chiens, il est vrai qu'il est noir. La masse d'un autre côté, ne vérifie que les selbri que ses composants vérifient en tant qu'ensemble, en tant qu'équipe pour ainsi dire. Quoi qu'il en soit, tous les membres d'une masse loi gerku doivent être des chiens pour que loi soit applicable. La notion de « masses » est sophistiquée, et nécessitent quelques exemples pour visualiser les propriétés qu'elle peut avoir :
- sruri = x1 borde/encercle/entoure x2 dans la ligne/le plan/les directions x3
lei prenu cu sruri lo zdani - « Les personnes entourent la maison. » est plausible, même si, les blagues « Ta mère mises de côté, il est complètement inenvisageable que ce soit vrai pour n'importe quel membre unique. Une analogie française pourrait être : « Les humains ont vaincu la variole au vingtième siècle ». Certes aucun humain n'a fait ça, mais la masse des humains l'a fait, et cela rend la phrase vraie en fançais, ainsi qu'en lojban si « les humains » sont une masse. Comme la masse lojbane, la masse française « les humains » ne peut faire référence qu'à des individus, chacun étant humain. Un autre exemple :
- mivysle = x1 est une cellule biologique de l'organisme x2
- remna = x1 est un(e) humain(e)
loi mivysle cu remna - « Une/des masse(s) de cellules sont des humains ». Encore une fois, aucune des cellules n'est un humain. En effet les cellules ont très peu de traits humains, mais les cellules considérées comme un tout font un être humain.
Une masse avec lei, comme lei gerku, fait référence à une masse formée par un groupe d'individus spécifiques, le locuteur désignant chacun d'entre eux comme le gerku.
Les noms de masses comme décrit par lai ne sont appropriés que si le groupe en tant qu'ensemble est nommé ainsi, et non si seulement des membres quelconques le sont. Il peut cependant être utilisé si le bridi n'est vrai que pour une fraction de ce groupe.
Il est important de se rappeler que lo et le peuvent être utilisés pour décrire soit des individus soit des groupes. Imaginons qu'un groupe de chien, considéré en tant que masse, ait besoin d'une description. Je peux le décrire soit comme loi soit comme lo gerku. Si j'utilise lo, cela me permet d'affirmer correctement quelque chose qui semble être une contradiction, mais n'en est pas vraiment une : lo gerku na gerku - « quelques chiens ne sont pas des chiens ». Puisque ils sont considérés comme une masse de chien, les chiens considérés dans leur ensemble ne sont pas un chien, mais plutôt une meute de chien.
Vous avez pu remarquer qu'il n'y a pas de mots qui convertissent sans ambiguïté un selbri en individu(s). Afin d'être explicite sur l'individualité, on a besoin de lo le ou la avec un quantificateur externe. Le sujet des quantificateurs sera étudié plus tard, dans la leçon vingt-deux. Pour quelle raison lo et le sont vague et non explicitement individualisant ? C'est parce que leur imprécision leur permet d'être utilisés dans tous les contextes, sans que le locuteur doive se préoccuper de savoir si ce dont il parle se comporte comme une masse ou comme un groupe d'individus.
Troisièmes dans cette liste, il y a les trois gadri pour former des ensembles :
- lo'i = gadri : factuel « convertit un selbri en sumti ». Traite le résultat comme un ensemble.
- le'i = gadri : Descriptif « convertit un selbri en sumti ». Traite le résultat comme un ensemble.
- la'i = gadri : Article nommant : Conventionnel, « convertit un selbri ou un cmevla en sumti ». Traite le résultat comme un ensemble.
Contrairement aux groupes d'individus, ou, parfois aux masses, les ensembles ne prennent aucunes des propriétés des objets à partir desquels ils sont formés. Un ensemble est une construction purement mathématique, ou logique, il a des propriétés comme le cardinal, l'appartenance et l'inclusion ensembliste. Encore une fois, notez la différence entre un ensemble de choses et les choses dont l'ensemble est formé :
- tirxu = x1 est un tigre/léopard/jaguar de l'espèce/race x2 avec les marques x3 sur la fourrure
lo'i tirxu cu cmalu ne dit rien sur le fait que les gros chats sont petits ( ce qui, par ailleurs, est évidemment faux ), mais dit plutôt que l'ensemble des gros chats est petits, c'est-à-dire qu'il y en a peu.
Finalement, il y a les (seulement deux) gadri de généralisation :
lo'e - gadri : factuel « convertit un selbri en sumti ». Le sumti fait référence à l'archétype de lo {selbri}.
- le'e = gadri : Descriptif « convertit un selbri en sumti ». Le sumti fait référence à l'archétype décrit ou perçu de le {selbri}.
Il n'y a pas d'équivalent de ces deux là, qui soit dérivé de la.
Bon, qu'est-ce que ça veut vraiment dire l'archétype ? Pour lo'e tirxu, c'est un gros chat imaginaire idéalisé, qui a toutes les propriétés qui représentent le mieux les gros chats. Ce serait faux de dire que cela inclus avoir une fourrure rayée, car un sous-groupe important des membres de l'ensemble des gros chats n'a pas de fourrure rayée, comme les léopards ou les jaguars. De la même façon, l'humain typique ne vit pas en Asie, même si beaucoup d'humains y vivent. Néanmoins, si suffisamment d'humains ont une propriété, par exemple être capable de parler, nous pouvons dire :
- kakne = x1 est capable de faire/être x2 dans les circonstances x3
lo'e remna cu kakne lo nu tavla - « l'être humain typique peut parler ».
le'e maintenant est l'objet idéal comme perçu ou décrit par le locuteur. Ce n'est peut-être pas factuellement exact, et c'est souvent traduit par le « stéréotype », même si l'expression anglaise a quelques connotations négatives déplaisantes, ce que le lojban n'a pas. En fait, chacun a une image archétypique et stéréotypique de chaque catégorie. En d'autres termes, lo'e remna est l'archétype qui représente le mieux tous lo remna, alors l'archétype le'e remna représente le mieux tous le remna.
Les onze gadri sont représentés dans le diagramme ci-dessous.
| Générique | Masses | Ensembles | Généralisation | |
|---|---|---|---|---|
| Factuel | loi | lo'i | lo'e | |
| Descriptif | lei | le'i | le'e | |
| Nom | la | lai | la'i | n'existe pas |
Remarque : anciennement, il y avait un mot, xo'e pour le gadri générique. Néanmoins, les règles et les définitions des gadri ont été changés fin 2004, et l'ensemble de règles actuel sur ce sujet, surnommé « xorlo » a remplacé les anciennes règles. Maintenant, lo est générique et xo'e est utilisé comme un chiffre non spécifié ( leçon dix-neuf ).
Leçons de lojban – Leçon quinze (les sumti lojbans 2: KOhA3, KOhA5 et KOhA6)
Regardez ce qu'il se passe si j'essaye de traduire la phrase : « Les gens stéréotypés qui peuvent parler lojban parlent entre eux des langues qu'ils peuvent parler.»
- bangu = x1 est un langage utilisé par x2 pour exprimer x3 (abstraction)
le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. cu tavla le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. lo bangu poi lo prenu ke'a tavla fo la .lojban. cu se bangu ke'a
Ce que nous voyons c'est que la version lojban est bien plus longue que l'anglaise. C'est principalement parce que le premier sumti, ridiculement long, est encore répété deux fois dans le texte lojban, alors que l'anglais peut y renvoyer par « eux » et « ils » - beaucoup plus efficacement. Ne serait-ce pas astucieux si le Lojban avait, d'une manière ou d'une autre, des mécanismes pour faire la même chose?
Il se trouve qu'il en possède, quelle surprise ! Le lojban a une série de mots appelés "sumka'i", c'est à dire « représentant des sumti ». En français, on s'y réfère en tant que « pro-sumti », parce qu'ils agissent essentiellement comme les pronoms français, mais avec des sumti au lieu des noms. En fait, vous connaissez déjà ti, do et mi, mais il y en a bien d'autres, apprenons-les donc. D'abord, nous voulons en faire un système. Nous pouvons commencer par ceux les plus proches du français, et que vous avez déjà appris.
- ti = sumka'i : 'ça' tout près : représente un sumti présent physiquement près de l'orateur.
- ta = sumka'i : 'ça' proche : représente un sumti à quelque distance de l'orateur OU près de l'interlocuteur.
- tu = sumka'i : 'ça' lointain : représente un sumti se trouvant physiquement loin de l'orateur et de l'interlocuteur.
Vous pouvez reconnaître la séquence « i, a, u » qui revient encore et encore. Certaines choses doivent néanmoins être éclaircies. Premièrement, ces sumti peuvent représenter n'importe quoi dont on peut dire qu'il occupe un espace physique. Des objets, certainement. Des idées, certainement pas. Les événements sont acceptés, sous réserve qu'ils prennent place dans un endroit délimité - la révolution de Jasmin ne peut pas être pointé du doigt, mais certaines bagarres de bar ou baisers peuvent l'être. Deuxièmement, remarquez que la distance est relative à différentes choses pour les différents mots : tu ne s'applique que si c'est loin à la fois du locuteur et du récepteur. Dans les cas où le locuteur et le récepteur sont très éloignés, et que le récepteur ne peut pas voir le locuteur parler, ta fait référence à quelque chose de proche du récepteur. Troisièmement, c'est relatif et dépendant du contexte. Ces trois mots sont tous problématiques à l'écrit, par exemple parce que la position du locuteur est inconnue du récepteur et vice versa, et elles changent au cours du temps. De plus, l'auteur d'un livre ne peut pointer du doigt un objet et transcrire le geste dans le livre.
Ensuite il y a une séries appelée KOhA3, à laquelle mi et do (et ko, mais je ne vais pas en parler ici) appartiennent :
- mi = sumka'i : Le narrateur
- mi'o = sumka'i : La masse composée du/des locuteur(s) et du/des récepteur(s).
- mi'a = sumka'i : La masse composée du/des locuteur(s) et d'autres.
- ma'a = sumka'i : La masse composée du/des locuteur(s), du/des récepteur(s) et d'autres.
- do = sumka'i : Le(s) récepteur(s).
- do'o = sumka'i : La masse composée du/des récepteur(s) et d'autres.
Ces six sumka'i s'appréhendent plus facilement dans le diagramme de Venn ci-dessous :

Diagramme de Venn de KOhA3 (sans ko). le drata n'est pas un membre de KOhA3, mais signifie « le(s) autre(s) ».
Il est possible que plusieurs personnes soient « les locuteurs », si une déclaration est faite en leurs noms à toutes. En conséquence, alors que « nous » peut se traduire par mi, mi'o, mi'a ou ma'a, ce qu'on veut dire le plus souvent c'est juste mi. Chacun de ces six mots, s'il fait référence à plus d'un individu, représente une masse. Dans la logique des bridi, le bridi mi gleki dit par le locuteur A est exactement équivalent à do gleki dit par le locuteur B au locuteur A, et sont considérés comme le même bridi. Nous y reviendrons plus tard, dans la leçon sur les brika'i (pro-bridi).
Tous ces sumka'i sont très dépendant de leur contenu, et ne peuvent être utilisé, par exemple, pour nous aidé avec la phrase de départ de cette leçon. La série suivante peut, en principe, être utilisée pour faire référence à n'importe quel sumti :
- ri = sumka'i : Dernier sumti mentionné
- ra = sumka'i : Un sumti récent, mais pas le dernier mentionné
- ru = sumka'i : Un sumti mentionné il y a longtemps
Ces sumti vont faire référence à n'importe quel sumti terminé, exception faite de la plupart des autres sumka'i. La raison pour laquelle la plupart des autres sumka'i ne peuvent pas être ciblés par ces sumti est qu'ils sont très facile à simplement répéter en l'état. Les exceptions à la règle, sont ti, ta et tu, parce que vous pouvez vous être mis à pointer autre chose, et donc ne plus pouvoir juste répéter le mot. Ils vont seulement faire référence à des sumti terminés, et donc ne pourront pas, entre autres, être utilisés pour faire référence à une abstraction si le mot est dans cette abstraction : le pendo noi ke'a pendo mi cu djica lo nu ri se zdani - ici ri ne peut pas faire référence à l'abstraction, puisqu'elle n'est pas terminée, ni à mi ou ke'a, puisque ce sont des sumka'i, donc ri fait référence à le pendo.
Ce à quoi ra et ru référent dépend du contexte, mais ils suivent les règles mentionnées plus haut, et ru fait toujours référence à un sumti plus lointain que ra, qui est toujours plus distant que ri.
ri et ses frères sont plutôt bien adaptés pour s'occuper de la phrase originale. Essayé de la dire en utilisant deux exemples de sumka'i !
Réponse : le'e prenu poi ke'a kakne lo nu tavla fo la .lojban. cu tavla ru lo bangu poi ru cu se bangu ke'a. ri n'est pas correct, parce qu'il ferait référence à la .lojban.. ra pourrait être utilisé, mais on pourrait croire par erreur qu'il fait référence à lo nu tavla fo la .lojban., alors que ru est supposé référé au sumti le plus lointain - le plus extérieur.
Finalement, il y a des sumtcita qui représentent les paroles : Appelés variables de paroles. Ils n'ont pas besoin d'être restreints à une phrase (jufra), et peuvent être constitués de plusieurs phrases, si le contexte le permet :
- da'u = Variable de parole : Déclaration passée distante
- de'u = Variable de parole : Déclaration récente
- di'u = Variable de parole : Déclaration précédente
- dei = Variable de parole : Cette déclaration
- di'e = Variable de parole : Prochaine déclaration
- de'e = Variable de parole : Déclaration future proche
- da'e = Variable de parole : Déclaration future éloignée
- do'i = Variable de parole : Variable de parole non spécifiée : « Une déclaration »
Ils représentent les déclarations comme des sumti, et ne font référence qu'aux mots prononcés ou aux lettres, pas au sens qu'il y a derrière.
Il y a d'autres sumka'i lojbans, mais pour l'instant vous avez sûrement besoin d'une pause en ce qui les concerne. La prochaine leçon sera sur les sumti dérivés, les sumti fait à partir d'autres sumti.
Leçons de lojban – Leçon seize (les sumti lojbans 3 - sumti dérivés)
Vous pouvez probablement voir que le sumti le bangu poi mi se bangu ke'a est une expression peu élégante pour « mon langage ». C'est parce que c'est une sacrée périphrase. Un langage que je parle peut être dit pour rendre compte du x1 du bridi bangu mi. Nous ne pouvons pas convertir cela en un sumti en utilisant un gadri : le bangu {ku} mi est composé de deux sumti, parce que bangu mi est un bridi et non pas un selbri. Nous ne pouvons pas non plus utiliser le su'u pour le convertir, parce que le su'u donne au bridi un nouveau x1, l'abstraction, que le extrait alors. Cela donne un sumti abstrait signifiant quelque chose de l'ordre de « ce quelque chose est mon langage ».
Voyons be. be est un mot qui relie des constructions (sumti, sumtcita et autres) à un selbri. L'utiliser dans des selbri ordinaires n'a aucun effet : dans mi nelci be do le be ne fait rien. Cependant quand un sumti est lié à un selbri de cette façon, vous pouvez utiliser un gadri sur le selbri sans diviser le sumti : le bangu be mi est une solution correcte au problème ci-dessus. De même vous pouvez attacher un sumtcita : le nu darxi kei be gau do : « l'évènement du coup, qui est causé par vous ». Notez que la présence ou l'absence du kei engendre une analyse syntaxique différente : avec le famyma'o présent be est lié à nu, sans le famyma'o il est lié à darxi. Cela décide donc de ce qui est souligné : est-ce le coup ou l'évènement qui est causé par vous? Quoique, dans ce cas précis, ce soit à peu près la même chose.
Qu'en est-il si je désire lier plusieurs sumti à un selbri à l'intérieur d'un gadri ? « Celui qui t'a donné la pomme » est le dunda be lo plise be do. Est-ce correct? Non. Le second be relie à « la pomme » signifiant le plise be do - la pomme de la variété de toi, ce qui n'a pas de sens. Pour relier plusieurs sumti à un selbri, tous ceux qui suivent le premier doivent être liés avec bei. L'ensemble des liaisons peut être terminé par be'o - une occurrence de be'o pour chaque selbri qui a des sumti liés par be.
Pour les lister :
- be = relie un sumti ou un sumtcita à un selbri.
- bei = relie un second, un troisième, un quatrième (ect...) sumti ou sumtcita à un selbri
- be'o = termine l'ensemble des liaisons au selbri.
Il y a aussi moyen d'associer librement un sumti à un autre. pe et ne sont utilisés pour les associations limitatives et non limitatives. En fait, le bangu pe mi est la meilleure traduction de « mon langage » puisque cette formule, comme en français, reste imprécise concernant la façon dont les deux sont en relation l'un avec l'autre.
pe et ne sont utilisés pour les associations libres uniquement, comme pour dire « ma chaise » à propos d'une chaise sur laquelle vous êtes assis. Elle n'est pas à proprement parler à vous, mais elle a quelque chose à voir avec vous. Une connexion plus intime peut être exprimée avec po qui marque une association unique et forte avec une personne comme pour « ma voiture » à propos d'une voiture qui vous appartient effectivement. Le dernier genre d'agent de liaison est po'e qui marque un lien qu'on peut dire « inaliénable » entre sumti, signifiant que le lien est inné entre les deux sumti. Par exemple cela peut être « ma mère », « mon bras » ou « mon pays d'origine »; aucune de ces « possessions » ne peut être perdue (même si vous vous coupez le bras, ça reste votre bras) elles sont donc inaliénables. Cependant, dans presque tous les cas où po'e est approprié, le x2 du selbri contient ce avec quoi le x1 est connecté, donc l'emploi de be est plus adapté.
- ne = phrase relative non limitative. "Qui est associé à ..."
- pe = phrase relative limitative. "Qui est associé à ..."
- po = phrase relative possessive. "Qui est spécifique à ..."
- po'e = phrase relative inaliénable. "Qui appartient à ..."
Une construction très utile est {gadri} {sumti} {selbri}. Elle est équivalent à {gadri} {selbri} pe {sumti}. Par exemple le mi gerku est équivalent à le gerku pe mi. On peut avoir un sumti descriptif à l'intérieur d'un sumti descriptif, disant le le se cinjikca be mi ku gerku = le gerku pe le se cinjikca be mi = « le chien de l'homme avec lequel je flirte », mais cela n'est pas facile à lire (ou à comprendre en cours de conversation), et cette forme est souvent évitée.
Il est aussi nécessaire d'apprendre tu'a, car il rend la construction de beaucoup de phrases bien plus simple. Il se rattache à un sumti et le convertit en un autre sumti - une abstraction non spécifiée qui a quelque chose à voir avec le premier sumti. Par exemple, je peux dire mi djica lo nu mi citka lo plise, ou bien je peux laisser le contexte éclairer quelle abstraction je désire à propos de la pomme et juste dire mi djica tu'a lo plise. On doit toujours deviner quelle abstraction le locuteur évoque en utilisant tu'a SUMTI, aussi il ne doit être utilisé que lorsque le contexte rend la déduction facile. Un autre exemple :
- gasnu = x1 fait x2 (volonté non impliquée)
za'a do gasnu tu'a lo skami - je vois que tu fais que l'ordinateur fait quelque chose. Officiellement, tu'a SUMTI est équivalent à le su'u SUMTI co'e Vague, mais utile. Dans certaines situations vous ne pouvez pas utiliser tu'a, bien qu'il semblerait approprié. Ces situations sont : quand je ne veux pas que le sumti résultant de l'opération soit une abstraction, mais un sumti concret. Dans ce cas, on peut utiliser zo'e pe.
tu'a convertit le sumti en une abstraction floue impliquant le sumti. Equivalent à le su'u SUMTI co'e kei ku.
Enfin, une sorte de sumti peut être transformée en une autre par les mots de la classe LAhE.
- lu'a = convertit le(s) individu(s)/la masse/la série/l'ensemble en individu(s).
- lu'i = convertit le(s) individu(s)/la masse/la série/l'ensemble en un ensemble.
- lu'o = convertit le(s) individu(s)/la masse/la série/l'ensemble individuel(les) en masse.
- vu'i = convertit le(s) individu(s)/la masse/la série/l'ensemble individuel(s) en série; l'ordre n'est pas stipulé.
L'usage de ces mots est sans surprise : les placer devant un sumti d'un certain type crée un nouveau sumti d'un nouveau type Remarquez cependant, qu'une quatrième sorte de sumti, la suite, a été introduite. Cela n'est pas utilisé très souvent, (il n'a pas son propre gadri, par exemple) , c'est juste signalé ici pour être complet.
Les deux derniers membres du groupe des LAhE n'opèrent pas de conversion entre groupes de sumti, mais permettent de parler d'un sumti juste en mentionnant quelque chose qui s'y rapporte :
Si un sumti A fait référence à un sumti B, par exemple parce que le sumti A est le titre d'un livre, ou un nom, ou une phrase (qui fait toujours référence à quelque chose, au minimum un bridi), la'e sumti A se rapporte au sumti B. Par exemple mi nelci la'e di'u pour « j'aime ce que tu viens de dire » (et non mi nelci di'u qui veut simplement dire « J'aime ta dernière phrase ») ou "la'e le cmalu noltru pour le livre " Le Petit Prince " et non pour un quelconque petit prince lui-même. Le cmavo lu'e fait exactement l'inverse - lu'e SUMTI fait référence à un objet qui fait référence au sumti.
- la'e = la chose à laquelle il est fait référence par - extrait un sumti A d'un sumti B qui fait référence à A.
- lu'e = la chose qui fait référence à - extrait un sumti B d'un sumti A, quand B fait référence à A.
Leçons de lojban - Leçon dix-sept (De petits mots assortis)
Et après ce troisième chapitre vous en savez un bout sur les sumti lojbans. Après une longue période d'apprentissage rigoureux et systématique, quoi de mieux que cette leçon dans laquelle je parle de mots que je n'ai pas pu, ou pas voulu introduire plus tôt ? Voici donc quelques petits mots très utiles :
Les cmavo suivants sont des mots elliptiques. Je crois que le premier ne vous est pas inconnu.
- zo'e = sumti elliptique
- co'e = selbri elliptique
- do'e = sumtcita elliptique
- ju'a = attitudinal d'évidence elliptique
- do'i = variable de parole elliptique
- ge'e = attitudinal elliptique
Tous agissent grammaticalement comme un cmavo du type qu'ils représentent, mais ils ne contiennent aucune information et peuvent être très pratiques si vous êtes paresseux et n'avez pas besoin de spécifier quoi que ce soit. Il y a toute fois quelques détails à éclaircir:
- zo'e doit faire référence à quelque chose qui a une valeur non nulle. "Aucune voiture" ou "rien" par exemple ont une valeur nulle ou pas de valeur et ne peuvent donc être remplacé par zo'e. Ceci, parce que sinon n'importe quel selbri pourrait être identique à sa négation, si l'un des sumti était remplacé par un zo'e n'ayant aucune valeur.
- ge'e ne signifie pas que vous ne ressentez aucune émotion, mais que vous ne ressentez rien qui mérite d'être mentionné sur le moment. C'est la même chose que "ça va". ge'e pei demande une émotion elliptique et est une bonne traduction pour "Comment ça va ?".
- co'e est pratique quand on a besoin d'un selbri dans une construction pour des raisons grammaticalles, comme dans la définition de tu'a dans la leçon précédente.
- ju'a ne change pas la valeur de vérité ou l'appréhension subjective du bridi, rien de ce genre. En fait il ne fait essentiellement rien. Quoi qu'il en soit, ju'a pei, "Sur quoi te bases-tu pour dire ça" est bien utile.
- do'i est vraiment utile. Très souvent quand on se référence à une parole ou une conversation avec des mots comme "ça" ou "c' " , on veut do'i.
Si on attache plus de sumti à un selbri qu'il n'a d'emplacement, le dernier sumti a un sumtcita implicite do'e devant lui.
Ensuite il y a le mot zi'o avec lequel on peut remplir un emplacement pour sumti, pour le supprimer d'un selbri. lo melbi be zi'o par exemple, est simplement "Quelque chose de beau", et n'inclut pas le x2 habituel de melbi, qui est l'observateur qui juge de la beauté de quelque chose. Ca peut donc vouloir dire quelque chose comme "Objectivement beau". Cela ne signifie pas que rien ne remplit l'emplacement qui est supprimer, mais que l'emplacement lui-même n'existe plus pour le selbri.Utiliser zi'o avec un sumtcita donne des résultats étranges. Formellement, chacun devrait annuler l'autre. En pratique, ce sera probablement compris comme un moyen explicite d'indiquer que le sumtcita ne s'applique pas comme dans : mi darxi do mu'i zi'o - "Je t'ai frappé, avec ou sans raison".
Puis il y a le mot jai. C'est un de ces petits mots sympas, difficile à appréhender, mais simple à manipuler une fois qu'on les connait. Il a deux fonction similaires mais distinctes. Les deux concerne la transformation de selbri, comme se.
- jai = transformation de selbri : transforme un sumtcita ou une abstraction non spécifiée en x1. Utiliser avec fai.
- fai = marqueur de place d'un sumti. Fonctionne comme fa. A utiliser avec jai.
La première utilisation grammaticale qu'on peut en faire est jai {sumtcita} {selbri}. Cela change les emplacements du selbri, de telle façon que l'emplacement du sumtcita devient le x1 du selbri, et l'ancien x1 du selbri est supprimé et seulement accessible en utilisant fai, qui fonctionne comme fa. On peut le voir avec cet exemple:
- gau = sumtcita (pour gasnu) "le bridi est à propos/avec l'agent actif {sumti}"
do jai gau jundi ti fai mi. - "Tu portes ceci à mon attention". Le nouveau selbri jai gau jundi, a la structure "x1 attire l'attention sur x2". x1 et x2 sont remplis par do et ti. fai est alors le marqueur de place de l'ancien x1, celui qui faisait attention, et est rempli avec mi. Ce mot peut-être vraiment pratique et a de nombreuses utilisations. Un bon exemple est les sumti descriptifs. On peut, par exemple faire référence à "la méthode de l'action volontaire" par lo jai ta'i zukte.
- ta'i = sumtcita (dérivé de tadji) "bridi est accomplit par la méthode {sumti}"
Pouvez-vous déduire la phrase lojbane classique do jai gau mo signifie ?
Réponse: “Qu'est-ce que tu fais ?”
L'autre fonction de jai est plus facile à expliquer. Il transforme simplement le selbri de façon que le sumti en x1 reçoive un tu'a devant lui (ko'a jai broda = tu'a ko'a broda). En d'autres termes, jai transforme le selbri en construisant une abstraction elliptique à partir du sumti en x1, et en remplissant ensuite x1 avec l'abstraction au lieu du sumti. De nouveau, l'emplacement x1 original est accessible avec fai.
Un utilisateur très actif du canal IRC lojban dit souvent le gerku pe do jai se stidi mi, pour utiliser un exemple quelconque de sumti en x1. Que dit-il ?
- stidi = x1 suggère x2 à x3
Réponse: “Je suggère (quelque chose à propos de) ton chien”
Jusqu'ici vous avez appris à transformer les bridi en selbri, les selbri en sumti et les selbri en bridi vu que les selbri sont en eux-même des bridi. Il manque une dernière fonction pour transformer les sumti en selbri. C'est le rôle du mot me. Il transforme un sumti en un selbri avec la structure "x1 fait partie de ce à quoi renvoie SUMTI".
- me = transforme un sumti en selbri. x1 fait partie de ce à quoi renvoie SUMTI".
me est immensément utile afin de dire des choses telles que “une belle Chrysler”. En utilisant un tanru, comment dirait-on cela?
Réponse: lo melbi me la .kryslr.
Et pour finir 3 mots pour corriger une erreur dans son discours… Ou 3 mots lojban pour formaliser le baffouillement.
- si = suppression: Efface uniquement le dernier mot.
- sa = suppression: Efface jusqu'au prochain cmavo exprimé.
- su = suppression: Efface le discours en entier.
La fonction de ces mots est évidente: Ils effacent les mots qui n'auraient jamais du être dit. Ils ne fonctionne pas à l'intérieur de certaines citations (Toutes sauf lu…li'u), sinon ils seraient impossible de citer ces mots. Plusieurs si à la chaîne effacent plusieurs mots (1 mot effacé pour chaque si).
Leçons de lojban - leçon dix-huit (citations)
Une des propriétés importantes voulues dans la conception du lojban est l'isomorphisme audio-visuel. Cela signifie que tout ce qui est exprimé à l'écrit doit l'être aussi à l'oral et vice versa. En conséquence toutes les marques de ponctuations doivent être prononcées. Le lojban a donc une grande quantité de mots servant à la citation d'autres mots. Tous ces mots-guillemets transforme un énoncé en sumti. Commençons par les plus simples:
- lu = Mot-guillemet: Commence une citation grammaticalement correcte
- li'u = Mot-guillemet: Finit une citation grammaticalement correcte
L'énoncé à l'intérieur de la construction lu…li'u doit être grammaticalement correct pris isolément. Cette construction peut servir à citer tous les mots lojban à quelques exceptions prêt, la plus évidente étant li'u.
Essayer de traduire la phrase suivante. Prenez votre temps.
mi stidi lo drata be tu'a lu ko jai gau mo li'u
- drata = x1 est différent de x2 selon la norme x3
Réponse: « Je suggère quelque chose d'autre que quelque chose à propos de ko jai gau mo. »
Les mots-guillemets suivants servent pour les énoncés grammaticalement incorrects. C'est parfois utile quand on veut extraire un morceau d'une phrase, comme dans: « Est-ce que « gi'e » est un sumtcita ? »
- lo'u = Mot-guillemet: Commence une citation grammaticalement incorrecte mais constituée de vocabulaire lojban.
- le'u = Mot-guillemet: Finit une citation grammaticalement incorrecte mais constituée de vocabulaire lojban.
L'énoncé à l'intérieur de la structure lo'u…le'u doit appartenir au vocabulaire lojban, mais n'est pas nécessairement correct du point de vue de la grammaire. Essayez de traduire l'exemple précédent (avec gi'e) en lojban.
Réponse: xu lo'u gi'e le'u lojbo sumtcita
Cette structure peut-être utilisée pour citer tous les mots lojban à l'exception de le'u. Mais ce n'est pas encore suffisant. Si nous voulons pouvoir dire en lojban « est-ce que do mo est une traduction correcte de « ça va ? » », nous avons besoin d'un nouveau mot : zoi. Remarque: do mo a une signification plus large que « ça va ? », la traduction n'est donc qu'approximative…
Le premier cmavo qui suit zoi sert de guillemet ouvrant et de guillemet fermant à une citation quelconque.
Quand on utilise zoi, on choisit n'importe quel mot lojban morphologiquement correct (appelé le délimiteur), qui sert alors de guillemet ouvrant. Une fois l'énoncé cité fini, on réutilise le même mot pour servir de guillemet fermant. De cette façon on peut citer tout sauf le délimiteur, ce qui ne pose pas de problème puisqu'on choisit le délimiteur qu'on veut. Selon l'usage c'est souvent zoi lui-même qui sert de délimiteur, ou une lettre qui rappelle la langue de l'énoncé cité. Par exemple : « J'aimais le Fantôme de l'Opéra » devient mi pu nelci la'e zoi zoi. le Fantôme de l'Opéra .zoi. Deux choses à remarquer: D'abord on a besoin de la'e car ce n'est pas l'énoncé que j'apprécie, mais ce à quoi il fait référence. Ensuite, entre le délimiteur et la citation, il y a des pauses, qu'on peut représenter par des points. Cette pause est nécessaire pour identifier correctement le délimiteur.
Essayez maintenant de traduire: Est-ce que do mo est une traduction correcte de « ça va ? »
- drani = x1 est adéquat dans l'aspect x2 dans la situation x3 d'après la norme x4
Réponse: xu lu do mo li'u drani xe fanva zoi fy. Ca va ? .fy. Ici le délimiteur fy est choisi pour rappeler le gismu fraso signifiant français.
la'o fonctionne exactement comme zoi, mais transforme la citation en un nom. On a besoin d'un cmavo spécifique car normalement seuls les selbri et les cmevla peuvent être des noms, pas les énoncés.
- la'o = fonctionne comme zoi, mais transforme la citation en en nom.
Le derniers des mots-guillemets est zo. zo transforme en citation le mot lojban qui le suit, quel qu'il soit. C'est assez pratique.
- zo = transforme le prochain mot lojban en citation.
Exemple: zo zo zo'o plixau = « zo est utile, héhé »
- zo'o = attitudinal discursif :pour rire.
- plixau = x1 est utile pour x2 pour le but x3
Les lojbanistes ont trouvé utile de rajouter quatre mots-guillemets supplémentaires. Ils sont tous expérimentaux et la grammaire formelle ne les reconnait pas. Néanmoins, ils sont souvent utilisés et c'est une bonne chose que de pouvoir les reconnaitre. Le plus fréquent est :
- zo'oi = transforme en citation le prochain mot uniquement. Le prochain est identifié par une pause dans le discours ou un espace à l'écrit.
Exemple: ri pu cusku zo'oi Toh! .u'i « Ha ha, il a dit « Toh! » »
Il est très facile à utiliser. Attention tout de même, les bots de grammaire considérerons la phrase comme incorrecte car zo'oi n'appartient pas à la grammaire officielle.
Analogue à zo'oi et la'o, la'oi fonctionne comme zo'oi mais transforme le mot cité en nom propre.
- la'oi = Cite le prochain mot uniquement et le transforme en nom propre. Le prochain mot est identifié par une pause dans le discours ou un espace à l'écrit.
Comment diriez-vous : « Mon nom français est « Safi » » ?
- fraso = x1 appartient à la culture français dans l'aspect x2
- cmene = x1 est le nom de x2 utilisé par x3
Réponse: mi fraso se cmene la'oi Safi. Remarquez que se est nécessaire. Nous ne voulons certainement pas dire que nous sommes un nom ! u'i
Le troisième mot-guillemet expérimental, ra'oi, cite le rafsi suivant. Comme les rafsi ne sont pas des mots, ils sont habituellement cités en utilisant zoi. Mais plusieurs rafsi sont aussi des cmavo. Pour éviter la possible confusion, ra'oi fait toujours référence au rafsi, et est incorrect devant n'importe quel texte qui n'est pas un rafsi.
Que signifie ra'oi zu'e rafsi zo zukte .iku'i zo'oi zu'e sumtcita ?
- ku'i = attitudinal discursif: indique que ce qui suit contraste avec ce qui précède.
- rafsi = x1 est un affixe de x2 de forme x3 dans la langue x4
Réponse:« Le rafsi zu'e est un rafsi pour zukte. Alors que zu'e est un sumtcita. »
Et pour finir le très utile ma'oi.ma'oi cite n'importe quel cmavo, mais traite la citation comme un nom pour la classe à laquelle appartient le cmavo (selma'o). Par exemple, ba'o appartient à la classe appelée ZAhO, donc ma'oi ba'o est un nom lojban non officiel pour ZAhO.
Essayez de dire que pu et ba sont dans la même selma'o !
Réponse possible: zo pu cmavo ma'oi ba
Leçons de lojban - leçon dix-neuf (les nombres)
Souvent, lorsqu'on apprend une langue, une des premières choses qu'on voit c'est comment compter. Ce qui est plutôt étrange, puisqu'il ne sert à rien de connaître les nombres si on ne sait pas parler de ce à quoi ils s'appliquent. C'est une première raison pour laquelle ils arrivent si tard. L'autre raison est que, si les nombres en eux-mêmes sont faciles à apprendre, la façon de les appliquer aux sumti n'est pas évidente. Mais nous verrons cela dans une leçon future.
Avant toutes choses, vous devez savoir que les nombres n'ont pas de grammaire interne. Cela signifie que toutes les suites de nombres ont le même statut pour la grammaire lojban, même une suite qui n'a aucun sens. De ce fait, il y a toujours une ambiguïté pour savoir si une suite de nombre a du sens ou pas. Quoi qu'il en soit il y a des façons prévue d'utiliser les nombres et en dévier peu être problématique.
Apprendre tous les nombres lojbans irait bien au delà du but de cette leçon, qui se contentera de vous présenter ce qui est normalement utilisé dans les textes. La grande famille des cmavo mathématiques sont appelés mekso (lojban pour « expression mathématique »), et sont largement inusités du fait de leurs complexité et du caractère douteux de leur avantage sur ce qu'on appelle les bridi mathématiques.
Commençons avec les nombres lojban les plus ordinaires, de zéro à neuf:
On peut remarquer le schéma de voyelle a-e-i-o-u (sauf pour no) et qu'il n'y a pas deux fois la même consonne pour deux chiffres différents. Pour les nombres plus grands que neuf, on aligne les « chiffres » comme dans une numération de position: vo mu ci – quatre cent cinquante-trois (453) pa no no no no – dix mille (10 000) Il y a aussi un cmavo, xo, pour demander « Quel nombre ? ». La réponse à une telle question peut-être juste le nombre correspondant, ou bien une construction numérique, comme nous le verrons plus loin. ci xo xo xo – « Trois mille combien ? » (3???)- xo = – question « Quel nombre/chiffre ? » – peut-être utilisé comme un chiffre pour demander quel est le chiffre correct.
- xo'e = – chiffre/nombre elliptique
| dau | fei | gai | jau | rei | xei | vai | |
| 10(A) | 11(B) | 12(C) | 13(D) | 14(E) | 14(E) | 15(F) |
Oui il y a deux mots pour E. rei est le mot officiel (Tous les cmavo de trois lettres commençant par x sont expérimentaux). xei a été proposé pour éviter la confusion avec re.
On peut spécifier la base numérique avec ju'u. On utilise ju'u entre le nombre dont on veut spécifier la base et la base elle-même exprimée en base 10.
"dau so fei no ju'u pa re – A9B0 en base 12
Et maintenant les fractions. Elles sont habituellement exprimées à l'aide d'une virgule décimal : pi.
- pi = – virgule décimale (ou virgule de la base dans laquelle vous êtes)
pa re pi re mu – douze virgule vingt-cinq (12,25).
S'il n'y a pas de nombre avant ou après la virgule on suppose que cela vaut pour zéro.
A côté de pi il y a le séparateur de nombre pi'e, soit pour séparer les chiffre dans une base supérieure à seize, soit dans un système de numération sans virgule, par exemple pour exprimer le temps en heures, minutes, secondes.
pa so pi'e re mu pi'e no ju'u ze re – dix-neuf, vingt-cinq, zéro en base vingt-sept (JP0 en base 27).
re re pi'e vo bi – vingt-deux, quarante huit (22:48)
Il y a aussi des nombres qui ne sont pas mathématiques, mais plutôt subjectifs ou relatifs. Leur comportement est presque exactement le même que celui des précédent, sauf qu'il ne peuvent se combiner pour faire des nombres plus grands.
| ro | so'a | so'e | so'i | so'o | so'u | |
| tous | presque tous | la plupart | beaucoup | certains | peu | |
Quand ils sont combinés avec les nombres précédents, ils donnent un second verdict à propos de la taille du nombre:
mu bi so'i sai – Cinquante-huit, ce qui est vraiment beaucoup.
Ils ne doivent donc pas être placés au milieu d'une chaîne de nombres.
Placés après pi ils signifient la taille d'une fraction:
- pi so'u – une petite partie de
- pi so'o – une certaine quantité de
- pi so'i – une grande partie de
- pi so'e – la plupart de
- pi so'a – presque tout de
Ensuite il y a des nombres très subjectifs - qui fonctionnent exactement comme les précédents.
| du'e | mo'a | rau |
| trop | pas assez | assez |
Les cinq suivants dépendent du contexte – ils fonctionnent comme les précédents, sauf qu'ils prennent en compte le nombre suivant dans leur signification:
| da'a | su'e | su'o | za'u | me'i |
| tout sauf n | au plus n | au moins n | plus que n | moins que n |
Où n est le nombre suivant. S'il n'y en a pas la valeur par défaut est « un ».
so'i pa re da'a mu – beaucoup, douze ce qui est tous sauf cinq.
Les deux derniers nombres ont une grammaire un peu plus complexe:
- ji'i = – approximation numérique
Quand ji'i est placé avant un nombre, le nombre entier est une approximation:
ji'i ze za'u rau ju'o – « Environ sept ce qui est plus qu'assez, certainement ».
Si ji'i est placé au milieu d'un nombre, seul les chiffres qui le suivent sont approximatifs. A la fin d'un nombre, il signifie que le nombre a été arrondi.
- ki'o = – séparateur de paquet de nombres. Milliers.
Ce n'est pas par hasard que ki'o ressemble au préfixe kilo. ki'o est d'abord utilisé pour séparer les paquets de trois chiffres dans les grands nombres:
pa ki'o so so so ki'o bi xa ze – 1 999 867
Si moins de trois chiffres sont placés avant ki'o, les chiffres présents sont ceux de plus faibles poids et les trous sont comblés par des zéros:
vo ki'o ci bi ki'o pa ki'o ki'o – 4 038 001 000 000
ki'o s'utilise de la même façon après une virgule.
Et c'est tout pour les nombres lojban. Comment ils s'appliquent aux sumti est un gros morceau qu'on laisse pour la leçon vingt-deux. Maintenant nous allons voir comment on les utilise dans un bridi. Un nombre est grammaticalement correct en lui-même puisqu'il peut-être la réponse à une question de type xo. Mais dans ce cas ils ne font partie d'aucun bridi. En général, quand un nombre s'intègre dans un bridi il a deux formes possibles : nombre pur ou quantité. Par exemple: « 42 est un nombre qui a une histoire intéressante » et « 42 chemins à parcourir, ça fait beaucoup ». On garde les quantités pour une prochaine leçon, pour l'instant intéressons nous aux nombres purs.
Un nombre pur est préfixé par li. li transforme un nombre en sumti et fait référence à l'entité mathématiques.
- li = – converti un nombre/une mekso en sumti
- lo'o = – famyma'o: termine un sumti commencé par li.
C'est généralement ce genre de sumti qui remplit le x2 de brivla comme mitre ou cacra.
- mitre = – x1mesure x2 mètres en dimension x3 selon le standard x4
- cacra = – x1 dure x2 heures (une par défaut) selon le standard x3
Essayer de traduire ceci:
le ta nu cinjikca cu cacra li ci ji'i u'i nai
Réponse: « grmpf, ça fait dans les trois heures que ce flirt dure. »
Comment compte-t-on jusqu'à trois en lojban ?
Réponse: li pa li re li ci
Pour finir cette leçon nous allons voir les selma'o MAI et MOI.
MAI ne contient que deux mots, mai et mo'o. Les deux transforment un nombre en un ordinal qui obéit aux mêmes règles que les attitudinaux. Les ordinaux sont utilisés pour diviser un texte en segments numérotés, comme des chapitres et des parties. La seule différence entre mai et mo'o est que mo'o s'applique à de plus grande subdivisions, permettant deux niveaux de découpage du texte, par exemple en chapitres énumérés avec mo'o et sections avec mai. Remarque : comme avec MOI les nombres sont utilisés directement sans li.
- mai = – Converti un nombre en ordinal. Echelle inférieure.
- mo'o = – Converti un nombre en ordinal. Echelle supérieure.
Il y a cinq cmavo dans la selma'o MOI, et tous transforment n'importe quel nombre en selbri.
- moi = – transforme un nombre n en le selbri: x1 est n-ième membre de l'ensemble x2 selon l'ordre x3.
Exemple: la lutcimin ci moi lo'i ninmu pendo be mi le su'u lo clani zmadu cu lidne lo clani mleca – « Lui-Chi Min est la troisième de mes amies selon l'ordre: Les plus grandes précèdent les moins grandes ».
Remarque: quand on spécifie une séquence, il est généralement admis que si une abstraction introduite par ka (leçon vingt-neuf) est utilisée comme sumti, les membres sont ordonnés de celui avec la plus grande valeur dans cette propriété à celui avec la moins grande valeur. Donc le x3 de la phrase précédente peut ce raccourcir en lo ka clani.
- lidne = – x1 est avant x2 dans la séquence x3
- clani = – x1 est long en dimension x2 selon la norme x3
- zmadu = – x1 est plus grand que x2 selon la propriété x3, de la quantité x4
- mleca = – x1 est plus petit que x2 selon la propriété x3, de la quantité x4
- mei = – transforme un nombre n en le selbri: x1 est une masse extraite de l'ensemble x2, ayant les n éléments x3
Remarque: x3 est supposé être des individus, x2 un ensemble et x1 une masse.
Que signifie mi ci mei ?
Réponse: « Nous sommes un groupe de trois ».
- si'e = – transforme un nombre n en le selbri: x1 est n fois x2.
Exemple: le vi plise cu me'i pi pa si'e lei mi cidja be ze'a lo djedi – « Cette pomme, là, représente moins d'un dixième de ma nourriture pour une journée ».
Remarque: la définition officiel de si'e est « x1 est un n-ième de x2 » au lieu de « x1 est n fois x2 ». Mais tout le monde utilise cette définition alternative, la définition du dictionnaire va donc probablement changer.
- cu'o = – transforme un nombre n en le selbri: x1 a la probabilité n sous les conditions x2
Exemple: lo nu mi mrobi'o cu pa cu'o lo nu mi denpa ri – « L'événement que je meurs a une probabilité 1 sous la condition: j'attends que ça arrive » = « Il est certain que je vais mourir si j'attends assez longtemps ».
- denpa = – x1 attends x2, en l'état x3 avant de continuer x4.
- va'e = – transforme un nombre n en le selbri: x1 est en n-ième position sur l'échelle x2.
Exemple: li pa no cu ro va'e la torinon – « 10 est en dernière position sur l'échelle de Turin » ou « 10 est le maximum sur l'échelle de Turin »
Leçons de lojban - leçon vingt (bo, ke, co et autre mots de groupement)
Disons que vous soyez un important acheteur canadien d'ordinateur. Comment dites vous ça ? Pour une construction comme ça l'outil idéal est le tanru : mi vajni te vecnu kadno skami. En fait non, ça ne va pas. Les tanru sont groupés de la gauche vers la droite, donc ce tanru se comprend : ((vajni te vecnu) kadno) skami, un ordinateur pour des canadiens qui sont d'importants acheteurs. On peut un peu améliorer les choses en changeant l'ordre des selbri : mi vajni kadno skami te vecnu, je suis un acheteur d'ordinateurs pour canadiens importants... Mais ça ne va pas suffire. On ne peut pas non plus s'en sortir avec des connecteurs logiques, qu'on ne vera que plus tard de toutes façons. Le seul moyen de faire un tanru correct est de forcer les selbri à se grouper différemment.
Pour lier fortement ensemble deux tanru dans un groupement on peut placer le mot bo entre les deux : mi vajni bo kadno skami bo te vecnu se lit mi (vajni bo kadno) (skami bo te vecnu), ce qui ressemble à ce qu'on veut. Si bo est placé entre plusieurs selbri à la suite, ils sont groupés de droite à gauche : mi vajni kadno bo skami bo te vecnu se lit mi vajni (kadno bo (skami bo te vecnu)), je suis un important (canadien (acheteur d'ordinateur)), ce qui est encore meilleur.
- bo = lie fortement ensemble deux selbri.
Comment diriez-vous « C'est une pomme jaune délicieuse » ?
- kukte = x1 est délicieux selon x2
Réponse : ti kukte pelxu bo plise
Et « C'est une grande pomme jaune délicieuse » ?
Réponse : ti barda kukte bo pelxu bo plise
Une autre façon de grouper les selbri est d'utiliser les mots ke...ke'e. On peut les voir comme un équivalent des parenthèses dans le paragraphe précédent. ke commence un groupe de selbri fortement liés, ke'e le termine.
- ke = commence un groupe de selbri fortement liés
- ke'e = termine un groupe de selbri fortement liés
La force de la liaison est la même que pour bo. Donc, mi vajni kadno bo skami bo te vecnu est équivalent à mi vajni ke kadno ke skami te vecnu {ke'e} {ke'e}.
Comment diriez-vous « Je suis un vendeur de maisons jaunes allemand » ?
Réponse: mi dotco ke pelxu zdani vecnu
Puisque que nous nous amusons avec la structure ordinaire des tanru, il y a un autre cmavo qui nous concerne. Si je veux dire que je suis un traducteur professionnel (je ne le suis pas), je peux dire mi fanva se jibri.
- jibri = x1 est un boulot de x2
- fasybau = x1 est du français utilisé par x2 pour exprimer x3
- glibau = x1 est de l'anglais utilisé par x2 pour exprimer x3
Si je veux maintenant dire que je suis un traducteur professionnel de l'anglais vers le français, je vais devoir jongler avec les be et les bei : mi fanva be lo fasybau bei lo glibau be'o se jibri, et le fait que c'est un tanru peut vite être perdu de vue dans le discours vu la complexité de la construction. Heureusement on peut utiliser co qui inverse les position d'un tanru, de sorte que le selbri de droite modifie le selbri de gauche : mi se jibri co fanva le fasybau le glibau est le même bridi que le précédent, mais beaucoup plus facile à comprendre. Remarquez que les selbri précédent le tanru remplirait les emplacements de se jibri alors que ceux qui suivent sont arguments de fanva.
- co = Inverse les position d'un tanru. Chaque sumti précédent le tanru est argument de la partie modifiée, chaque sumti suivant est argument du modificateur.
co lie très faiblement les selbri, plus faiblement encore que dans un tanru sans modificateur, de sorte dans un construction avec co la partie la plus à gauche est toujours la partie modifiée et la partie la plus à droite, toujours le modificateur, même si ces parties sont elles-mêmes des tanru. Cela rend cette construction facile à parser : ti pelxu plise co kukte se lit ti (pelxu plise) co kukte, ce qui est équivalent à ti kukte pelxu bo plise. Cela implique qu'une construction ke...ke'e ne peut jamais enjamber un co
Les cmavo de la selma'o GIhA, les connecteurs logiques des queues de bridi, lient encore plus faiblement que co. Ceci de façon à éviter toute confusion sur quel selbri est lié à quel autre dans une construction avec GIhA. La réponse est simple : GI'A ne contient jamais de groupe de selbri.
Comment diriez-vous « Je suis un important acheteur canadien d'ordinateur » en utilisant co ?
Réponse : mi skami te vecnu co vajni kadno
A toutes fins utiles, la liste des groupeurs de selbri ordonnée selon la force de la liaison :
- bo et ke..ke'e
- les connecteurs logiques autres que la selma'o GIhA
- tanru sans mot de groupement
- co
- GIhA
Le reste de la leçon laisse de côté les groupements pour s'intéresser à quelques mots utiles.
bo a une autre utilisation, a priori différente du groupement de selbri : il peut aussi lier un sumtcita à un bridi entier, de sorte que le contenu du sumtcita n'est plus un sumti, mais le bridi suivant entier. Voyons sur un exemple.
- xebni = x1 déteste x2
mi darxi do .i mu'i bo mi do xebni _ « Je te frappe, au motif que je te déteste. » Ici bo lie mu'i au bridi qui le suit.
C'est ici que la différence technique entre les sumtcita de « temps » et les autres est importante. Quand on lie un sumtcita normal à un bridi avec bo, cela signifie que d'une manière ou d'une autre ce bridi joue le rôle de sumti pour le sumtcita. Par contre, lier ba ou pu à un bridi a l'effet inverse. Pourquoi ? Parce que c'est comme ça ! Par exemple, dans le bridi mi darxi do .i ba bo do cinjikca, on pourrait croire que le second bridi est l'argument de ba, et que le premier bridi se passe dans le futur du second. Mais non. La traduction correct est ici : « Je te frappe. Ensuite tu flirtes. » Cette règle bizarre est le principal obstacle à l'unification de tous les sumtcita dans une seule classe. Une autre différence est que les sumtcita de « temps » peuvent être éludés, et s'appliquer quand même. C'est assez naturel, puisqu'on peut souvent supposer qu'un bridi prends place dans l'espace temps alors qu'on ne peut pas savoir si un sumtcita de BAI s'applique.
Le mot me'oi, non-officiel, est l'équivalent de me la'e zo'oi, ce qui signifie qu'il transforme le contenu du prochain mot en selbri. On l'utilise pour créer des brivla à la volée : mi zgana la me'oi X-files pour « Maintenant je regarde X-files ». Comme tous les mots-guillemets servant à citer le prochain mot ou le prochain cmavo, il n'est pas dans la grammaire officielle, mais il est de grande valeur pour le lojbanophone paresseux.
Le mot gi est une sorte de séparateur de bridi bizarre, semblable à .i, mais apparemment utilisé seulement dans deux types de construction : Le plus souvent avec un connecteur logique, que nous verrons dans la leçon vingt-cinq, mais aussi avec des sumtcita. Avec les sumtcita gi crée une construction utile mais rare :
mu'i gi BRIDI-1 gi BRIDI-2, qui est équivalente à BRIDI-2 .i mu'i bo BRIDI-1. En conséquence, l'exemple ci-dessus expliquant pourquoi je te frappe, peut s'écrire : mu'i gi mi xebni do gi mi darxi do, ou pour préserver l'ordre original, on peut transformer mu'i avec se : se mu'i gi mi darxi do gi mi xebni do.
C'est dans ce genre d'exemple que gi fait montre de sa polyvalence. Il ne sépare pas seulement les bridi comme un simple .i, il peut aussi séparer deux constructions à l'intérieur d'un bridi, de sorte que les constructions hors du champ de gi s'appliquent aux deux bridi. Sur un exemple c'est plus clair :
- cinba = x1 embrasse x2 à l'endroit x3
mi ge prami do gi cinba do laisse mi en dehors de la construction, et le fait donc s'appliquer aux deux bridi. On peut aussi le faire avec do qui apparait dans les deux bridi. mi ge prami gi cinba vau do. Remarque : vau est nécessaire pour que do ne soit pas compris dans le deuxième bridi.
Finalement nous pouvons écrire la première phrase plus brièvement : mi mu'i gi xebni gi darxi vau do, ou pour enlever même le vau, on peut écrire encore plus élégament : mi do mu'i gi xebni gi darxi
Leçons de lojban - Leçon vingt et un (COI)
Dans cette leçon vous aller vous familiariser avec les vocatifs, ou ma'oi coi. Ils méritent leur propre leçon, non pas parce qu'ils donnent une base pour comprendre la grammaire lojban en général, ou parce qu'ils sont particulièrement difficiles à utiliser, mais parce qu'ils sont couramment utilisés et qu'il y en a beaucoup. Un vocatif est, entre autre, utilisé pour définir à qui do fait référence. Si le vocatif est suivi par un cmevla, celui-ci prend un la implicite comme gadri. Si c'est un selbri qui suit le vocatif, on considère qu'il est précédé par un le.
Dans ces exemples, je vais utiliser le vocatif coi, qui signifie « bonjour » ou « salut ».
Si un lojbaniste s'appelle la + SELBRI, s'adresser à lui en utilisant un vocatif suivi du selbri seul est généralement une erreur puisque cela signifie que vous le considérez comme le x1 de ce selbri. Par exemple si quelqu'un s'appelle la tsani, Ciel, dire coi tsani désigne cette personne comme le tsani, et ça veut donc dire « Salut le ciel ». Ce qu'on veut dire, « Salut, Ciel » se traduit correctement : coi la tsani. C'est une erreur fréquente chez les lojbanistes débutants. Tous les vocatifs ont un famyma'o qui est parfois nécessaire : do'u. Le plus souvent, il est utilisé quand le premier mot suivant la partie vocative et le dernier mot de cette partie sont tous deux des selbri, ceci pour éviter de créer un tanru.
- do'u = Terminateur de vocatif. Généralement facultatif.
- klaku = x1 pleure les larmes x2 pour la raison x3
coi la gleki do'u klaku fi ma « Salut Joyeux. Pourquoi des pleurs ? »
Le vocatif générique, doi, ne fait rien d'autre que définir à qui do fait référence :
doi .pier. xu do fraso kadno « Pierre, es-tu canadien français ? »
Tous les autres vocatifs font quelque chose de plus que spécifier do. Par exemple coi, comme vous l'avez vu, signifie aussi « Salut ». Beaucoup de vocatifs admettent des variations avec nai et l'un d'entre eux (ju'i) avec cu'i, comme les attitudinaux.
Quelques vocatifs importants sont listés ci-dessous., Il y en a d'autres, mais il ne sont pas tellement utilisés.
| Vifatof | Sans suffixe | cu'i | nai |
|---|---|---|---|
| coi | Bonjour | ||
| co'o | Au revoir | ||
| je'e | Compris / OK | Pas OK | |
| fi'i | Bienvenue | Pas bienvenue | |
| pe'u | S'il vous plait | ||
| ki'e | Merci | Pas merci... | |
| re'i | Prêt à recevoir/écouter | Pas prêt | |
| ju'i | Ho (écoutez!)! | Hum | Laissez tomber (ignorez-moi) |
| ta'a | Interruption | ||
| vi'o | Vais le faire | Ne vais pas le faire | |
| ke'o | Répétez svp | Pas besoin de répéter. | |
| di'ai | Bénédiction | Malédiction |
Remarque : di'ai est expérimental
Que signifie coi co'o ?
Réponse:« Bonjour-au-revoir » ou « Bonjour en passant »
je'e est utilisé comme « OK », mais est aussi approprié en réaction à un souhait ou un remerciement. Dans ce cas c'est un accusé de bonne réception.
Traduisez : ki'e sidju be mi bei lo vajni .i je'e .pier.
- sidju = x1 aide x2 pour x3
Réponse : « Merci, à toi aide de moi dans quelque chose d'important. De rien, Pierre »
Et fi'i te vecnu .i pe'u ko citka
Réponse : « Bienvenue, client. S'il vous plait, manger ! »
re'i est utilisé pour signifier que vous êtes prêt à écouter. On peut l'utiliser comme un équivalent de « Que puis-je faire pour vous » ou « Oui ? », ou bien d' « allo » au téléphone. re'i nai peut signifier « AFK » ou « Je reviens tout de suite ».
Traduisez : « Que puis-je faire pour vous, Traducteur ? »
Réponse : coi re'i la fanva
ta'a s'utilise pour essayer d'interrompre poliment quelqu'un.
Traduisez : ta'a ro do mi co'a cliva
- cliva = x1 quitte x2 par l'itinéraire x3
Réponse :~~grey,grey: « Excusez-moi tous, je commence à partir. »
Remarque : il n'y a besoin ni de famyma'o ni de .i~~
ke'o est très utilisé quand deux lojbanistes inexpérimentés se parle oralement. C'est un mot très pratique.
- sutra = x1 est rapide à faire x2
Traduisez : .y ke'o sutra tavla
Réponse :« Heu, répétez, s'il vous plait, orateur rapide. »
Traduisez : « D'accord, d'accord, j'ai compris, je vais le faire ! »
Une réponse possible : ke'o nai .ui nai vi'o
Leçons de lojban - Leçon vingt-deux (quantification des sumti)
La plupart des références pour l'apprentissage du lojban comme "The Complete Lojban Language" et "Lojban for Beginners" ont été écrites avant l'adoption officiel de « xorlo », un changement des règles sur la définition et la quantification des sumti. L'obsolescence d'une partie des textes de référence a été une des motivations principales pour l'écriture de ces leçons.
Malheureusement pour moi, la quantification des sumti devient un sujet très complexe quand on entre dans les détails des conséquences de certaines règles. Afin de remplir le rôle de ces leçons d'êtres suffisamment précises pour représenter le « standard officiel » des règles du ((BPFK)), ce chapitre a été l'un des derniers terminés et l'un des plus souvent remaniés. Si vous trouvez des erreurs dans ce chapitre, je vous recommande fortement de contacter l'auteur original et ((le traducteur|lomicmenes)) pour qu'elles soient corrigées.
Ceci étant dit, commençons la leçon :
Le premier concept à connaître est la « distributivité ». Dans la leçon quatorze j'ai utilisé le mot « individus » pour un groupes d'objets considérés distributivement. Un groupe ko'a est distributif pour n'importe quel selbri broda si quand ko'a broda est vrai cela implique que chaque membre de ko'a est aussi caractérisé par broda. La distributivité fonctionne en contraste de la non-distributivité (dans le cas des masses). Dans le cas non-distributif, le groupe a d'autres propriétés que celles de chacun de ses membres. La distinction entre les deux cas est d'importance quand on veut quantifier les sumti.
Regardons d'abord comment quantifier les sumti descriptifs, qui sont les sumti de la forme GADRI BRIVLA. Le nombre qui quantifie peut être placé avant le gadri, auquel cas on parle de quantificateur externe, ou il peut être placé entre le gadri et le brivla, on parle alors de quantificateur interne. N'importe quelle chaîne de nombre peut servir de quantificateur.
Les effets des quantificateurs externes et internes dépendent du gadri utilisé :
- lo et le. Un quantificateur interne spécifie le nombre d'objet dont on parle au total. Si un quantificateur externe est présent, le sumti est distribué parmi ce nombre d'objects. Comme dit précédemment, si il n'y a pas de quantificateurs externes on ne spécifie pas à combien d'objets le selbri s'applique (au minimum un), ni s'il s'applique distributivement ou non. C'est plus clair sur quelques exemples :
mu lo mu bakni cu se jirna - Cinq comme quantificateur interne indique que nous parlons de cinq pièce de bétail. Cinq comme quantificateur externe indique que le selbri s'applique à chacun des cinq. Donc cela signifie : « Les cinq vaches ont des cornes ».
- bakni = x1 est une pièce de bétail de type x2
- jirna = x1 est une corne de x2 (Métaphore : n'importe quelle extrémité pointue)
Que signifie le bridi suivant ?
lo ru'ugubupu be li re pi ze mu cu jdima lo pa re sovda
- ru'urgubupu = x1 vaut x2 livres britannique (GBP)
- jdima = x1 est le prix de x2 pour l'acheteur x3 fixé par le vendeur x4
- sovda = x1 est un gamète (sperme/oeuf) de x2
Réponse : « Douze oeufs coûtent 2.75 livres ». Il y a ici une ambiguité, puisqu'on ne sait pas si le selbri s'applique distributivement ou non, et donc on ne sait pas si 2.75 livres est le prix d'un oeuf ou d'une douzaine.
so le ta pa pa ci'erkei cu clamau mi (Remarque : le ta prends place devant le quantificateur interne)
- ci'erkei = x1 joue au jeu x2 avec les règles x3 et les composants x4 (Remarque : ci'erkei traduit « jouer » au sens jouer à un jeu, plutôt que jouer d'un instrument, ou dans une pièce de théâtre.
- clamau = x1 est plus long que x2 dans la direction x3 de la quantité x4
Réponse : le quantificateur interne indique qu'on parle d'un total de 11 joueurs. Le quantificateur externe indique que le selbri s'applique à 9 d'entre eux distributivement. On traduit donc par : « Neuf des onze joueurs sont plus grand que moi. »
Il y a quelques points à approfondir en ce qui concerne la quantification de lo et le.
D'abord, lo est spécifique en ceci que {nombre} {selbri} est défini comme {nombre} lo {selbri}. En conséquence, ci gerku cu batci re nanmu est équivalent à ci lo gerku cu batci re lo nanmu et les deux groupes sont distributifs. C'est-à-dire que chacun des trois chiens a mordu chacun des deux hommes, soit six morsures au total.
- batci = x1 mord x2 à l'endroit x3 utilisant x4
Ensuite : que se passe-t-il s'il n'y a pas de quantificateur externe ? Cela signifie-t-il qu'il est virtuellement présent mais
implicite ? Non. N'importe quel type de quantificateur externe, implicite ou non, force le sumti à être distributif. En conséquence il serait impossible d'utiliser le ou lo pour décrire des masses. Et donc, s'il n'y a pas de quantificateur externe, il n'est pas juste implicite : il n'y a pas de quantificateur externe ! Les sumti sans quantificateur externe peuvent être appelés « constantes », mais on ne va pas le faire ici.
Troisièmement, il est absurde d'avoir un quantificateur externe supérieur au quantificateur interne. Cela signifierait que le selbri s'applique à plus de sumti qu'il n'y en a dans le discours, mais comme ils apparaissent dans le bridi ils font partie du discours… C'est néanmoins grammaticalement correct.
Enfin, mettre un lo ou un le devant un sumti est correct si un quantificateur interne est présent. lo/le {nombre}{sumti} est défini comme lo/le {nombre} me {sumti}.
Alors que veut dire : mi nelci loi mi briju kansa .i ku'i ci lo re mu ji'i ri cu lazni
- briju = x1 est un bureau du travailleur x2 à l'endroit x3
- kansa = x1 accompagne x2 dans x3
- lazni = x1 est fainéant en ce qui concerne x2
Réponse : « J'apprécie mes collègues, mais trois parmi environs vingt-cinq d'entre eux sont fainéants »
- la. Un quantificateur interne est correct si le nom est un selbri - dans ce ca il fait partie du nom. Un quantificateur externe sert à quantifier distributivement sur des objets du type nommé (comme avec lo/le). C’est correct placé devant {nombre} {sumti}, et dans ce cas, le nombre et le sumti font partie du nom.
C’est plus clair sur un exemple : re la ci bargu cu jibni le mi zdani
Traduction: Deux "Les Trois Arches" sont près de ma maison (Peut-être que "Les Trois Arches" est une chaîne de restaurant ?)
- loi et lei. Un quantificateur interne précise combien de membres composent la ou les masses en question. Un quantificateur externe quantifie distributivement {!} sur les dites masses. Bien que les masses consistent en des collections d'objets considérés non distributivement, un quantificateur externes traite chacune des masses comme un individu.
Quand il est placé devant {nombre} {sumti}, loi/lei se définit comme "lo gunma be lo/le {nombre} {sumti}" - "La masse composée de {nombre} de {sumti}".
Essayez de traduire : dei joi di'e gunma re loi bi valsi .i ca'e dei jai se jalge lo nu jetnu
- gunma = x1 est une masse composée des éléments x2 considérés joints
- valsi = x1 est un mot signifiant x2 dans la langue x3
- ca'e = Attitudinal : Evidence: Je définis
- jetnu = x1 est vrai selon l'épistémologie x2
Réponse : "Cette phrase-ci, combinée avec la suivante, forme une masse composée de deux masses de huit mots chacune. Je définis : cette phrase-ci fait que {cela} est vrai."
- lai. Presque comme la, un quantificateur interne (quand le nom est un selbri) fait partie du nom. Un quantificateur externe quantifie distributivement. S'il est placé devant {nombre} {sumti}, le nombre et le sumti font partie du nom.
Quand on utilise une fraction comme quantificateur externe de loi, lei ou lai, on ne parle que d'une partie de la masse. Par exemple : "La moitié des Dupont" - pi mu lai .dupon.
- lo'i et le'i. Un quantificateur externe précise le nombre d'éléments de l'ensemble. Un quantificateur externe distribue sur plusieurs ensemble identiques. Placé devant {nombre} {sumti}, cela se comprend comme "lo selcmi be lo/le {nombre} {sumti}" - "L'ensemble de {nombre} {sumti}".
Traduisez lo'i ro se cinki cu bramau la'a panono lo'i ro se bogykamju jutsi
- cinki = x1 est un insecte de l'espèce x2
- la'a = Attitudinal: Discursif: Probablement
- bramau = x1 est plus grand que x2 en dimenseion x3 de la quantité x4
- bogykamju = x1 est la colonne vertébrale de x2
- jutsi = x1 est l'espèce du genre x2 de la famille x3... (classification ouverte)
Réponse : "L'ensemble de toutes les espèces d'insecte est probablement plus grand que cent ensembles de toutes les espèces de vertébrés "
- la'i. Comme pour lai
Comme avec le gadri de masse un quantificateur externe devant un gadri d'ensemble permet de parler d'une fraction de l'ensemble. Devant {nombre} {sumti} cela se comprend "lo selcmi be la {nombre} {sumti}" - "L'ensemble formé par Les {Nombre} {Sumti}" considéré comme un nom.
- lo'e et le'e. Ne sont pas dans la liste des propositions de gadri accéptées à l'heure actuelle. Si on voulait leur appliquer les règles d'un autre gadri, lo/le serait probablement le meilleur choix. En effet les deux s'appliquent à des individus plutôt qu'à des groupes. Dans ce cas le quantificateur externe distribuerait sur une partie de la quantité de choses typiques/stéréotypiques indiquée par le quantificateur interne.
Quand on quantifies sur des sumka'i représentant plusieurs objets, il faut se rappeler que se sont généralement des masses. Par définition "{nombre} {sumti}" est "{nombre} da poi ke'a me {sumti}". Vous ne serez familier avec da que dans quelques leçons. Pour l'instant il suffit d'admettre que dans ce contexte, da siginifie "quelque chose". Donc ci mi signifie "Trois de ceux qui font partie de "nous"". Quand on quantifies sur de telles masses, on a peu de chance de se tromper en supposant que me traduit la relation " être membre d'une masse", et donc ci mi c'est "trois d'entre nous".
Quelques utilisations importantes de la quantification oblige à quantifier des selbri ou des objets dont la quantité est inconnu. Pour ce faire on a les "variables quantifiées logiquement" que nous verrons avec leur mode d'emploi dans la leçon vingt-sept.
Pour finir nous allons quantifier les indénombrables. Comment faire pour quantifier des substances comme l'eau ou le sucre ? Une solution est d'utiliser des nombres imprécis. C'est une méthode floue nom seulement parce que les nombres utilisés sont flous mais aussi parce que l'échelle de mesure n'est pas précisée. On peut considérer du sucre comme un ensemble de cristaux, dénombrés un par un, on peut quantifier l'eau comme la quantité de goutte d'eau qu'il faut pour remplir la masse d'eau considérée. Bien que cette façon de faire soit correcte, elle est très imprécise et peut provoquer beaucoup de confusions. Une façon d'être explicite à propose de l'indénombrabilité est d'utiliser l'opérateur tu'o comme quantificateur interne.
- tu'o = Opérateur nul ( Ø ). Utilisé comme relation unaire.
Cette solution est élégante et intuitive et permet surtout de ressortir un exemple glauque, donc amusant de la proposition xorlo originale :
le nanmu cu se snuti .i ja'e bo lo tu'o gerku cu kuspe le klaji
- snuti = x1 est un accident de la part de x2
- ja'e = sultcita: BAI: (de jalge: Bridi cause {sumti}
- kuspe = x1 comble x2
- klaji = x1 est une rue à x2 menant à x3
Alors qu'est-ce que ça veut dire ?
Réponse: "L'homme a eu un accident, en conséquence il y avait du chien sur toute la rue"
Une autre méthode pour quantifier les substances est d'utiliser les temps ve'i, ve'a et ve'u que nous avons mentionnés dans la leçon dix:
ti ve'i djacu - C'est une petite quantité d'eau
- djacu = x1 est de l'eau
Enfin, vous pouvez évidemment utiliser un brivla pour donner une mesure exacte :
le ta djacu cu ki'ogra be li re pi ki'o ki'o - " Cette eau a une masse de deux millions de kilos"
- ki'ogra = x1 a une masse de x2 kilogrammes selon le standard x3
Leçons de lojban - Leçon vingt-trois (négation)
Parfois, juste dire ce qu'est la vérité n'est pas suffisant. Souvent, nous voulons préciser ce qui n'est pas vrai, et nous le faisons en utilisant la négation.
La plupart du temps, la négation en français implique « ne...pas » ou « non » et elle peut être ambiguë. En tant que lojbanistes, nous ne pouvons évidemment pas permettre cela, le lojban contient donc un système de négation élégant et sans ambiguïté. Ce qui sera présenté ici, ce sont les règles d'or du standard officiel. La désapprobation de ces « règles d'or » concernant na grandit, et il y a désaccord sur l'ensemble de règle qui devrait le remplacer. Pour le moment, je m'en tiendrai aux règles officielles et, par conséquent, vous aussi, cher lecteur.
La première chose que vous avez besoin de connaître c'est la négation de bridi, appelée ainsi parce qu'elle réfute le bridi dans lequel elle se trouve, disant qu'il n'est pas vrai. La façon de réfuter un bridi est de mettre un na suivi d'un ku au début de la phrase, ou seul devant le selbri.
- speni = x1 est marié à x2 selon les conventions x3
Donc : naku le mi speni cu ninmu déclare que « Mon conjoint n'est pas une femme ». Cela ne dit rien sur ce qu'est mon conjoint ou même si je suis marié ou non. Cela indique seulement que je n'ai pas un conjoint qui est aussi une femme. Cela a une conséquence importante : si la négation d'un bridi est fausse, alors le bridi doit être vrai : na ku le mi speni cu na ninmu doit signifier que j'ai une épouse et qu'elle est une femme.
Il est possible d'utiliser la négation de bridi dans tous les bridi, même les bridi implicites des sumti descriptifs. lo na prenu peut faire référence à n'importe quoi de non-humain, que ce soit un sphinx, un match de foot ou la propriété d'être approprié.
- bau = sumtcita, de bangu : utilisant le langage de {sumti}
- se ja'e = sumtcita, de se jalge : à cause de {sumti}
Souvent, lorsque l'on utilise na, c'est un problème que cela rende négatif le bridi complet. Si je dis mi na sutra tavla bau le glibau se ja'e le nu mi dotco, je finis par nier trop à la fois, et ce n'est pas clair que je veux seulement nier le fait que je parle vite. La proposition peut suggéré qu'en fait je parle vite, pour une autre raison, par exemple, que je parle vite en français parce que je suis allemand. Pour exprimer la proposition plus précisément, je dois ne nier que le fait que je parle vite, et rien d'autre.
Pour ne nier qu'une partie d'un bridi, "na ku" peut être déplacé dans le bridi et placé à n'importe quel endroit où un sumti peut aller. Cela rend alors négatif n'importe quel sumti, selbri et sumtcita placé après lui. Lorsqu'il est placé immédiatement avant le selbri, le ku peut être élidé.
Déplacer na ku de l'extrémité gauche du bridi vers la droite affecte chaque quantificateur d'une certaine façon, comme on peut le voir dans cet exemple :
Il y a des forces au sein la communauté lojban, qui pensent, peut-être à juste titre, qu'il n'y a pas de bonne raison pour qu'un na placé avant un selbri donne un sens négatif au bridi complet, tandis qu'un na ku à n'importe quelle autre place donne un sens négatif seulement à ce qui se trouve placé après lui. Pour autant, dans ces leçons, on vous apprendra ce qui est toujours la position officielle, à savoir que na placé avant un selbri rend le bridi négatif.
L'utilisation de na ku est illustrée avec les exemples suivants.
na ku ro remna cu verba = « Il n'est pas vrai que tous les humains sont des enfants. »
su'o remna na ku cu verba = « Pour au moins un humain, il n'est pas vrai que : c'est un enfant. » Voyez que na ku est placé avant cu, puisqu'un sumti peut seulement être placé devant, et non derrière cu. Si je n'avais utilisé que na, il serait allé après cu - mais cela aurait nié tout le bridi, signifiant " Ce n'est pas vrai que : Au moins un humain est un enfant ".
Quand na ku est déplacé vers la droite, tous les quantificateurs sont inversés - c'est-à-dire : ro est transformé en su'o. Ceci seulement si le sens du bridi doit être préservé, bien sûr. Cela signifie que quand na ku est placé à la fin du bridi, seul le selbri est nié, mais tous les sumti et sumtcita sont préservés comme on peut le voir avec ces trois bridi identiques :
- ckule = x1 est une école à l'endroit x2 enseignant x3 aux étudiants x4 et dirigée par x5
na ku ro verba cu ve ckule fo su'o ckule - « Ce n'est pas vrai que tous les enfants sont étudiants dans une école. »
su'o verba cu ve ckule na ku fo su'o ckule - « Certains enfants ne sont étudiants dans pas une seule école. »
su'o verba cu ve ckule fo ro ckule na ku - « Certain enfants, sont pour toutes les écoles non étudiant dans cette école. »
L'opposé de na est ja'a. Il n'est presque jamais utilisé, puisqu'il est par défaut dans la plupart des bridi. Une exception concerne les bridi répétés (prochaine leçon). Il est parfois utilisé pour insister sur la véracité du bridi comme dans la .bab. ja'a melbi = « Bob est vraiment beau. ».
Alors que le mécanisme de na ku ressemble à la négation des langues naturelles, il peut être difficile de garder trace précisément de ce qui est nié, et de comment cela affecte le bridi. Pour cette raison, la construction na ku est rarement vue ailleurs qu'au début d'un bridi. Dans la plupart des cas où une négation plus précise est nécessaire, les gens recours à une autre méthode. Cette méthode, appelée négation scalaire, est un outil élégant et intuitif. En l'utilisant, vous n'affectez que le selbri, puisque les mots utilisés par la négation scalaire sont liés au selbri essentiellement comme le mot se.
Le nom " négation scalaire " vient du fait que les mots qui sont liés au selbri peuvent être placé sur une échelle allant de l'affirmation en passant par la négation et jusqu'à déclarer que l'opposé est vrai :
| Mot | Signification |
|---|---|
| je'a | « En effet » ; affirmateur scalaire |
| no'e | « Pas vraiment» , milieu de l'échelle |
| na'e | « Non- » , négateur scalaire |
| to'e | « anti- » , « a- » , « in-/im- » , etc, opposition scalaire |
Ces mots sont des négateurs dans le même sens que na. Ils ne déclare pas qu'un bridi est faux, mais affirme qu'un bridi est vrai - le même bridi, mais avec un selbri différent. Cette distinction est tout de même essentiellement académique. Si par exemple, je déclare que mi na'e se nelci « Je ne suis pas apprécié » , je déclare en fait qu'un selbri s'applique à moi, et qu'il est sur une échelle pertinente avec le selbri nelci. La plupart du temps, on suppose que les positions sur l'échelle sont mutuellement exclusives (comme amour-appréciation-aversion-haine), donc mi na'e se nelci implique mi na se nelci
C'est pourquoi les mots no'e et to'e ne doivent être utilisés que quand le selbri a une place sur une échelle évidente :
le mi speni cu to'e melbi - « Mon époux est laid » a du sens parce qu'on comprend immédiatement ce qu'est l'opposé de beau, alors que
mi klama le mi to'e zdani - « Je vais à ma chose opposée de maison » , bien que grammaticalement correct, laisse le récepteur deviner ce que « l'anti-maison » du locuteur peut être, et doit être éviter.
Alors comment pouvez-vous nier le selbri sans impliquer que le selbri est correct à une autre position sur une échelle de vérité ? Facile : En déplaçant le na ku à l'extrémité droite du bridi, comme montré quelques lignes plus haut. Cette propriété est très utile. Certain lojbanistes préfèrent préfixer le rafsi nar (le rafsi de na) devant le selbri - ce qui a le même effet, mais je le déconseille, parce que cela rend des brivla familiers étranges, et parce que c'est plus difficile à comprendre dans une discussion informelle.
S'il se présente une situation dans laquelle vous avez besoin de ne nier que le selbri, mais que vous voulez que ce soit clair avant la fin du bridi, vous pouvez utiliser le cmavo expérimental na'ei, qui fonctionne grammaticalement comme na'e.
- na'ei =
- Nie le bridi suivant seulement
Essayez de traduire ces propositions :
« Mon conjoint n'est pas une femme. » (signifiant que c'est un mâle)
Réponse : le mi speni cu na'e/to'e ninmu. Utiliser la négation scalaire ici implique qu'il existe, ce que na ne fait pas.
« Mon conjoint n'est pas vraiment une femme. »
Réponse : le mi speni su no'e ninmu. L'échelle ici est supposée aller de femme à homme.
« Je ne parle pas vite en anglais parce que je suis allemand. »
mi na'e sutra tavla bau le glibau se ja'e le nu mi dotco
A propos, remarquez que chaque fois que ces mots sont utilisés avec un tanru, ils n'affectent que le selbri le plus à gauche. Pour le lier à tout ou partie du tanru, les mots de groupement de tanru habituels peuvent être utilisés.
Essayez de dire « Je vends quelque chose qui n'est pas des maisons jaunes » en utilisant le tanru pelxu zdani vecnu.
Réponse : mi na'e ke pelxu zdani ke'e vecnu ou mi na'e pelxu bo zdani vecnu
Quand on essaye de répondre à « Le roi des États-Unis est-il gros ? » , toutes ces négations échouent. Bien qu'il soit techniquement correct de nier cela avec na, puisque ça ne suppose aucune vérité dans la proposition, c'est légèrement trompeur, puisque cela peut amener le récepteur à croire qu'il y a un roi des États-Unis. Pour ces scénarios, il y a un négateur métalinguistique : na'i.
- na'i = Négateur métalinguistique. Quelque chose ne va pas avec l'assignation d'une valeur de vérité au bridi.
Comme na'i peut être nécessaire tout à fait n'importe où, on lui a donné la grammaire des attitudinaux, ce qui signifie qu'il peut apparaître n'importe où, et qu'il s'attache au mot ou à la construction précédente.
- palci = x1 est maléfique selon le standard x2
le na'i pu te zukte be le skami cu palci - « Le but poursuivi {erreur ! } par l'ordinateur était maléfique » , proteste probablement contre l'idée que les ordinateurs puissent poursuivre volontairement un objectif.
Comme c'est une leçon sur la négation, je crois que le mot nai mérite une courte mention. Il est utilisé pour nier des constructions grammaticales mineures, et peut être combiné avec les attitudinaux, tous les sumtcita, y compris les temps, les vocatifs et les connecteurs logiques. Les règles de négations concernant nai dépendent de la construction, et l'effet de nai a donc été discuté au moment de présenter les constructions elles-mêmes. Les sumtcita font exception, les règles de leur négation étant plus complexes, elles ne seront pas discutées ici.
Remarque : Au moment d'écrire ces lignes, il a été proposé de déplacer nai dans le selma'o CAI, ce qui signifierait que la sémantique de nai dépendrait du selma'o qu'il suit.
Leçons de lojban - Leçon vingt-quatre (brika'i, pro-bridi et ko'a)
Si je dis que je m'appelle Mikhail, la . mikail. cmene mi, et que vous devez dire exactement le même bridi, quel sera-t-il ? Une des nombreuses réponses est do se cmene zo.mikail.. Pour que le bidri soit le même, vous devez remplacer mi par do, et lequel d'entre vous dit le bridi n'a pas d'importance, que se soit avec le selbri transformé par se ou non. C'est parce qu'un bridi ce n'est pas les mots qui l'expriment - un bridi est une idée, une proposition abstraite. Le mot mi quand je le dis et le mot do quand tu le dis, se réfère au même sumti, les deux bridi sont donc identiques.
Cette leçon est sur les brika'i, l'équivalent pour les bridi des sumka'i. Ce sont des mots qui représentent un bridi entier. Ici, il est important de se rappeler qu'un bridi ne se compose que de sumti et des choses qui contiennent les sumti, selbri et sumtcita. Ni les attitudinaux, ni la sémantique portée par ko ou ma ne font parti du bridi en lui-même, et ils ne sont donc pas représentés par un brika'i.
Il y a beaucoup moins de brika'i que de sumka'i. Nous allons commencer par passer en revue les mots des classes les plus utilisées, appelées GOhA :
| Mot | Définition |
|---|---|
| go'u | Répète un bridi passé éloigné |
| go'a | Répète un bridi passé |
| go'e | Répète l'avant dernier bridi |
| go'i | Répète le dernier bridi mentionné |
| go'o | Répète un bridi futur |
| nei | Répète le bridi en cours |
| no'a | Répète un bridi externe |
Queques uns des brika'i de la classe GOhA. Remarquez le motif familier i, a, u pour proche dans le passé, moyennement éloigné dans le passé et loin dans le passé.
Ils ressemblent beaucoup aux sumka'i ri, ra et ru. Ils ne peuvent faire référence qu'au bridi principal d'une jufra, et pas à ceux contenus dans une proposition relative ou dans un sumti descriptif. Le bridi principal peut bien sûr contenir une proposition relative, mais un brika'i ne peut jamais être utilisé pour faire référence à la seule proposition relative.
Un membre de GOhA agit grammaticalement presque comme un selbri, toute construction qui peut être appliquée à un selbri peut aussi lui être appliquée. La structure de position d'un membre de GOhA est la même que celle du bridi qu'il représente, et par défaut, les sumti sont les mêmes que dans le bridi représenté. Remplir explicitement les emplacements de sumti d'un GOhA, remplace les sumti du bridi qu'il représente. Distinguez :
A : mi citka lo plise B : go'i - « Je mange une pomme. » «En effet » de
A : mi citka lo plise B : mi go'i - « Je mange une pomme. » « Moi aussi. »
Ces brika'i sont très utiles pour répondre aux question avec xu :
A : xu do nelci le mi speni B : go'i / na go'i - « Est-ce que tu apprécies ma femme ? » « Oui. /Non. ». Le xu étant un attitudinal, il n'est pas copié.
Quand on répète un bridi nié par na, c'est-à-dire : un bridi dans lequel na est placé dans le prénex (leçon vingt-sept), au début du bridi ou juste avant le selbri, les règles pour recopier na différent de ce à quoi on peut s'attendre. Chaque na est recopié, mais n'importe quel na additionnel dans le brika'i remplace le premier na. Laissez-moi vous montrer sur un exemple :
A : mi na citka lo plise
B : mi go'i = mi na citka lo plise
C : mi na go'i = mi na citka lo plise
D : mi na na go'i = mi citka lo plise = mi ja'a go'i
nei et no'a ne sont pas très utilisés, sauf pour créer des casse-têtes, c'est-à-dire des bridi dont l'analyse syntaxique est difficile, comme dei na se du'u le no'a la'e le nei. Néanmoins, comme nei répète le bridi externe en cours, le nei peut être utilisé pour faire référence au x1 de ce bridi, le se nei au x2 etc.
Quand on utilise les brika'i, on devrait toujours être méfiant en recopiant des phrases avec des sumka'i personnels comme mi, do, ma'a etc, et faire attention à ne pas les répétés quand ils sont dans un mauvais contexte, comme on l'a vu dans les deux exemples ci-dessus avec des pommes. Plutôt que de les remplacer un à un, le mot ro'a placé n'importe où dans le bridi met à jour les sumka'i personnel de façon à ce qu'il s'appliquent du point de vue du locuteur :
A : mi do prami B: mi do go'i est équivalent à A : mi do prami B : go'i ra'o
- ra'o = Met à jour tous les sumka'i personnel de sorte qu'ils s'adaptent désormais au point de vue du locuteur.
Les seules autres séries de brika'i sont très faciles à retenir:
| broda | variable de bridi 1 |
| brode | variable de bridi 2 |
| brodi | variable de bridi 3 |
| brodo | variable de bridi 4 |
| brodu | variable de bridi 5 |
Et pour les attribuer :
- cei = défini une variable de bridi (pas un brika'i, et pas dans BRODA)
Les cinq premiers sont seulement cinq instances du même mot. Ils peuvent être utilisés comme raccourcis d'un bridi. Après avoir dit un bridi, dire cei broda définie ce bridi comme étant broda, et broda peut alors être utilisé comme un brika'i pour ce bridi dans la suite de la conversation.
Tant que nous y sommes, il y a une séries semblable de sumka'i qui n'a probablement pas sa place dans cette série, mais les voilà quand même :
| ko'a | variable de sumti 1 | fo'a | variable de sumti 6 | |
| ko'e | variable de sumti 2 | fo'e | variable de sumti 7 | |
| ko'i | variable de sumti 3 | fo'i | variable de sumti 8 | |
| ko'o | variable de sumti 4 | fo'o | variable de sumti 9 | |
| ko'u | variable de sumti 5 | fo'u | variable de sumti 10 | |
de même que l'équivalent de cei pour cette série :
- goi = Définie une variable de sumti
Ils s'utilisent comme la série de brika'i. Placez simplement goi ko'u, par exemple, derrière un sumti, et ce sumti peut être représenté par ko'u.
Bizarrement ces séries sont rarement utilisées dans leur but original. Elles sont plutôt utilisées comme des selbri et des sumti arbitraires dans les textes d'exemple, où broda et brode signifient " n'importe quel selbri A " et " n'importe quel selbri B " et de même pour ko'a et ses amis.
« Alors est-il vrai que les conditions de vérité de ko'a ko'e broda naku sont toujours les mêmes que pour na ku ko'a ko'e broda ? » « Eh nan, c'est pas vrai. »
Leçons de lojban - Leçon vingt-cinq (connecteurs logiques)
Si vous demandez à une lojbaniste: « Voulez-vous du lait ou du sucre dans votre café? » elle répondra: « Exact ».
Aussi spirituelle que cette plaisanterie puisse être, elle illustre une propriété incongrue de la façon française de poser cette question. Elle est formulée comme une question vraie ou fausse, alors qu'en en réalité ce n'en est pas une. En lojban, nous ne permettons pas cette sorte d’incohérence, et il nous faut donc trouver une autre façon de poser ce type de question. Si vous y réfléchissez, il est assez difficile de trouver une méthode à la fois simple et bonne, et il semble que le lojban a choisi une bonne méthode plutôt qu'une méthode facile.
Pour l'expliquer, prenons deux bridi distinctes: bridi 1: « J'aime le lait dans mon café » et bridi 2: « J'aime le sucre dans mon café ». Ces deux bridi peuvent avoir un état vrai ou faux. Cela produit quatre combinaisons de quels bridi sont vrais:
A ) 1 et 2 B ) 1 mais pas 2
C ) 2 mais pas 1 D ) ni 1, ni 2
En réalité, j'aime le lait dans mon café, et je suis indifférent à ce qu'il y ait du sucre ou non. Donc, ma préférence peut être écrite A ) Vrai B ) Vrai C ) Faux D ) Faux, dès lors que A et B sont tous deux vrais pour moi, mais que ni C ni D ne le sont. Une façon plus compacte d'écrire mes préférences en matière de café serait VVFF pour Vrai ,Vrai, Faux, Faux. De manière similaire, une personne aimant son café noir et sans sucre aurait une préférence concernant le café décrite par FFFV. Cette combinaison de « Vrai » et de « Faux » est appelé une « fonction de vérité », dans le cas présent pour les deux propositions « j'aime le lait dans mon café » et « j'aime le sucre dans mon café ». Notez que l'ordre des propositions est important.
En lobjan, nous fonctionnons avec 4 fonctions vérité, que nous considérons comme fondamentales:
A: VVVF (et/ou)
O: VFFV (si et seulement si).
U : VVFF (quelque soit)
E: VFFF (et)
Dans cet exemple, elles signifieraient quelque chose comme :
A: « Tout sauf du café noir »
O: « Soit du lait et du sucre, sinon rien pour moi, s'il vous plaît »
U: « Du lait, et peu importe s'il y a du sucre ou non »
E: « Du lait et du sucre, s'il vous plaît »
En lojban, vous placez le mot correspondant à la fonction de vérité liant les deux bridi, selbri ou sumti en question. Ce mot est appelé connecteur logique. Les mots correspondants aux fonctions de vérité liant les sumti (et seulement les sumti) sont .a.o.u et .e. Facile ! Par exemple : « Je suis ami avec un Américain et un Allemand » serait lo merko .e lo docto cu pendo mi.
Comment direz vous : « Je vous parle et à personne d'autres ? »
Réponse : mi tavla do .e no drata. Remarquez que cela affirme qu'en effet « je vous parle ».
Un autre : « J'aime le fromage que j'aime ou non le café »
- ckafi = x1 est une quantité/contient du café de la source/du grain x2
Réponse : mi nelci lo'e cirla .u lo'e ckafi
Vous pouvez sans doute déduire qu'il y a seize fonctions de vérité possibles, et qu'il nous en reste donc douze à apprendre avant de toutes les connaître. Huit de plus peuvent être obtenues par la négation, soit de la première, soit de la deuxième phrase. La première est niée en préfixant la fonction de vérité avec na, la seconde est niée en plaçant nai après le mot. Par exemple, puisque .e représente TFFF, .e nai doit être « à la fois 1 est vrai et 2 est faux », c'est-à-dire FTFF. Pareillement, na.a est « Tout sauf : 1 est vrai et 2 est faux », c'est-à-dire TTFT. Opérer ce type de conversion de tête en temps réel est très, très dur, aussi peut-être faudrait-il se concentrer sur l'apprentissage du fonctionnement général des connecteurs logiques, et ensuite apprendre par cœur les connecteurs logiques eux-mêmes.
Quatre fonctions ne peuvent pas être faites de cette façon: TTTT, TFTF, FTFT et FFFF. La première et la dernière ne peuvent pas être faites en utilisant uniquement les connecteurs logiques, mais ils sont de toutes façons plutôt inutiles. Utiliser un connecteur logique hypothétique dans la phrase "j'aime le lait FFFF sucre dans mon café" est équivalent à dire "je n'aime pas le café", juste en plus compliqué. Les deux dernières TFTF et FTFT, peuvent être obtenues en préfixant .u avec le bon vieux se ,qui inverse juste les deux propositions. se .u, par exemple est "B quel que soit A", c'est-à-dire TFTF. On peut voir ci-dessous la liste finale de tous ces connecteurs logiques.
TTTT: Ne peut être faite
TTTF: .a
TTFT: .a nai
TTFF: .u OU .u nai
TFTT: na .a
TFTF: se .u
TFFT: .o OU na .o nai
TFFF: .e
FTTT: na .a nai
FTTF: na .o OU .o nai
FTFT: se .u nai
FTFF: .e nai
FFTT: na .u OU na .u nai
FFTF: na .e
FFFT: na .e nai
FFFF: ne peut être faite
Logiquement, dire une phrase avec un connecteur logique, comme par exemple mi nelci lo'e cirla .e nai lo'e ckafi est équivalent à dire deux bridi, qui sont connectés par le même connecteur logique: mi nelci lo'e cirla .i {E NAI} mi nelci lo'e ckafi. C'est ainsi que la fonction des connecteurs logiques est définie. Nous arriverons à la façon d'appliquer des connecteurs logiques aux bridi dans un instant.
En mettant un « j » devant le mot principal d'un connecteur logique cela connecte deux selbri. Par exemple mi ninmu na jo manmu « je suis un homme ou une femme , mais pas les deux à la fois. »
- ninmu = x1 est une femme
C'est à l'intérieur d'un tanru, cela veut dire qu'il relie faiblement des selbri ensemble, même quand ils forment un tanru: lo dotco ja merko prenu signifie « un homme allemand ou américain » , et il s'analyse en lo (dotco ja merko) prenu. Cette liaison est légèrement plus forte que le groupement de tanru normal (mais plus faible que les mots de groupement spécifiques), de sorte que, lo dotco ja merko ninmu ja nanmu s'analyse en lo (dotco ja merko) (ninmu ja nanmu). Les connecteurs logiques de selbri peuvent aussi être attachés à .i pour connecter ensemble deux phrases: la .kim. cmene mi .i ju mi nanmu « je m'appelle Kim, que je sois ou non un homme ». La combinaison .i je indique que les deux phrases sont vraies à la fois, semblablement à ce que nous supposerions s'il n'y avait aucun connecteur logique.
Question trop difficile : En utilisant des connecteurs logiques, comment traduiriez-vous « Si vous vous appelez Bob, vous êtes un homme. » ?
Réponse : zo .bab. cmene do .i na ja do nanmu soit « Soit vous ne vous appelez pas Bob et vous êtes un homme, ou bien vous ne vous appelez pas Bob et vous n'êtes pas un homme, ou alors vous vous appelez Bob et vous êtes un homme. Mais vous ne pouvez pas vous appelez Bob et ne pas être un homme. » La seule combinaison interdite est « Vous vous appelez Bob, mais vous n'êtes pas un homme. » Ceci veut dire que s'il est vrai que vous vous appelez Bob, vous devez être un homme.
Si nous essayons de traduire le très triste événement « j'ai pleuré et j'ai donné mon chien », nous nous heurtons à un problème.
Essayer de dire la phrase avec un je entre les selbri « donné » et « pleuré », voudrait littéralement dire la même chose mot à mot , mais malheureusement cela signifierait que « j'ai pleuré le chien et j'ai donné le chien », cf. la définition des connecteurs logiques. On peut pleurer des larmes ou encore du sang, mais pleurer des chiens est tout bonnement absurde.
Cependant, nous pouvons biaiser en utilisant les connecteurs logiques des queues de bridi. Ils font que chaque sumti ou sumtcita précédent est attaché aux deux selbri liés par le connecteur logique de queue de bridi, mais tous les sumti ou sumtcita suivants ne s'appliquent qu'au dernier mentionné : le bridi se divise d'une tête en deux queues, pour parler métaphoriquement.
La forme d'un connecteur logique de queue de bridi est gi'V, avec le V pour la voyelle de la fonction de vérité.
Comment pouvez-vous traduire correctement la phrase anglaise en lojban ?
Réponse: mi pu klaku gi'e dunda le mi gerku
Que signifie ro remna cu palci gi'o zukte lo palci ?
- palci = x1 est mauvais selon le standard x2
Réponse : « Les gens sont mauvais, si et seulement si, ils font de mauvaises choses ».
En outre, il y a un groupe de connecteurs pour tout sauf l'intérieur des tanru, obtenu en préfixant "g" devant la voyelle de la fonction de vérité, agissant par préméditation. « Préméditation » dans ce contexte signifie qu'ils doivent aller devant les choses qu'ils connectent, et que par conséquent vous devez penser à la structure grammaticale de la phrase avant de la prononcer. Tout sauf à l'intérieur des tanru signifie qu'il sert de connecteur à la fois entre sumti, bridi, selbri et queue de bridi, mais pas entre deux selbri du même tanru. Laissez moi vous montrer comment ça marche en réécrivant la phrase ci-dessus :
go lo remna cu palci gi lo remna cu zukte lo palci
Le premier connecteur logique, dans les constructions de ce genre, porte la voyelle qui indique quelle fonction de vérité est utilisée. Le second connecteur logique est toujours gi, et comme .i, il n'a pas de fonction de vérité. Il sert simplement à séparer les deux termes étant connectés. Si vous voulez nier la première ou la deuxième phrase, un nai est suffixé soit au premier connecteur logique (pour la première phrase) soit au second (pour la seconde phrase).
Pourvu que les constructions soient terminées proprement, c'est d'une remarquable flexibilité, ainsi que les quelques exemples suivants le démontrent.
mi go klama gi cadzu vau le mi zdani « je vais, si et seulement si je marche, chez moi » ou « je ne peux aller chez moi qu'en marchant ». Notez que le vau est nécessaire pour que mi zdani s'applique à la fois à cadzu et à klama.
se gu do gi nai bajra le do ckule « quoi que tu fasses, alors pas moi, se dirige vers ton école » ou « je ne vais pas vers ton école, que tu le fasses ou non ».
L'équivalent de gV pour l'intérieur des tanru est gu'V. Ce sont exactement les mêmes, sauf qu'ils sont exclusivement réservés à l'intérieur des tanru et qu'ils lient un selbri à un gi plus étroitement qu'un groupement de tanru normal, mais plus faiblement qu'un lien de sumti explicite :
la xanz.krt. gu'e merko gi dotco nanmu est équivalent à la xanz.krt. merko je dotco nanmu
Et donc vous avez lu la page de haut en bas juste pour acquérir le savoir nécessaire pour être capable de demander « désirez vous du lait ou du sucre de votre café ? » en lojban. Placez simplement un questionneur de connecteurs logiques à la place d'un autre connecteur logique, et comme ma, il demande au récepteur de compléter par une réponse correcte. Malheureusement, ces questionneurs de connecteurs logiques ne correspondent pas toujours au modèle morphologique des connecteurs logiques qu'ils demandent :
- ji = questionneur de connecteurs logiques : demande un connecteur logique de sumti (A)
- je'i = questionneur de connecteurs logiques: demande un connecteur logique d'intérieur de tanru (JA)
- gi'i = questionneur de connecteur logique : demande un connecteur logique de queue de bridi (GIhA)
- ge'i = questionneur de connecteurs logiques : demande un connecteur logique prémédité s'appliquant à tout sauf à l'intérieur des tanru (GA)
- gu'i = questionneur de connecteurs logiques : demande un connecteur logique prémédité de tanru interne (GUhA)
Donc... comment demanderiez-vous si les quelqu'un veut du lait ou du sucre dans son café ?
- ladru = x1 est/contient du lait de la source x2
- sakta = x1 est/contient du sucre de la source x2, de composition x3
Réponse possible: sakta je'i ladru le do ckafi même si je suppose que quelque chose de plus français et de moins élégant pourrait suffire, comme do djica lenu lo sakta ji lo ladru cu nenri le do ckafi.
Leçons de lojban - Leçon vingt-six (connecteurs non-logiques)
Le mot « logique » dans « connecteur logique » réfère au lien qu'a un connecteur logique avec une fonction de vérité. Néanmoins, tous les connecteurs utiles ne peuvent pas être définis à travers une fonction de vérité, il y a donc encore d'autres connecteurs à côté de ceux qui sont logiques.
Le sens d 'un connecteur logique est défini comme étant le même que celui de deux bridi différents connectés avec ce connecteur logique. Par exemple, mi nitcu do .a la .djan. est défini comme étant équivalent à mi nitcu do .i ja mi nitcu la .djan.. Il est utile de se souvenir de cette définition car elle implique que, parfois le sumti ne peut pas être connecté avec un connecteur logique sans changer de sens. Examinons la phrase « Jack et Joe écrivaient cette pièce. » Une tentative de traduction serait : ti draci fi la .djak. e la .djous.
- draci = x1 est un drame/pièce x2 par un auteur/dramaturge x3 pour un public x4 avec les acteurs x5
Le problème avec cette traduction est qu'elle signifie ti draci la .djak. ije ti draci la .djous., ce qui n'est pas tout à fait vrai. Ni Jack ni Joe n'a écrit cette pièce, ils l'ont écrite ensemble. Ce que nous voulons ici c'est bien sûr une masse, et une façon de regrouper Jack et Joe dans une masse. Ceci n'a pas grand chose à voir avec une fonction de vérité nous devons donc utiliser un connecteur non-logique, qui fait partie de la selma'o JOI. Nous reviendrons à ce problème de « Jack et Joe » dans un instant - mais d'abord: quatre des JOI connus:
| Les connecteurs lojbans : | ce | ce'o | joi | jo'u |
| Regroupe les sumti et forme un(e) : | ensemble | séquence | masse | groupe d'individus |
Les fonctions de ces mots sont simples: lo'i remna jo'u lo'i gerku considère à la fois l'ensemble des humains et l'ensemble des chiens distributivement (en tant qu'individus). Rappelez vous que dans la leçon 22 (les quantitatifs) « distributivité » signifiait que ce qui est vrai pour le groupe l'est aussi pour chacun des individus. De la même façon, loi ro gismu ce'o loi ro lujvo ce'o loi ro fu'ivla est une séquence constituée de la masse de tous les gismu, suivi de la masse de tous les lujvo, suivi de la masse de tous les fu'ivla.
Comme avec tout les membres de JOI qui ont un ordre inhérent, se peut être placé avant ce'o pour inverser l'ordre : A ce'o B est identique à B se ce'o A.
Comment pouvez vous traduire correctement « Jack et Joe ont écrit cette pièce » ?
Réponse: ti draci fi la .djak. joi la .djous.
Les cmavo de JOI sont très flexibles : ils peuvent agir aussi bien comme connecteurs de sumti que comme connecteurs à l'intérieur d'un tanru, ils peuvent donc être utilisés pour connecter des sumti, des selbri et des bridi. Cette souplesse implique que l'on doit faire attention à utiliser correctement les famyma'o lorsqu'on utilise un JOI.
Qu'est-ce qui ne vas pas dans le bridi lo dotco jo'u mi cu klama la dotco gugde ?
Réponse: jo'u est placé après un selbri, donc il nécessite un selbri après lui pour effectuer la connexion, mais il n'y en a pas. Si un ku avait été placé devant le connecteur, ç'aurait été correct.
Si plusieurs JOI sont utilisés, bo et/ou ke peuvent être utilisés pour ignorer le groupement à gauche habituel :
| mi joi do ce'o la .djak. joi bo la .djous. cu po'o ci'erkei damba lei xunre Moi et toi, et ensuite Jack and Joe allons jouer contre les rouges. |
Ne pas confondre avec
| mi joi do ce'o la .djak. joi la .djous. cu pu'o ci'erkei damba lei xunre En premier moi et toi, puis Jack, allons avec Joe, jouer contre les rouges. |
Connecter des bridi avec JOI peut engendrer des insinuations intéressantes sur la relation entre les bridi :
| la .djak. morsi ri'a lo nu ri dzusoi .i joi le jemja'a po ri cu bebna Jack est mort parce qu'il était un fantassin et que son général était un idiot |
implique que les deux bridi agglomérés sont ensemble la cause physique de sa mort: s'il avait été dans un véhicule blindé ou avec un commandant compétent, il aurait pu survivre.
- dzusoi = x1 est un soldat d'infanterie de l'armée x2
- jemja'a = x1 est un général de l'armée x2 avec la fonction x3
- bebna = x1 est absurde/idiot selon la propriété/l' aspect x2
Les connecteurs non logiques peuvent aussi être niés avec nai, indiquant qu'un autre connecteur est approprié :
| lo djacu ce'o nai .e'o lo ladru cu cavyfle fi le mi tcati S'il vous plait ne versez pas l'eau en premier puis le lait sur mon thé. |
Bien sûr, cela ne dit pas quel connecteur est approprié - on pourrait supposer se ce'o (en premier le lait, puis l'eau), pour finalement trouver que .e nai (seulement de l'eau, jamais de lait) était le bon.
- cavyfle = x1, constitué de x2, coule dans x3 venant de x4
De même qu'un connecteur logique est une négation possible d'un connecteur non logique, les réponses à des questions de type ji ou je'i peuvent être aussi bien logiques que non logiques: A: ladru je'i sakta le do ckafi B: se ce'o ( « Du lait ou du sucre dans votre café ? » « D'abord le dernier, ensuite le premier » ). Dans ce cas ce n'aurait aucun sens du tout, puisque le café ne peut pas contenir des ensembles, et joi (les deux mélangés ensemble), voudrait dire la même chose que jo'u (l'un et l'autre) à moins que celui qui répond ne préfère du sucre non mélangé dans son café.
Le cinquième JOI que je présente ici est un peu un original :
- fa'u = connecteur non logique: distribution ordonnée sans mélange (A et B, respectivement)
Quand un fa'u seul est placé à l'intérieur d'un bridi (ou plusieurs bridi connectés ensemble avec des connecteurs), fa'u peut être supposé identique à jo'u. Cependant, quand plusieurs fa'u sont utilisés à l'intérieur d'un bridi, les constructions avant fa'u s'appliquent chacune l'une à l'autre, et les constructions après fa'u s'appliquent chacune l'une à l'autre. Prenons un exemple :
| mi fa'u do rusko fa'u kadno Vous et moi sommes russe et canadien |
implique que mi va avec rusko et que do va avec kadno, et n'implique rien d'autre concernant quelque autre combinaison. Bien sûr, dans cet exemple, se serait bien plus facile de dire mi rusko .i do kadno.
Ces trois derniers JOI connectent deux ensembles pour faire de nouveaux ensembles :
- jo'e = union de A et B
- ku'a = intersection de A et B
- pi'u = produit cartésien de A et B
Ils ne sont probablement pas très utiles pour le lojbaniste moyen, mais je peux aussi bien les mettre ici.
Le premier jo'e, fait un nouvel ensemble avec deux ensembles. Ce nouvel ensemble contient uniquement ceux des membres qui sont dans les deux ensembles.
Un ensemble fait avec ku'a contient tous les membres de l'ensemble A et ceux de l'ensemble B. Si quelque chose est membre des deux ensembles à la fois, ils n'est pas compté deux fois.
pi'u est un petit peu plus compliqué. Un ensemble « A pi'u B » contient toutes les combinaisons possibles de « a ce'o b », dans lequel a est un membre de A et b est un membre de B. Ainsi, c'est un ensemble de séquences de membres. Si, par exemple, l'ensemble A contient les membres p et q, et l'ensemble B les membres f et g, alors A pi'u B sera l'ensemble des quatre membres p ce'o f, p ce'o g, q ce'o f et q ce'o g.
Cette partie conclut le tutoriel pour le lojban ordinaire. Dans la troisième partie, je vais me focaliser sur le lojban avancé - les parties que vous n'avez vraiment pas besoin de connaitre pour parler la langue. Je vous déconseille de commencer à lire la troisième partie avant d'être suffisamment à l'aise avec les informations contenues dans les deux premières parties, pour pouvoir tenir une conversation écrite dans la langue.
Leçons de lojban - Leçon vingt-sept (logique lojban : da, bu'a, zo'u et termes)
Ces aspects du lojban sont en grande part expérimentaux, nouveaux ou complexes, donc vous devriez vous attendre à beaucoup de définitions changeantes, de définitions obsolètes, de désaccords et de malentendus de la part de l'auteur de ce texte. Désolé pour cela.
Le sujet exposé dans cette leçon nécessite quelques justifications: cette leçon ne traite pas vraiment de comment faire de la logique en lojban, puisque premièrement, on peut supposer que la logique est la même dans toutes les langues, et deuxièmement, enseigner effectivement la logique serait tout à fait impossible en une leçon. Au lieu de ça, cette leçon explique certaines constructions qui ressemblent à celles que les logiciens utilisent. Il s'avère qu'elles ont un éventail remarquable d'utilisations en lojban.
Être engagé dans les plus obscurs détails de ces constructions logique peut être difficile au point de tordre les neurones, et il y aura toujours quelque discordances sur les détails de cette section de la langue.
Apprendre ces constructions logiques nécessite d'en apprendre un peu sur des constructions qui ne sont pas logiques par nature. Commençons par zo'u:
- zo'u = sépare le prénex du bridi
Devant chaque zo'u il y a le prénex, le bridi vient après. En gros, un prénex est un emplacement devant le bridi, où l'on place une flopée de termes. Un terme est un mot français donné à certains genres de constructions lojbanes : sumti, sumtcita avec ou sans sumti lié, na ku et une abomination appelée ensemble de termes, que je refuse d'inclure dans ces leçons. Le prénex ne fait pas partie du bridi, mais tout les terme qui s'y trouvent nous donnent des informations concernant le bridi. On peut, par exemple, l'utiliser pour définir un sujet comme suit :
lo pampe'o je nai speni zo'u mi na zanru - « Concernant les amants qui ne sont pas époux : je n'approuve pas ». Les bénéfices de ce genre de structure de phrase sont discutables, mais c'est toujours bon d'avoir quelques variantes sous la main. De plus, cette façon de construire des phrases ressemble de près au mandarin (et à d'autres langues), et pourrait donc sembler plus intuitive pour les locuteurs de cette langue.
- pampe'o = x1 est un amant de x2
- zanru = x1 approuve x2 (plan, évènement ou action)
Bien sûr, la relation entre les termes du prénex et le bridi est vague. On peut imaginer que les sumti du prénex confèrent le même rapport au bridi que s'ils étaient à l'intérieur du bridi après un sumtcita do'e, et que les sumtcita du prénex ont à peu près le même effet que s'ils étaient dans le bridi. Il est tout à fait possible de mettre des termes dans des prénexs sans aucun indice clair sur la façon dont le terme peut être relier au bridi.
le vi gerku zo'u mi to'e nelci lo cidjrpitsa - « Concernant ce chien ici : je n'aime pas la pizza ». Il vous appartient de deviner la raison de mentionner le chien.
- cidjrpitsa = x1 est de la pizza avec la garniture/les ingrédients x2
Si le prénex contient na ku, c'est assez simple: le bridi entier est nié, de même que si le bridi lui-même commence par na ku.
Alors combien de temps dure un prénex ? Il dure jusqu'à ce que le bridi le suivant soit terminé. Si ce n'est pas ce qu'on veut, il y a deux moyens de faire qu'il s'applique à plusieurs bridi : l'un est de mettre quelque sorte de connecteur après le .i séparant les bridi, et l'autre méthode est de simplement mettre tout le texte entre des parenthèses tu'e… tu'u. Ces parenthèses agissent essentiellement en collant tous les bridi ensemble et font s'appliquer toutes sortes de constructions à plusieurs bridi.
Maintenant que nous avons traité de zo'u, les premiers mots "logiques" que nous pouvons utiliser avec lui sont ceux-ci :
- da = sumka'i existentiel logiquement quantifié 1
- de = sumka'i existentiel logiquement quantifié 2
- di = sumka'i existentiel logiquement quantifié 3
Ces mots sont tous les mêmes, comme les variables mathématiques x,y et z. Cependant, une fois que vous les avez définis, ils font toujours référence à la même chose. Ces mots sont définis dans le prénex du bridi, ce qui signifie que quand le prénex cesse de s'appliquer, la définition de ces trois mots est annulée.
Les mots da, de et di peuvent faire référence à absolument n'importe quel sumti, ce qui les rend assez inutiles, si on ne leur applique aucune restriction. La première façon (et la plus répandue) de les restreindre est de les quantifier : on les appelle pas « sumka'i existentiels logiquement quantifiés » sans raisons. Ce sont des sumka'i, ils sont plus utiles quand ils sont quantifiés, et ils sont existentiels. Qu'est-ce que ça veut dire être « existentiel » ? Ça signifie que s'ils sont utilisés, ça implique qu'ils font référence à quelque chose qui existe effectivement. Un exemple :
La déclaration pa da zo'u da gerku a pa da dans le prénex, qui signifie « concernant une chose existante : », et le da ainsi défini est utilisé dans le bridi da gerku. Traduit en français cela signifie : « Il existe une chose, qui est un chien ». C'est évidemment faux, il y en a environ 400 000 000 dans le monde. Si da et ses soeurs ne sont pas quantifiées, le nombre su'o est là par défaut. Ainsi da zo'u da gerku signifie « il existe au moins une chose qui est un chien », ce qui est vrai. Remarquez ici qu'une quantification doit être plus ou moins exacte pour être vrai : bien sûr qu'il existe un chien, mais en lojban, pa da zo'u da gerku signifie non seulement qu'il existe un chien, mais aussi qu'il n'en existe pas plus d'un.
Il y a quelques règles spécifiques à ces sumka'i existentiels :
- Si le quantificateur ro est utilisé devant da, il est fait référence à « tout ce qui existe ».
- Un détail important : l'usage d'un sumka'i existentiel implique seulement qu'une telle chose existe dans le domaine de vérité dans lequel il est utilisé. Ainsi, la phrase so'e verba cu krici lo du'u su'o da crida, n'implique pas da crida, puisque son « domaine de vérité » est limité à l'intérieur de l'abstraction du'u. D'une façon générale, les abstractions contiennent leur propre « domaine de vérité », et donc utiliser da et ses amis à l'intérieur d'une abstraction ne pose habituellement pas de problème.
Si la même variable est quantifiée plusieurs fois, la première quantification est la seule qui demeure : toute quantification postérieure de cette variable ne peut faire référence qu'à des choses qui sont déjà référées par la première instance de cette variable, et toute instance postérieure non quantifiée de cette variable se verra attribuer le premier quantificateur. Pour utiliser un exemple: ci da zo'u re da barda .ije da pelxu signifie « Il existe trois choses telles que deux d'entre elles sont grandes et toutes les trois sont jaunes ». re da, venant après ci da, ne peut faire référence qu'à deux des trois choses déjà exprimées. Quand da figure sans quantificateur, ci est implicite.
- Si il y a plusieurs termes dans le prénex, ces termes sont toujours à lire de gauche à droite. Parfois c'est important : ro da de zo'u da prami de signifie parfois « Concernant toutes les choses X qui existent, concernant au moins une chose Y: X aime Y ». C'est la même chose que « Toutes les choses aiment au moins une chose. » , où la (les) « chose(s) » peuvent être n'importe quoi, y compris la chose elle-même. Notez ici que de peut faire référence à différentes choses pour chaque da – la chose à laquelle fait référence de est dépendante du da, puisqu'il vient avant lui dans le prenex, donc chaque chose pourrait aimer quelque chose de différent. Si nous intervertissons les places de da et de dans le prénex, cela produit un résultat différent : de ro da ze'u da prami de = « Concernant au moins une chose Y, concernant tous les X qui existent : X aime Y », signifiant « Il existe au moins une chose que toute chose aime ».
Bien sûr, les deux affirmations sont complètement fausses. Il y a plein de choses qui n'aiment rien – les pierres ou les concepts abstraits par exemple. De même il est impossible de concevoir quelque chose que toute chose aime, puisque toute chose englobe aussi des choses non-sensibles. Nous avons besoin de meilleurs moyens pour limiter ce que ces variables peuvent indiquer. Un bon moyen de le faire est d'en faire le sujet d'une proposition relative :
ri di poi remna zo'u birka di = « Concernant tout X existant, qui est humain : X a un ou plusieurs bras » ou « Tous les humains ont des bras », ce qui est vrai, au moins quand on parle dans un sens potentiel, intemporel.
- birka = x1 est un bras de x2
Quand nous limitons les déclarations en utilisant cette sorte de variable « existentielle » logique, c'est très important de se souvenir qu'à moins d'avoir un no explicite comme quantificateur, ces sortes de propositions impliquent toujours qu'il existe effectivement quelque chose qui peut être mentionné par da. En conséquence, toute sorte de proposition non négative, dans lesquelles da indique quelque chose qui n'existe pas est fausse, comme dans ce exemple: ro da poi pavyseljirna zo'u da se jirna – « Toutes les licornes ont des cornes ». C'est faux parce que, da étant existentiel, il implique aussi qu'il doit exister au moins une licorne.
Il est intéressant de noter que, quand on utilise une proposition relative, la variable devient limitée dans tous les cas que vous utilisiez poi ou noi. C'est parce que re da noi gerku ne peut toujours faire référence qu'à deux choses qui sont canines. Donc, noi n'a que peu de sens avec da/de/di. Toute proposition est toujours restrictive, à moins d'être vraiment stupide et flagrante comme de noi gerku cu gerku.
En fait, vous n'avez pas vraiment besoin du prénex pour définir les variables. Vous pouvez les utiliser directement comme un sumti dans le bridi, et les quantifier là. Même si vous n'avez besoin de les quantifier que la première fois qu'ils apparaissent. Par conséquent, la phrase sur les humains ayant des bras peut être transformée en birka ro di poi remna. Néanmoins, l'ordre des variables reste important, et le prénex peut donc être utilisé pour éviter de mettre le bazar dans votre bridi en plaçant les variables dans un ordre correct. Quand il y a davantage de variables, un prénex est habituellement une bonne idée.
Le second type de mots logiques fonctionne essentiellement comme les trois mots que nous avons déjà considéré, mais ils est constitué de brika'i au lieu de sumka'i.
- bu'a = brika'i existentiel logiquement quantifié 1
- bu'e = brika'i existentiel logiquement quantifié 2
- bu'i = brika'i existentiel logiquement quantifié 3
Ceux-ci agissent plus ou moins de la même façon que les trois autres, mais ils y a quelques points important à mentionner:
Puisque seuls des termes peuvent aller dans le prénex, ces brika'i nécessitent un quantificateur pour en faire des sumti. Cependant, quand ils sont quantifiés dans le prénex, l'action des quantificateurs est très différente de celle des quantificateurs avec un selbri normal : au lieu de quantifier la quantité de chose qui correspondent au x1 du selbri variable, ils quantifient directement la quantité de selbri qui s'appliquent. Encore une fois, le quantificateur par défaut est su'o. Par conséquent, au lieu de signifier « Concernant deux choses qui sont en relation X » re bu'a zo'u signifie « Concernant deux relations X ».
C'est sûrement bon de voir un exemple de bu'a mis en pratique:
ro da bu'a la .bab. = « Considérant tous les X qui existent : X est dans au moins une relation avec Bob » = « Tout est lié à Bob d'au moins une façon ». Remarquez encore que l'ordre est important : su'o bu'a ro da zo'u da bu'a la .bab. signifie "il y a au moins une relation telle que toute chose qui existe est dans cette relation avec Bob". La première déclaration est vraie – pour n'importe quelle chose, on peut effectivement former un certain selbri qui comprend n'importe quel type appelé Bob et cette chose là. Mais je ne suis pas sûr que la dernière déclaration soit vraie – que l'on puisse former un selbri qui comprenne quoi que ce soit, peu importe ce que c'est et Bob.
Prenons un exemple qui quantifie le selbri:
ci'i bu'e zo'u mi bu'e do – « Concernant une quantité infinie de relations : je suis dans toutes ces relations avec toi » ou « Il existe une infinité de relations entre nous ».
Néanmoins, vous ne pouvez pas quantifier les selbri variables dans le bridi lui-même. Car alors il agirait comme un sumti : mi ci'i bu'a do n'est pas un bridi. Il y a quelques situation où ça deviendra problématique - la leçon vingt-neuf enseignera comment surmonter ces problèmes.
Leçons de lojban - Leçon vingt-huit (types)
Cette leçon ainsi que les trois leçons suivantes porte sur la sémantique – la façon d'interpréter la signification de certaines constructions. Cette leçon traite de la signification de différents types de sumti et deviendra philosophique et un peu brumeuse. Les deux suivantes concernent les abstractions, qui, bien que vous vous soyez déjà familiarisé avec elles il y a vingt deux leçons, vont devenir plus techniques maintenant que je vais essayer d'expliquer leurs propriétés sémantiques et grammaticales.
Enseigner (et apprendre) la sémantique est beaucoup plus épineux qu'enseigner la grammaire, spécialement en lojban, où en grammaire tout est noir ou blanc, alors que la sémantique est moins nette. C'est pourquoi je trouve nécessaire de répéter l'avertissement du début de la troisième partie des leçons wave continuées : la suite n'est pas officielle mais plutôt un point de vue bien informé sur la langue.
La mauvaise grammaire est facile à repérer en lojban - en fait c'est correct ou non sans ambiguïté. Par opposition, dire qu'un jufra est sémantiquement faux revient à dire que le locuteur utilise le lojban pour penser incorrectement le monde. Ce n'est pas dire « vous ne pouvez pas dire X » mais plutôt « vous ne pouvez pas interpréter X de cette façon. Vous devriez l'interpréter de cette façon » . Le fait de poser ces restrictions dans l'utilisation et l'interprétation de la langue est une pente glissante amenant à restreindre la créativité, et même à présupposer certains points de vues métaphysiques tout en en excluant d'autres.
Alors pourquoi inclure des normes sémantiques dans un livre d'apprentissage? Chaque locuteur ne devrait-il pas être libre de dire n'importe quoi, et chaque auditeur être libre d'interpréter cette parole comme signifiant ce qu'il veut?
C'est une question de mesure. En somme, à l'extrême, si aucune norme sémantique n'est donnée, n'importe quoi peut signifier n'importe quoi, et toute communication serait vide de sens. Dans n'importe quelle langue ayant pour but de faciliter la communication, on doit pouvoir s'exprimer de telle sorte qu'on puisse croire que notre message sera interprété de la façon désirée. Les règles de sémantique du lojban n'existent pas pour empêcher les gens de dire A. Elles existent pour empêcher les gens de dire B et que d'autres pensent qu'ils ont voulu dire A.
Cette leçon est sur les types. Le mot type, informellement traduit par klesi, est utilisé par les lojbanistes pour décrire la nature existentielle des choses que les sumti décrivent. Cette nature est, et doit être, la même que la nature des choses décrites par d'autres langues telles que le français. Néanmoins, en lojban, les différentes façons de faire un sumti indiquent de quel type est un sumti, en conséquence, alors que les natures exactes des sumti peuvent être ignorées en français, les lojbanistes doivent les traiter.
Lorsqu'on parle de types, les lojbanistes mentionnent souvent de quel type un sumti est réellement. Quand on commence par le commencement, il faut se souvenir qu'une telle certitude n'est pas philosophiquement bien fondée. D'un point de vue matérialiste, le monde physique fait de particules et d'ondes ne correspond pas tellement à la compréhension humaine de, disons, la haine, qui n'est définie par aucune particule ni par aucune activité cérébrale spécifique. C'est un concept purement abstrait. De façon similaire, dans le cadre d'un point de vue empiriste extrême, tel que celui pris par Hume, tout ce que nous les humains expérimentons sont des impressions subjectives au fil du temps – une longue chaîne d'événements, ou, ainsi que certaines personnes le soutiennent, un tas de qualia (C'est vert. C'est croquant. C'est rond. C'est savoureux. => « C'est une pomme » .) Cependant, ce point de vue ne correspond pas bien à la compréhension humaine de disons, un chat, dont l'existence doit supposément continuer même quand il ne crée aucun qualia chez un humain, dont les qualia varient d'un chat à l'autre, et dont la mort le dépouille sans heurt de ses qualia félins.
En d'autres mots, bien qu'on puisse adopter des visions du monde philosophiquement cohérentes dans lesquelles les objets et les concepts n'existent pas, de telles visions du monde sont inefficace dans la conduite des affaires humaines : dans notre vie, nous avons besoin de faire référence à des objets, et de faire comme s'ils existaient réellement en tant qu'objets. Une histoire célèbre parle d'un philosophe, Samuel Johnson, qui, exaspéré par la justesse philosophique et l'irréfutabilité de l'ingénieux sophisme d'un confrère philosophe selon lequel le monde physique n'existe pas, frappa avec grande force une grosse pierre du pied en hurlant « c'est ainsi que je le réfute » .
En lojban, la plupart des sumti sont construits à partir d'un selbri d'une façon ou d'une autre, ce qui signifie qu'au cœur de la plupart des sumti se trouve un selbri, une action, quelque chose que quelque chose fait. Il n'est pas habituellement fait référence au soleil en tant que la solri, « Le Soleil » , mais souvent lo solri, « quelque chose qui est un soleil » . Cela a beaucoup d'implications philosophiques prêtant à confusion. Comme on l'a déjà dit, c'est pour le moins brumeux, ce que veut dire « chater » (de chat l'animal) et quand quelque chose « commence à chater » ou « arrête chater » . Une langue fictive avec des propriétés semblables est décrite dans une nouvelle élégante. , « Tlön, Uqbar, Orbis Tertius » (où « la lune s'élève au dessus l'océan » est tournée en utilisant des substantifs dérivés de verbes ou d'adverbes : « Vers le haut derrière l'ondulement il luna » . Dans cette nouvelle, la langue est sur le point de mener à l'effondrement de la société car la vision du monde qu'une telle langue implique est inadéquate pour traiter des réalités terrestres.
La leçon importante de tout cela est : des définitions précises des différents types de sumti sont impossibles. Parce que ces catégories ne correspondent pas au monde réel. Nous avons néanmoins besoin de ces catégories quand nous parlons.
Il est possible qu'il y ait une quantité infinie de types, mais je vais passer en revue ceux qu'on utilise le plus souvent en lojban :
Les objets matériels sont peut être les plus faciles à comprendre, quand bien même ils sont difficiles à défendre philosophiquement. Ils ont toujours une place aussi bien dans le temps que dans l'espace, mais ils sont considérés comme étant une constante existant au cours du temps. Le fait est que les objets ne sont pas considérés dans la temporalité: une banane porte avec elle sa bananité invariable tout en vieillissant, jusqu'à ce qu'elle commence à s'effondrer et cesse complètement d'être une banane. Si l'on pouvait figer le temps pour toutes les bananes, elles resteraient des bananes pendant cet arrêt du temps.
Les évènements sont, comme les objets, situés dans le temps et dans l'espace, mais les évènements sont considérés comme se déployant dans le temps : l'aspect temporel est aussi important que l'aspect spatial. Une banane peut être considérée comme un évènement, mais dans ce cas, l'évènement d'être une banane est composé des changements subits par la banane au fil du temps, alors que ce qui fait d'une banane un objet est tout ce qui ne change pas. Figer le temps figerait aussi l'événement d'être une banane.
Fonctions est un terme utilisé par quelques lojbanistes pour décrire un groupe de types. Toutes les fonctions sont des concepts abstraits et comme tels n'ont pas vraiment d'existence indépendante dans le monde réel. Les tenants et les aboutissants des fonctions sont le sujet de la leçon trente; ici, nous nous concentrons sur leur seule sémantique. Il y a quelques types de fonctions :
Les selbri sont quelque chose avec lequel vous êtes déjà bien familiers. Cela décrit un acte de faire ou d'être. crino compris comme un selbri signifie « être vert » , darxi signifie « frapper » . Un selbri en soi est dépourvu du sumti qui est ou fait ce selbri. De ce fait, ils sont distincts de n'importe quel exemple particulier d'être vert ou de frappe et peuvent donc être compris comme une sorte d'événement générique. Ils sont utilisés pour des phrases dans lesquelles aucun exemple particulier d'application de ce selbri ne vient à l'esprit. Par exemple, si j'attend avec impatience mon mariage mercredi prochain, je pense à un événement situé dans l'espace et le temps (même si le mariage n'advient jamais pour quelque triste raison), par contre, si je dis que j'aimerais bien me marier un jour, je désire l'acte du mariage, et par conséquent je désire le selbri ou plutôt que le selbri s'applique à moi.
Les quantités ont presque les mêmes propriétés grammaticales que les selbri, comme vous le verrez dans deux leçons. Néanmoins, d'un point de vue sémantique, ils sont assez différents. Une quantité est la mesure de combien quelque chose correspond à un selbri, ce qui est quelque chose de complètement différent du selbri lui-même Une quantité est une sorte de nombre, ou peut être représentée par un nombre, exact ou inexact, peu importe si ce qui est quantifiable est concrètement mesurable.
Il y a quelques désaccords quant à savoir si c'est correct d'utiliser une abstraction de quantité pour quantifier quelque chose qui est en principe non mesurable. Donc, la quantité du fait que je sois vert est certainement valide, puisque cela peut être mesuré,disons par une caméra numérique, mais parler de la quantité de mon amitié avec Bob peut ne pas être accepté philosophiquement. Un bon exemple qui montre la différence entre quantités et selbri, quand ils sont appliqués à un sumti spécifique est le suivante : « Je change dans la noirceur » : quand « noirceur » est considéré comme un selbri, cela veut dire que je passe d'être noir à ne pas être noir ou vice et versa. Quand « noirceur » est considérée comme une quantité, cela signifie que ma peau devient plus ou moins noire (comme cela se passe en hiver quand il y a peu de soleil).
Les concepts sont peut-être des fonctions ou n'en sont peut-être pas, selon à qui vous demandez. Leur position en tant qu'éventuelles fonctions est expliquée dans la leçon trente. Les concepts, contrairement aux selbri et aux quantités, ne peuvent pas être appliqués à un sumti. On ne peut pas parler de « correspondre à un concept » , comme on peut le faire de « correspondre à un selbri » ou pas, ou de la mesure de « correspondance à un selbri » . Un concept n'existe pas dans le monde réel. Un concept n'est même pas représenté dans le monde réel, comme des quantités ou des selbri peuvent l'être quand ils sont appliqués aux sumti. Un concept, disons « la guerre » , n'existe que dans la tête des gens et est compris comme la signification du mot « guerre » . Ainsi « l'amour » compris comme un concept est l'idée de ce qu'est l'amour, peu importe qui aime et qui est aimé.
Peut être qu'un exemple peut montrer la différence entre quantités, selbri et concepts :
Dans « j'aime aimer » et « j'aime être aimé » , nous parlons d'un selbri.
Dans la phrase « j'aime combien j'aime » , j'aime une quantité, et quand je dis « j'aime l'amour » je fais référence au concept de l'amour.
Le bridi est un type avec lequel vous êtes également familier. Un bridi n'est certainement pas une fonction, mais il entretien quelques relations avec les fonctions, comme nous le verrons plus tard. Les bridi eux-mêmes sont imaginaires; ils existent, non pas dans le monde réel, mais à l'intérieur des textes, le prochain type à expliquer. Cependant, les bridi ne sont pas composés des symboles spécifiques (quels qu'ils soient) utilisés pour les exprimer – comme les bridi sont imaginaires, différentes phrases peuvent exprimer le même bridi. Il se peut que les phrases soient dans des langues différentes, que l'ordre des mots change, ou que des mots différents soient utilisés pour faire référence à un même sumti. Ainsi mi do prami/mi prami do, « je t'aime » , mi ko prami et do mi prami (quand c'est dit par la personne à laquelle do fait référence dans la première phrase) font toutes référence au même bridi. Les bridi ont toujours tous leurs emplacements structurels remplis par quelque chose ayant une valeur non nulle.
Le concept de texte est étroitement lié au concept de bridi. Tous les bridi sont contenus dans des textes, même si tous les textes ne contiennent pas de bridi. On pourrait d'ailleurs définir un texte comme quelque chose qui peut contenir un bridi, mais cela peut aisément conduire à des définitions circulaires quand on essaye de définir ce que sont les bridi. La compréhension courante des choses que l'on devrait considérer comme des textes est au mieux vague. Comme les bridi, les textes sont quelque chose d'éthéré, quelque chose dont on peut imaginer l'existence dans un domaine hors du monde physique. Même si ces leçons sont certainement un texte, le texte n'est pas fait du papier sur lequel ces leçons sont imprimées, ni des champs magnétiques qui constituent les octets sur lesquels elles sont stockées. Ces supports physiques ne font que représenter le texte. Mais qu'est-ce qui peut exactement représenter un texte ? Les mots, certainement. Mais qu'en est-il du langage corporel ? Et les actions disent-elles vraiment les textes plus fort que les mots ? Ce n'est pas un problème que je vais essayer de résoudre, ni même sur lequel je vais m'attarder dans ces leçons.
Les ensembles sont beaucoup plus faciles à traiter. Ils forment une sorte de méta-type : une boîte imaginaire, dans laquelle un groupe de sumti est emballé. Cette boite a très peu de choses à voir avec ce qui est à l'intérieur d'elle. Un grand ensemble ne signifie pas que les choses dans l'ensemble sont grandes, mais qu'il y a de nombreuses choses dans l'ensemble. Les ensembles ont très peu de propriétés, c'est pourquoi ils ne sont uniquement que quand on parle du nombre de choses dans une catégorie donnée, du nombre de choses partagées entre plusieurs catégories, des critères d'inclusion dans une catégorie, etc.
Le dernier type utilisé est la valeur de vérité. Je l'ai rarement vu utilisé, et je ne l'inclus ici que parce que ce sera pertinent quand on discutera d'une certaine abstraction dans la prochaine leçon. Une valeur de vérité est un certain jugement qui dit qu'un bridi est vrai, faux ou n'importe quoi entre les deux. La nature d'une valeur de vérité est un verdict, « vrai » , « faux » , « quasiment vrai » ou l'équivalent. Elle est souvent représentée par un chiffre, comme 0 (faux), 1 (vrai) ou 0.5 (à moitié vrai), mais c'est simplement une représentation de la valeur de vérité et non la valeur elle-même. On pourrait aussi bien la représenter par une couleur, échelonnée du rouge vers le bleu.
Leçons de lojban - Leçon vingt-neuf (sémantiques des abstractions simples)
Ayant acquis une terminologie appropriée pour la discussion concernant les types , nous pouvons maintenant plus facilement aborder la sémantique des abstractions. Le plus souvent, une abstraction est simplement un bridi considéré comme étant d'un certain type . Nous commençons par ce que je considère comme la plus simple des abstractions :
- nu = transforme un BRIDI en le selbri : x1 est l'événement BRIDI
Vous êtes déjà familiers avec ce mot et la façon dont il est utilisé. Une abstraction de type nu est toujours un événement, et en tant que tel, elle est située dans un temps et un espace particuliers. Ainsi :
mi catlu lo nu lo prenu cu darxi lo gerku - « J'observe une personne frappant un chien » est à proprement parler un événement, alors que
mi kakne lo nu bajra fi lo mi birka - « Je peux cours sur mes bras » est faux, parce qu'aucun événement particulier de course n'est impliqué : la course que vous êtes capable de faire est un selbri – un événement non spécifique et la phrase lojbane ci-dessus devrait sembler aussi mal tournée que sa traduction française.
Il y a beaucoup de façons de considérer un événement, et il y a donc quatre autres sucma'o, qui tous créent aussi des événements. Les significations de ces sucma'o sont toutes englobées par nu, mais sont plus spécifiques. Je les passerai toutes ici en revue :
- mu'e = transforme un BRIDI en le selbri : x1 est un événement ponctuel d'une occurrence de BRIDI
- za'i = transforme un BRIDI en le selbri : x1 est un état de BRIDI étant vrai
- pu'u = transforme un BRIDI en le selbri : x1 est le processus BRIDI se déroulant à travers les étapes x2
- zu'o = transforme un BRIDI en le selbri : x1 est l'activité BRIDI consistant en l'événement répété x2
La compréhension de ces sucma'o est soumise à la compréhension des contours d'événements. mu'e est apparenté au contour d'événement co'i dans le sens où les deux traitent le bridi comme ponctuel dans l'espace et le temps :
lo mu'e mi kanro binxo cu se djica mi – « moi devenant en bonne santé est désiré par moi » a la signification sémantique que le processus « devenir en bonne santé » n'est pas pris en considération. Si cela consiste en une douloureuse chimiothérapie, il est plausible que le processus ne soit pas désiré du tout. Cependant, « devenir en bonne santé » dans un sens ponctuel est désiré.
za'i est comme le contour d'événement ca'o dans le sens ou lo za'i BRIDI commence à s'appliquer quand le bridi commence et se termine brutalement dès que le bridi cesse d'être vrai, presque comme ca'o.
za'o za'i mi kanro binxo veut dire que l'état de moi devenant en bonne santé prend trop de temps; que le temps entre le début de l'amélioration de ma santé et être vraiment en bonne santé était interminable.
La traitement effectif est peut-être mieux saisi par pu'u, qui, comme les contours d'événement en général, met l'accent sur l'événement entier comme se déroulant dans le temps. .ii ba zi co’a pu’u mi kanro binxo .oi exprime la crainte que le processus douloureux de devenir en bonne santé est sur le point de commencer. Le x2 est rempli par une succession d'étapes, qui peut être réalisée en intercalant entre les étapes le connecteur non logique ce'o : ze’u pu’u mi kanro binxo kei lo nu mi facki ce’o lo nu mi jai tolsti ce’o lo nu mi renvi signifie « quelque chose est un long processus personnel de retour à la santé qui se réalise par les étapes suivantes: « A ) Je découvre B ) Quelque chose qui me concerne commence C ) Je subit. »
Finalement, la sémantique de zu'o traite l'abstraction comme consistant en un nombre d'actions répétées : lo za'a zo'u darxi lo tanxe cu rinka lo ca mu'e porpi – « l'activité observée de taper la boîte cause son actuelle fracturation » est plus précis que la phrase similaire utilisant nu, parce que zu'o rend explicite que c'est la répétition de l'action de taper et non un coup particulier, qui a cassé la boîte.
Le x2 de zu'o est soit un événement soit une séquence qui est répété. Pour être déraisonnablement explicite, nous aurions pu déclarer que la cause de l'état de destruction actuel était lo zo'u darxi lo tanxe kei lonu lafti lo grana kei ku ce'o lonu muvgau lo grana lo tanxe kei ku ce'o ...etc.
Notez la différence entre mu’e bajra, za’i bajra, pu’u bajra, zu’o bajra et nu bajra : l'événement ponctuel de la course met l'accent sur l'événement qui advient, et sur rien d'autre. L'état de course commence quand le coureur commence et s'arrête quand le coureur s'arrête. Le processus de la course consiste en un échauffement, le fait de garder un rythme constant et l'accélération finale. L'activité de la course se compose des cycles répétés : soulever un pied, le bouger vers l'avant, le laisser retomber, répéter avec l'autre pied. Tous ces aspects sont simultanément englobés par l'événement de courir nu bajra.
Un autre type de sucma'o est le sucma'o d'expérience, li'i.
- li'i = transforme un BRIDI en le selbri : x1 est l'expérience interne qu'a x2 de BRIDI
Une expérience peut être considérée comme un type d'événement Elle a presque les mêmes attributs : elle est située dans l'espace, l'accent est mis sur le temps pendant lequel elle se déroule, et ce n'est pas une fonction.
Cependant, à la différence des abstractions événementielles, une expérience est explicitement mentale – on ne peut pas dire qu'une abstraction li'i existe en-dehors de l'esprit d'une personne. Cette différence est purement sémantique, et échanger les sucma'o d'événement et d'expérience n'est pas considéré comme une erreur de typage dans le même sens que mi kakne lo nu…Cela pourrait ne pas faire sens, comme dans lo kacma cu vreji lo li'i lo mi pendo cu cliva kei mi - « Une caméra a enregistré mon expérience du départ de mon ami » . Mais une fois de plus, le cinéma dépend de la capacité des caméras à saisir les émotions des acteurs.
Cela fait, je pense, complètement sens d'écrire mi ciksi lo li'i lo mi pendo cu cliva kei mi, lo li'i lo mi tunba cu morsi cu mukti lo nu mi catra, et ainsi de suite.
li'i est dérivé de lifri, et est vraiment un se lifri – une expérience.
Une abstraction du'u est probablement l'autre sorte d'abstraction que vous avez l'habitude de voir, en plus de nu.
du'u: transforme un BRIDI en le selbri :x1 est BRIDI, comme représenté par le texte x2.
Selon la norme, les abstractions telles que les vérités, les mensonges, les choses découvertes ou les croyances sont toutes de purs bridi :
.ui sai zi facki lo du’u zi citka lo cidjrpitsa – « Oui ! Je viens de découvrir que de la pizza sera bientôt mangée ! »
mi krici lo du'u la turni cu zbasu pi ro lo munje zi'o - « Je crois que Dieu a créé tout l'univers »
Ce qui est découvert ou cru est la vérité d'un bridi abstrait, donc du'u est approprié.
Comme vous pouvez le voir à partir de la définition de du'u, le x2 de du'u est utilisé pour le texte dans lequel le bridi est contenu. Comme nous l'avons établi plus tôt, c'est dur de mettre le doigt sur la nature des textes, mais en pratique, le x2 de du'u peut être utilisé pour exprimer un discours indirect :
.ue do pu cusku ku'i lo se du'u do nelci lo ckafi – « Oh! Mais vous aviez dit que vous aimiez le café ! »
Par obligation, cette leçon inclura le sucma'o de valeur de vérité, jei. Voyons la définition
- jei = transforme un BRIDI en le selbri : x1 est la valeur de vérité de BRIDI selon l'épistémologie x2
jei est rarement utilisé, non parce que les abstractions de vérité sont rarement nécessaires, mais parce que la plupart des lojbanistes utilisent d'autres mécanismes pour obtenir le même résultat. jei n'est réellement utile que quand une valeur de vérité qui n'est pas "vrai" ou "faux" est nécessaire, c'est à dire pratiquement jamais. Je vais donner quelques exemples :
mi di'i pensi lo jei mi merko - « Je pense souvent au fait que je sois américain ou non » (s'oppose à « Je pense souvent à combien je suis américain » qui utilise une abstraction de quantité et non une valeur de vérité)
li pi bi jei la .tinjin. cu mikce - « c'est vrai à 80% que Tinjin est un docteur » (quoi que ça puisse vouloir dire).
Pour conclure cette leçon, le sucma'o su'u est un sucma'o universel, dont le x2 peut être utilisé pour préciser comment l'abstraction doit être considérée. Par exemple, de quel type est l'abstraction. Il a déjà été défini, mais nous pouvons aussi bien recommencer :
- su'u = transforme un BRIDI en le selbri : x1 est l'abstraction BRIDI considérée comme x2 / x1 est l'abstraction BRIDI de type x2.
L'idée de cette abstraction est simple, donc je vais juste donner quelques exemples de son usage et en rester là.
La phrase française « que je t'aime » est assurément un sumti, puisqu'il doit fonctionner comme un sujet ou comme un objet dans une phrase. C'est aussi clairement tiré d'une abstraction. Cela peut donc se traduire par : lo su'u mi do prami. Cependant, sans le contexte de la phrase française, il est dur de deviner de quel genre d'abstraction il peut s'agir. « Je mourrai heureux du moment que je t'aime » traite l'abstraction comme un événement arrivant dans le temps. « La vérité c'est que je t'aime. » traite l'abstraction comme un bridi, qui peut être considéré comme vrai ou faux. « Tu ne sais pas combien je t'aime » traite l'abstraction (presque la même) comme une quantité. En utilisant le second emplacement de sumti de su'u, elles peuvent être explicitement distinguées les unes des autres :
lo su’u mi do prami kei be lo fasnu est un événement.
lo su’u mi do prami kei be lo bridi est un bridi.
lo su’u mi do prami kei be lo klani est une quantité.
En utilisant su'u de cette façon, on peut couvrir l'étendue sémantique (mais pas grammaticale) de tous les sucma'o. Cependant, généralement on utilise d'autres sucma'o.
Finalement, le lojbaniste J. Cowan traduit le titre du livre « La Passion considérée comme une course de côte » par lo su'u la .iecuas. kuctai selcatra be lo sa'ordzifa'a ke nalmatma'e sutyterjvi.
Leçon de lojban - Leçon trente (sémantique des fonctions)
Les fonctions sont un groupe de deux ou trois types d'abstractions. L'expression n'est pas officielle, mais je vais l' employer ici de toute façon.
La définition des fonctions est étroitement liée au petit mot ce'u. ce'u est un sumka'i qui remplit un emplacement de sumti. Il n'est utilisé qu'à l'intérieur d'abstractions qui sont aussi des fonctions. Toutes les fonctions peuvent avoir au moins un ce'u quelque part dans l'abstraction - c'est ce qui en fait des fonctions. Le ce'u peut être élidé, auquel cas on suppose généralement qu'il occupe le premier emplacement de sumti élidé de la fonction, à moins que le contexte ne fournisse une alternative plus raisonnable.
Que fait-il réellement? Regardons sa définition :
- ce'u = pseudo quantificateur liant une variable à l'intérieur d'une abstraction qui représente un emplacement ouvert.
Bien, ce n'est pas très clair, essayons une autre approche.
Mettre ce'u dans un emplacement de sumti laisse l'emplacement de sumti vide. L'emplacement n'est pas effacé, comme si vous l'occupiez avec zi'o, mais l'emplacement n'est occupé par rien – pas une chose spécifique, pas un zu'i, pas un zo'e, rien. De cette manière, les emplacements de sumti vides rappellent les x1, x2 et x3 que nous mettons dans les emplacements de sumti des définitions anglaises de brivla – indiquant « c'est là que quelque chose d'autre peut être mis » .
Ainsi mi citka lo ti badna est « je mange cette banane » mais mi citka ce'u est « je mange X » .
Bien sûr, « je mange X » est vide de sens à moins qu'une valeur soit attribuée à la variable X, et en effet la phrase mi citka ce'u est tout aussi absurde en lojban.
Pour le voir à l'œuvre, nous avons besoin d'une abstraction de fonction. Nous allons commencer par le plus souvent utilisé: l'abstraction de selbri ka Voyons sa définition officielle :
- ka = abstracteur de propriété/qualité (- suffixe de qualité); x1 est la qualité/propriété exposée par BRIDI.
Selon la conception que je veux enseigner, cette définition induit légèrement en erreur. A la place ka pourrait probablement être défini de la façon suivante :
- ka = abstracteur de prédicat/selbri: x1 est le prédicat/selbri de BRIDI (nécessite au moins une variable ouverte c'est à dire un « ce'u »)
Utiliser une abstraction de selbri, « Je mange X » peut être faire sens, comme dans l'exemple suivant : {gl|ckaji| x1 est caractérisé par le selbri x2}}
lo ti badna cu ckaji lo ka mi citka ce'u – « Cette banane est caractérisée par le selbri : » « Je mange X », qui peut être reformulé : « Cette banane vérifie le selbri : » Être mangé par moi », qui est bien sûr équivalent à mi citka lo ti badna - « Je mange cette banane ».
Pour que l'affirmation ait du sens, l'emplacement de sumti laissé ouvert généralement, mais pas toujours, par ce'u ,doit être occupé par quelque chose. Le selbri principal de la proposition, dans ce cas ckaji, nous donne un indice sur la façon d'occuper l'emplacement de sumti ouvert. Un tel selbri le remplit presque toujours avec un sumti du selbri principal. Comment ce'u reçoit valeur non nulle a été un sujet de débat mineur au lojbanistan, mais le problème en est plus ou moins réglé : ce'u garde un emplacement de sumti ouvert, c'est le selbri principal qui le remplit ensuite avec quelque chose, et ce qui occupe l'emplacement dépend du selbri en question.
Bien que ce soit souvent le cas, l'emplacement du ce'u ne nécessite pas toujours d'être rempli par le selbri pour que l'abstraction soit sensée : Seul, lo ka ce'u te vecnu lo finpe signifie: « l'achat d'un poisson » ou « acheter un poisson » . Ceci peut être utilisé dans une phrase sans que le selbri ne remplisse le ce'u interne :
lo se lisri cu srana lo ka ce'u te vecnu lo finpe - « L'intrigue concerne l'achat d'un poisson » . Ici, srana n'applique rien du tout à l'emplacement ce'u, et l'abstraction est plutôt vue comme le selbri en lui-même.
Une autre manière d'expliquer ce'u est de regarder le mot comme représentant des variables dans une lambda-fonction par exemple, examinons cette phrase :
| la .alis. cu djica lo ka ce'u te vecnu lo finpe Alice veut acheter un poisson. |
Ici le premier argument de djica est celui qui veut quelque chose, à savoir Alice. Le second argument est le selbri qu'Alice veut accomplir : l'achat d'un poisson.
Nous pouvons voir ce'u comme une variable libre, qui devient alors lié par une lambda-abstraction, à savoir ka. Maintenant, ka ce'u terve'u lo finpe peut être vu comme une lambda-fonction :
\ x -> te vecnu(x,lo finpe,zo'e,zo'e),
et dans ce cas djica fournit la lambda-fonction avec Alice.
Les lambda peuvent être stockés, en prévoyant qu'ils peuvent être transférés et utilisés dans des situations variées :
| ca'e ko'a ka ce'u dansu .i mi ko'a ckaji .i do ko'a djica .i ma'a ko'a kakne Il danse. Je le fais. Vous le voulez. Tout le monde peut le faire. |
Maintenant, en utilisant ka, vous pouvez correctement formuler « Je peux courir sur mes bras » . Comment?
Réponse : mi kakne lo ka {ce'u} bajra fi lo mi birka
La plupart des gismu les plus utilisés prennent le selbri comme l'un de leur sumti, ce qui signifie que lo ka est utilisé assez souvent. Quelques exemples remarquables sont troci, kakne, djica, zukte, snada et fraxu :
| lo xasli na’e kakne lo ka silcu la'e la'oi X-Files L'âne ne peut pas siffler la chanson de aux frontières du réel. |
| e'o ko lo jai se zgike cu fraxu lo ka darxi lo damri ca lo nu do sipna S'il vous plait, pardonnez aux musiciens de frapper sur le tambour quand vous êtes en train de dormir. |
Il y a au moins un selbri qui peut remplir deux ce'u dans une abstraction ka, à savoir simxu. Que signifie le jufra suivant?
mi lo pampe'o cu simxu lo ka {ce'u ce'u} gletu
Réponse: moi et mon amant avons mutuellement des relations sexuelles l'un avec l'autre.
Bien sûr, le ce'u n'a pas besoin d'être placé au début de l'abstraction ka, même si c'est par défaut. On peut très bien parler de :
| lo ka la .bab. melbi ce'u Bob est beau d'après X, ou en d'autres termes « penser que Bob est beau » . |
En effet déplacer le ce'u dans une fonction crée des sens très différents :
| lo ka ce'u panze la . maik. Le selbri « X est un enfant de Mike », « Être l'enfant de Mike », |
versus
| lo ka la .maik. panzi ce'u Le selbri « Mike est un enfant de X », « Être le parent de Mike ». |
On peut même imaginer une affirmation dans laquelle le ce'u est placé à un endroit très non conventionnel, qui est néanmoins tout à fait intuitif :
mi .e nai do ckaji lo ka lo bruna cu jbocre, dans lequel le ce'u est élidé, mais plus probablement caché dans lo bruna be ce'u, donc signifiant « Moi et pas toi suis caractérisé par le selbri : « Le frère de X est bon en lojban » » , qui est la même chose que « J'ai un frère qui est bon en lojban, mais pas toi ».
On peut faire une fonction, comme une abstraction ka, et occuper tous les emplacements de sumti, ne laissant aucune place pour un ce'u. Les bridi qui en découlent sont bizarres :
| mi kakne lo ka mi merko lo mi bangu Je peux ma langue est l'américain. |
Il s'agit clairement d'une erreur de type. Certaines personnes considèrent les fonctions dépourvues de ce'u comme étant équivalentes aux abstractions de bridi, si bien que :
mi krici lo ka mi vrude la cevni est la même chose que mi krici lo du'u mi vrude la cevni – « je crois que je suis bon aux yeux de Dieu » ,et c'est juste une aussi bonne phrase en lojban que sa traduction en français. Selon moi, il faudrait s'abstenir d'utiliser quelque abstracteur de fonction que ce soit si on ne veut pas utiliser une fonction. Si vous voulez dire du'u, utilisez du'u.
L'autre abstracteur qui peut clairement pourvoir une fonction est ni. Comme ka, un ce'u peut être placé dans une abstraction ni, mais contrairement à ka, utiliser un ce'u avec ni n'est pas obligatoire. Par conséquent, si aucun ce'u n'est placé dans une abstraction ni, on ne peut pas partir du principe qu'il est élidé – il pourrait simplement ne pas être là. Si le selbri principal n'est pas de ceux qui nous disent clairement comment occuper l'emplacement d'un ce'u, comme zmadu ou mleca, il n'y a probablement pas de ce'u du tout.
Dans tous les autres aspects, la façon dont ce'u fonctionne dans l'abstraction est exactement comme ka, donc la différence est purement sémantique. Là où ka crée un selbri, ni crée une quantité. Voici la définition du mot :
- ni = abstraction de quantité : x1 est la quantité de BRIDI sur l'échelle x2.
Étant familiarisé avec ka, l'utilisation de ni devrait être simple :
| mi zmadu do lo ni {ce'u} xekri Je te dépasse en quantité « X est noir » , ou : Je suis plus noir que toi. |
Comme cela a été dit dans la leçon vingt-huit, tout le monde s'accorde à dire que c'est totalement sensé car la clarté de la peau peut être mesurée par une caméra. Cependant certaines personnes n'acceptent pas ce qui n'est pas mesurable.
| mi zmadu do lo ni mi pendo la .maik. Je suis plus ami avec Mike que vous ne l'êtes. |
Je pense qu'utiliser les quantités pour quantifier le non mesurable est bien, mais c'est un problème que j'ai mis sous le tapis il y a deux leçons, et je ne vais pas la traiter ici.
Cependant, c'est absolument clair que c'est erroné d'utiliser ni comme une façon d'énumérer combien d'objets occupent un selbri – c'est toujours à propos de l'importance avec laquelle certains sumti s'accordent à un selbri. Ainsi :
do mleca mi lo ni panzi ce'u signifie « Vous êtes moins parent que moi », et non « Vous avez moins d'enfants que moi » .
Au cas où vous soyez curieux (je l'étais), le jufra zo'e panzi ce'u dans l'exemple précédent fait vraiment référence à deux bridi distincts, car le selbri occupe l'emplacement de ce'u ouvert deux fois, une fois pour do, et une fois pour mi, faisant les deux sous-bridi : zo'e panzi do et zo'e panzi mi. Comme ces deux bridi sont considérés indépendants l'un de l'autre, il n'est pas nécessaire que le zo'e fasse référence au même objet.
Qu'est-ce que cela signifie si vous n'utilisez pas un ce'u à l'intérieur d'une abstraction ni? Eh bien, à ce moment là le selbri principal ne peut remplir aucun des sumti dans l'abstraction, donc quand on utilise des selbri comme zmaduet mleca, il y a une bonne probabilité que cela n'ait aucun sens. Cependant, si ni lui-même est le selbri principal, c'est tout à fait bien de n'utiliser aucun ce'u du tout:
| li du'e ni do nelci lo vanju Tu aimes trop le vin. |
Le dernier des abstracteurs que nous traitons dans cette leçon est si'o l'abstracteur de concept. si'o peut être considéré comme une fonction, ou pas. Une abstraction si'o contient certainement un ce'u – en fait, selon la conception que j'enseigne, une abstraction si'o ne contient toujours rien d'autre que des ce'u ! Ces ce'u, contrairement à ceux de ka et de ni, restent ouverts et ne peuvent pas être occupés par aucun selbri. En d'autres termes, la fonction ne peut pas être appliquée à n'importe quoi, ce qui en fait une fonction peut-être.
- si'o = abstracteur de concept : x1 est le concept x2 de BRIDI.
Prenons quelques exemples :
lo si'o xebni, qui, parce que tous les emplacements de sumti sont occupés par ce'u, est équivalent à :
| lo si'o ce'u xebni ce'u |
Les Balrog, créatures mythiques du « Seigneur des Anneaux» sont décrites comme étant « ombre et flamme » , en lojban c'est encore plus poétique : la balrog cu si'o fagri joi manku affirme non seulement qu'ils sont faits d'ombre et de flamme, mais suggère aussi qu'ils sont les prototypes de l'Ombre et de la Flamme, desquels proviennent toutes les autres ombres et flammes.
Pour faire bonne mesure, il convient de préciser qu'étymologiquement, si'o provient de sidbo, « idée » , mais dans l'usage courant, une idée est considérée comme un texte et non comme un concept.
La différence entre les trois abstracteurs ka, ni et si'o peut être illustrée par quelques exemples à titre de comparaison :
| lo ka crino cu pluka mi Être vert me fait plaisir. |
| lo ni crino cu pluka mi A quel point {zo'e} est vert me fait plaisir (pas de ce'u!). |
| lo si'o crino cu pluka mi Le fait d'être vert me plait. |
| mi nitcu lo ka sipna ku lo ka kanro J'ai besoin de dormir pour être en bonne santé. |
| mi nitcu lo si'o sipna lo ka tavla fi lo sipna J'ai besoin du concept de dormir pour parler des choses du sommeil. |
Et j'ai été tenté d'écrire mi nitcu lo ni sipna ku lo ka vreji ri - « J'ai besoin de la quantité de combien {zo'e} dort », mais cela n'a pas l'air d'avoir beaucoup de sens.
Leçons de lojban - Leçons trente-et-un (divers mots pas si jolis)
Oui, encore une leçon qui traite de mots divers. Cette fois, cependant, le contenu de la leçon n'est pas choisi par l'usage courant : Contrairement à des mots comme jai et si, la plupart des mots suivants sont peu utilisés dans la conversation ordinaire. Cependant certains sont importants pour la compréhension des leçons suivantes, et donc ces mots vont devoir être affreusement exposés avant leur utilisation dans ces leçons.
Avant de s'aventurer dans des mots obscurs, il y a un mot qui je pense, mérite une explication plus approfondie que celle que l'on a donné jusqu'à présent : kau.
kau a été expliqué dans la leçon 12, mais pas ses réelles implications. Si vous avez oublié ce que cela veut dire, je vous conseille d'y retourner voir. Je ne peux malheureusement pas présenter une théorie sur l'action de kau quand il est présent dans le bridi principal, juste sur son action à l'intérieur d'une abstraction.
Un bridi dont une abstraction contient un kau contient deux proposition : le bridi lui-même est une proposition comme d'habitude, et, de plus, implicitement dans l'abstraction,la proposition que le mot auquel kau est attaché a une signification réelle, non nulle.
Il convient de le démontrer le bridi :
| mi pu viska lo nu ma kau cliva le salci J'ai vu qui a quitté la soirée |
contient deux propositions. Premièrement, il comporte une affirmation implicite selon laquelle le ma se rapporte à quelque chose de réel. C'est-à-dire que le bridi affirme vraiment que da cliva le salci (X a quitté la soirée). Deuxièmement, le bridi principal contient l'affirmation selon laquelle ce à quoi ma fait référence est ce qui a été vu, soit en lojban mi pu viska lo nu da cliva de salci. (J'ai vu que X a quitté la soirée).
Ce principe ne se limite pas à l'abstracteur nu, ou au mot de question ma. Le même principe peut être étendu à n'importe quel autre abstracteur et à n'importe quel autre mot de question comme dans le bridi suivant :
| la .bab. na'e birti lo du'u xu kau la .mias pampe'o Bob ne sait pas avec certitude si oui ou non Mia a un petit ami |
indique tout d'abord que xu s'applique, ce qui signifie qu'une valeur de vérité peut être affectée au bridi, et deuxièmement que ce dont Bob n'est pas sûr est la valeur de vérité correcte pour le bridi.
kau peut aussi être appliqué à un mot de non-question. Ceci ne change pas vraiment le sens du mot. La même procédure s'applique encore:
| do ca'o djuno lo du'u la krestcen kau cu cinba la an vous savez déjà que c'est Christian qui a embrassé Anne. |
Indique tout d'abord que la krestcen cu cinba la an et puis que do ca'o djuno lodu'u la krestcen cu cinba la an
Allons vers les mots plus obscurs, commençons par xi, c'est facile.
- xi = indice. Convertit n'importe quelle suite de nombre en un indice, qui a la grammaire d'attitude (c'est-à-dire plaçable pratiquement n'importe où)
Il y a quelques utilisations officiellement encouragées de xi, mais précisément parce que la construction de xi + nombre a la grammaire libre d'attitude, les utilisations possibles de xi sont presque infinies. En général, il est utilisé pour énumérer n'importe quel mot, variable ou grammaticalement construit, à l'opposé de ce à quoi il fait référence. Voyons quelques exemples :
| la tsani cu cusku zo coi .i ba bo la .triliyn. cu cusku lu .ui coi la tsani coi la klaku li'u .i ba bo la klaku cu spusku fi lu coi ty. xi pa .e ty. xi re do'u zo'o li'u Tsani a dit « Salut » alors Triliyn a dit « He Tsani, he Klaku » , alors Klaku a répondu « Bonjour T1 et T2 : P » . |
- spusku = x1 répond x2 (texte) à x3
Parce que c'est la norme que ty fasse référence au dernier sumti qui commence par T, ty isolément, dit par Klaku, aurait fait référence à Tsani. deux différents ty. peuvent être indiqués en indiçant avec xi.
Si dans de rares situations il arrive que nous ayons besoin de plus de variables du type da ou bu'a qu'il n'y en a dans la langue, un nombre infini peut être créé en indiçant simplement n'importe lequel existant avec un nombre. Notez qu'une variable non indicée n'est pas définie comme étant équivalente à n'importe quelle autre qui est indicée. C'est-à-dire ty n'est pas toujours équivalent à ty xi pa ou ty xi no ou quoi que ce soit de ce genre. Je suppose que c'est rarement utilisé, car il serait dur de garder le fil de n'importe quelle phrase comprenant plus de trois mots du genre de da ou plus de dix mots du genre de ko'a.
Deuxièmement, nous avons ki, pour lequel je n'ai pas vu d'utilisation intense au cours du temps passé sur IRC, probablement pas parce que c'est un mot inutile, mais car peu de textes lojban sont d'une sorte qui en nécessite l'usage.
- ki = temps adhésif. Mettez/utilisez le temps par défaut; établit une base de référence d'un nouveau champ ouvert espace/temps/modal.
Tous les mots de rang de temps peuvent être suffixés avec ki pour faire que le(s) temps s'applique(nt) à tous les bridi suivants. Quand, par exemple, on raconte une histoire, cela peut être utilisé pour rendre explicite que le temps par défaut – le temps signifié en l'absence de mots de temps – est le temps dans lequel l'histoire se passe. Habituellement ce ne sera pas nécessaire, en commençant un conte de fée avec pu zu vu ku, on peut supposer que l'histoire entière se passe il y a longtemps et loin. Prenons un exemple :
| pu zu vu ki ku zasti fa lo pukclite je cmalu nixli goi ko’a .i ro da poi pu zu vu viska ko’a cu nelci ko’a Il était une fois une adorable petite fille. Chaque personne qui la voyait l'aimait. |
Le ki nous permet d'élider les trois temps dans le second bridi et tous les bridi suivants.
Donc, si un groupe de temps a été scotché avec ki, comment peut-on le déscotcher? Utilisez simplement ki seul, et tous les temps scotchés sont déscotchés.
Enfin, plusieurs ensembles de temps peuvent être scotchés en indiçant ki. S'il y a plusieurs de ce genre d'ensembles utilisés à tout moment, on peut utiliser l'indiçage par ki pour établir la correspondance entre les ensembles de temps. Seul le désindiçage de ki annule le scotchage de tous les temps, donc vous devez faire attention de ne pas utiliser le désindiçage de ki si vous prévoyez d'utiliser plusieurs ensembles de temps.
Changement de sujet Il y a un ensemble de sumtcita qui sont souvent utilisés, mais que je n'ose essayer de définir que sous l'avertissement de la troisième partie. Voyons les définitions officielles de deux d'entre eux en premier.
- ca'a = aspect modal : événement actuel/en cours. Bridi est arrivé/arrive/arrivera pendant et selon les circonstances de {sumti}.
- ka'e = aspect modal : capacité innée, peut être non réalisée. Bridi est possible selon les circonstances de {sumti}.
Voyons la première différence entre ca'a et ka'e. ka'e signifie que le bridi est « possible si l'événement de SUMTI est arrivé/arrive/arrivera » . ca'a en revanche, signifie que le bridi « est arrivé/arrive/arrivera si l'événement de SUMTI est arrivé/arrive/arrivera » .
Comme tous les sumtcita, leur sumti correspondant peut être élidé si le sumtcita est placé avant le selbri :
| le vi sovda ka'e fulta .i ja'o bo ri fusra Cet œuf flotte. Donc il est pourri. |
En utilisant ka'e, cette phrase n'établit pas que l'œuf a flotté, ou flottera jamais, mais plutôt qu'il pourrait flotter.
- pu'i = aspect modal : peut et a; potentiel démontré. Bridi peut ou peut ne pas arriver, mais dans les faits il est arrivé/arrive/arrivera selon les circonstances de {sumti}.
- nu'o = aspect modal : peut mais n'a pas, potentiel non réalisé.
Une fois compris ka'e et ca'a, nu'o signifie simplement ka'e je na ku ca'a, et pu'i signifie ca'a je ka'e na ku.
Historiquement, ces quatre mots étaient des sumtcita de temps – d'où l'aspect modal dans leurs définitions. Tous les sumtcita de temps n'ont alors pas été considérés comme des sumtcita à part entière, mais plutôt comme des selbri tcita. Une interprétation moderne du lojban devient de plus en plus populaire, selon laquelle les sumtcita de temps sont considérés comme des sumtcita, presque exactement comme le BAI, et dans laquelle les selbri tcita ne sont pas utilisés.
Parce que selon l'histoire de ces quatre mots en tant que selbri tcita, ils peuvent être librement élidés – en effet, puisqu'un des quatre mots s'applique toujours, on suppose toujours l'élision. C'est le plus souvent ca'a. En effet, c'est si souvent ca'a que l'on pourrait se demander pourquoi ca'a n'est pas par défaut.
Une raison est qu'un certain selbri a deux définitions utiles, l'une qui implique ka'e SELBRI et l'autre ca'a SELBRI. Par exemple, voyons fasnu qui peut signifier "X se produit" ou "X est un événement", pour lequel le premier sens implique ca'a fasnu et le second ka'e fasnu.
Une autre utilisation de ka'e « implicite » correspond à un moyen d'échapper à un ennuyeux problème philosophique inhérent à la langue. Un selbri s'applique seulement si tous ses emplacements s'appliquent aussi. Pour certains selbri, comme kabri, c'est un problème.
- kabri = x1 est une coupe recelant des contenus x2 et fait de la matière x3.
La définition suggère que si le contenu de la coupe est enlevé, le x2 ne s'applique pas plus longtemps et il cesse d'être lo kabri. Si cela implique ka'e ou de façon plus pertinente, nu'o, nous éviterons la question.